Аннотация.
Статья посвящена анализу дополнительных возможностей автоматизации функционального тестирования Web-приложений на основе технологии UniTesK. В ней рассматриваются существующие подходы к автоматизации функционального тестирования Web-приложений, обсуждаются их достоинства и недостатки. Кроме того, анализируются возможные варианты применения технологии UniTesK для тестирования данного класса приложений, и предлагается способ дополнительной инструментальной поддержки процесса разработки функциональных тестов.
Дополнительная инструментальная поддержка
Основной задачей, возлагаемой на инструментальную поддержку, является упрощение работы пользователя по созданию компонентов тестовой системы. Это достигается за счет дополнительной автоматизации шагов технологического процесса UniTesK с учетом специфики Web-приложений. Первый шаг технологического процесса UniTesK – анализ функциональности тестируемой системы – не предполагает инструментальной поддержки, однако для Web-приложений можно предложить способ выделения интерфейсных функций на основе автоматизированного анализа интерфейса Web-приложения. На шаге формализации требований пользователь может описывать требования в виде условий на различные атрибуты элементов интерфейса; эти условия могут строиться с использованием поддержки инструмента. Информации, собранной при автоматизации первого и второго шагов, оказывается достаточно для автоматического связывания интерфейсных функций с Web-приложением. Для шага разработки тестовых сценариев предлагаются дополнительные возможности по описанию его компонентов в терминах интерфейса Web-приложения. Последний шаг не требует дополнительной автоматизации, так как все инструменты семейства UniTesK уже предоставляют развитые средства выполнения тестов и анализа их результатов.
При использовании дополнительной инструментальной поддержки процесс разработки тестов для функционального тестирования Web-приложений изменяется и состоит из следующих шагов:
(1) создание модели Web-приложения;
(2) создание тестового сценария;
(3) выполнение тестов и анализ результатов.
Первый шаг – создание модели Web-приложения – включает в себя определение интерфейсных функций, описание требований к ним и их связывание с Web-приложением, т.е. объединяет первые три шага технологии UniTesK. Основная задача этого шага – формализация требований к интерфейсным функциям – в отличие от второго шага технологии UniTesK может быть частично автоматизирована, а выделение интерфейсных функций и их связывание с Web-приложением происходит автоматически. Два последних шага соответствуют двум последним шагам технологии UniTesK и отличаются только уровнем автоматизации.
Рассмотрим более подробно перечисленные выше шаги.
На первом шаге должно быть получено описание модели, состоящее из набора интерфейсных функций и описания требований к ним.
Интерфейсная функция соответствует воздействию на интерфейс Web-приложения, в результате которого происходит обращение к серверу. Элементы интерфейса, влияющие на параметры этого обращения, включаются в список параметров интерфейсной функции. Результатом воздействия является обновление интерфейса, которое описывается в требованиях к интерфейсной функции. Например, для HTML-формы регистрации можно описать интерфейсную функцию, соответствующую отправке данных формы на сервер, параметрами которой являются значения полей, входящих в форму. В описание требований включается информация о значениях, для которых успешно выполняется регистрация, и описываются ограничения на состояние обновленного интерфейса. Разбиение множества всех возможных состояний интерфейса Web-приложений на классы эквивалентности представляется в модели набором страниц. Это разбиение, которое, с одной стороны, используется при описании требований, с другой стороны, является основой для определения состояния в сценарии. По умолчанию разбиение на страницы осуществляется по адресу (URL) HTML-документа, отображаемого в Web-браузере. Однако пользователь может переопределить разбиение произвольным образом. При традиционном способе построения Web-приложения, когда для каждого URL определяется его собственный интерфейс, разбиение по умолчанию соответствует представлению пользователя о тестировании Web-приложения – пройти все страницы и проверить всю возможную функциональность на каждой из них. Также естественным для пользователя требованием к Web-приложению является требование перехода с одной страницы на другую в результате активизации гиперссылки или нажатия на кнопку HTML-формы. Такие требования легко описываются с помощью понятия страниц. В более сложных случаях, например, для описания требования к результату работы HTML-формы поиска по некоторому критерию, требования формулируются в виде условий на атрибуты элементов интерфейса.
Автоматизация построения модели поддерживается в процессе сеанса работы с тестируемым Web-приложением.
Пользователь осуществляет навигацию по страницам приложения, редактируя список интерфейсных функций и их параметров, который автоматически предлагается инструментом, и добавляет описания требований, формулируя их в виде проверки некоторых условий на атрибуты элементов интерфейса. Для формулировки проверок инструмент предоставляет возможность выделения интерфейсных элементов и задания условий на их атрибуты. В результате этого шага инструмент создает из модели Web-приложения компоненты тестового набора UniTesK, обычно появляющиеся на первых трех шагах технологии – это спецификационные классы, описывающие интерфейсные функции, и медиаторные классы, реализующие связь между интерфейсными функциями и тестируемой системой. В спецификационных классах для каждой интерфейсной функции создаются спецификационные методы, в которых описываются требования к поведению функций, сформулированные при работе инструмента. Для этого используются предусловия и постусловия спецификационных методов. В том случае, если средств, предоставляемых инструментом, недостаточно для описания функциональности Web-приложения, полученные спецификационные классы могут быть доработаны вручную. В медиаторных классах описывается связь между спецификацией и тестируемой системой. Для каждого спецификационного метода задается медиаторный метод, который преобразует вызов этого спецификационного метода в соответствующее воздействие на интерфейс Web-приложения. Это преобразование осуществляется следующим образом. Для каждого параметра спецификационного метода медиатор находит соответствующий ему элемент интерфейса Web-приложения и устанавливает значение его атрибутов в соответствии со значением параметра. Затем медиатор осуществляет воздействие требуемого типа на элемент интерфейса, соответствующий данной интерфейсной функции, и ожидает реакции Web-приложения. Как правило, реакция на воздействие заключается в обращении Web-браузера к Web-серверу и получении от него нового описания интерфейса. Медиатор дожидается завершения обновления состояния интерфейса и синхронизирует состояние модели. На втором шаге нужно получить описание тестов для Web-приложения.
При создании тестов используется подход, предлагаемый технологией UniTesK. Согласно этому подходу тесты описываются в виде тестовых сценариев, в основе которых лежит алгоритм обхода графа переходов конечного автомата. Для каждого тестового сценария нужно выбрать подмножество интерфейсных функций, для тестирования которых предназначен данный сценарий. Для каждой выбранной функции нужно задать правила, по которым будут перебираться ее параметры. Кроме того, нужно задать правила идентификации состояний тестового сценария. Для автоматизации процесса создания тестового сценария предоставляется возможность определять итерацию для параметров выбранных интерфейсных функций на основе готовых вариантов перебора. Для этого могут использоваться библиотечные итераторы и итераторы, разработанные пользователем. Данные, которые вводились в ходе сеанса работы с инструментом на первом шаге, также могут быть включены в качестве дополнительных значений для заданной итерации. Кроме того, инструмент может предложить перебор параметров, построенный на основе анализа интерфейса Web-приложения. Например, использовать для итерации значения элементов выпадающего списка или же значения, которые берутся из разных интерфейсных элементов, например, расположенных в столбце некоторой таблицы. Для решения другой задачи, связанной с определением состояния тестового сценария, инструмент предоставляет средства для описания этого состояния в терминах интерфейса Web-приложения. В качестве состояния по умолчанию инструмент предлагает использовать страницу HTML-документа. Для более детального разбиения пользователю предоставляется возможность уточнить описание состояния, выбрав элементы интерфейса и указав условия на их атрибуты или на наличие этих элементов в интерфейсе. Кроме того, для описания состояния можно пользоваться описанием состояния сервера. Следует заметить, что информации, собранной на шаге построения модели Web-приложения, уже достаточно для создания тестового сценария. При создании тестового сценария по умолчанию используются все выделенные интерфейсные функции, для итерации параметров которых используются итераторы по умолчанию и значения, введенные пользователем в ходе сеанса построения модели, а в качестве состояния сценария используется страница HTML-документа. В качестве альтернативного способа создания тестов для Web-приложения можно использовать подход Capture & Playback.
В процессе работы пользователя с Web- приложением инструмент записывает последовательность воздействий на интерфейс, на основе которой генерирует последовательность вызовов интерфейсных функций, соответствующую записанным воздействиям. Итак, по сравнению с базовым подходом UniTesK описанный подход обладает следующими преимуществами. Во-первых, уменьшается объем ручного труда за счет автоматизации действий, предписываемых технологией UniTesK. Во-вторых, снижаются требования к квалификации пользователей технологии, так как в этом подходе основным языком взаимодействия с пользователем является не язык программирования (или его расширение), а язык элементов интерфейса и воздействий на них. Следует заметить, что этот подход сохраняет большинство преимуществ технологии UniTesK – гибкую архитектуру тестового набора, обеспечивающую возможность повторного использования компонентов, автоматическую генерацию тестовых последовательностей.
Недостатком данного подхода является отсутствие возможности создания тестов до появления реализации, поскольку подход основан на использовании реализации для дополнительной автоматизации шагов технологии UniTesK. Однако наличия прототипа уже достаточно для начала процесса разработки тестов.
Функциональное тестирование Web-приложений на основе технологии UniTesK
А.А. Сортов, А.В. Хорошилов
Труды Института Системного Программирования РАН, 2004 г.
Литература
[1] D. Raggett, A. Le Hors, I. Jacobs. HTML 4.0 Specification. URL: http://www.w3.org/TR/html40
[2] http://solex.sourceforge.net
[3] http://www.segue.com
[4] http://www-306.ibm.com/software/awdtools/tester/robot
[5] http://www.mercury.com/us/products/quality-center/functional-testing/winrunner
[6] Shakil Ahmad. Advance Data Driven Techniques.
[7] Keith Zambelich. Totally Data-Driven Automated Testing. URL: http://www.sqa-test.com/w_paper1.html
[8] http://www.empirix.com
[9] Carl J. Nagle. Test Automation Frameworks. URL: http://safsdev.sourceforge.net/DataDrivenTestAutomationFrameworks.htm
[10] http://www.worksoft.com
[11] I.B. Bourdonov, A.S. Kossatchev, V.V. Kuliamin, A.K. Petrenko. UniTesK Test Suite Architecture. Proc. of FME 2002. LNCS 2391, pp. 77-88, Springer-Verlag, 2002.
[12] В.В. Кулямин, А.К. Петренко, А.С. Косачев, И.Б. Бурдонов. Подход UniTesK к разработке тестов. Программирование, 29(6):25–43, 2003.
[13] http://www.unitesk.com
[14] А.В. Баранцев, И.Б. Бурдонов, А.В. Демаков, С.В. Зеленов, А.С. Косачев, В.В. Кулямин, В.А. Омельченко, Н.В. Пакулин, А.К. Петренко, А.В. Хорошилов. Подход UniTesK к разработке тестов: достижения и перспективы. Труды Института системного программирования РАН, №5, 2004. URL: http://www.citforum.ru/SE/testing/unitesk
[15] Bertrand Meyer. Applying 'Design by Contract'. IEEE Computer, vol. 25, No. 10, October 1992, pp. 40-51.
Сноски:
Помимо HTML может использоваться XHTML, XML и др.
Кроме скриптовых возможностей существуют другие средства расширения функциональности, такие как технология ActiveX, Macromedia Flash и др., которые взаимодействуют с Web-приложением, используя свои собственные механизмы. В рамках данной статьи тестирование таких расширений не рассматривается.
Целевой системой мы будем называть программную систему, которая выступает в качестве объекта тестирования. Далее в качестве синонима для термина целевая система мы будем также использовать словосочетание тестируемая система.
Помимо HTML может использоваться XHTML, XML и др.
Моделирование без привязки к уровню взаимодействия
Третий вариант заключается в рассмотрении только функциональности Web-приложения и абстрагировании от того, каким образом эта функциональность предоставляется пользователю. В этом случае интерфейсным функциям соответствуют абстрактные действия, которые выделяются на основе требований к функциональности Web-приложения. Одной интерфейсной функции может соответствовать несколько последовательных обращений к серверу (например, авторизация, переход на нужную страницу, заполнение на ней полей формы и нажатие кнопки). Входные и выходные параметры функций также определяются на основе требований и могут быть не привязаны к интерфейсу Web-приложения. Результатом такого подхода являются качественные спецификации с удобным абстрактным интерфейсом, которые можно применять для тестирования на разных уровнях (на уровне EJB, посредством Web-браузера или HTTP-протокола). При этом вся работа по созданию таких спецификаций должна быть целиком возложена на разработчика тестов, поэтому требования к его квалификации в этом варианте значительно выше, чем в первых двух.
Поскольку интерфейсной функции соответствует некоторое абстрактное действие, которое отвечает некоторому варианту работы с Web-приложением, в этом подходе, как и во втором, возникает проблема автоматизации преобразований вызовов интерфейсных функций в обращения к Web-приложению. Эта проблема, так же как и в предыдущем варианте, может быть решена с использованием интерактивного режима работы. Как уже было замечено, спецификацию интерфейсных воздействий можно использовать для тестирования на разных уровнях, поэтому в результате работы пользователя в интерактивном режиме можно сразу получать преобразования в воздействия разных уровней. Интерфейсное воздействие может быть переведено в серию HTTP-запросов или же в последовательность обращений к элементам интерфейса Web-приложения.
При создании сценариев тестирования необходимо задавать перебор параметров интерфейсных функций и, при необходимости, указывать способ определения состояния для работы обходчика. Эти шаги для рассматриваемого варианта не обладают какой-либо спецификой и мало чем отличаются от шагов технологического процесса UniTesK при его традиционном применении.
Подведем итог. Третий вариант моделирования никак не ограничивает разработчика тестов при описании поведения и формализации требований к тестируемой системе. Получившиеся в результате компоненты тестовой системы можно использовать для тестирования на разных уровнях. На шаги технологии в этом подходе практически не влияет специфика Web-приложений, поэтому трудно предлагать какую-либо автоматизацию, за исключением шага связывания формализованных требований с реализацией, на котором разрабатываются медиаторы.
Моделирование на уровне Web-браузера
Во втором варианте в качестве интерфейса системы рассматривается интерфейс, предоставляемый Web-браузером. В этом варианте интерфейсным функциям соответствуют воздействия на активные элементы интерфейса, в результате которых происходит обращение к Web-приложению. Такими элементами можно считать гиперссылки, кнопки форм и элементы интерфейса, для которых определена обработка на клиентской стороне, приводящая к обращению к серверу. Входные параметры этих функций – это данные, которые может вводить пользователь, например, при заполнении полей ввода или выборе значений из выпадающих списков и т.д. Таким образом, если рассматривать HTML-форму, то нажатию на кнопку, по которой отправляются данные, будет соответствовать интерфейсная функция, параметрами которой являются значения полей этой формы.
Стоит оговориться, что в этом варианте в качестве тестируемой системы рассматривается Web-приложение в целом, включая как серверную, так и клиентскую часть. Однако внимание акцентируется на тестировании серверной части, и не ставится задача покрытия функциональности клиентской части.
В этом варианте считается, что выходные параметры интерфейсных функций отсутствуют, поскольку результат воздействия описывается как изменение состояния Web-приложения.
Состояние Web-приложения в этом варианте разбивается на состояние интерфейса, отображаемого Web-браузером, и состояние сервера. К состоянию интерфейса можно отнести текущую отображаемую страницу и состояние элементов на ней. К состоянию сервера относится, например, состояние базы данных, с которой работает Web-приложение, или данные, описывающие сеанс работы пользователя.
Интерфейсные функции доступны не во всех состояниях, так как не во всех состояниях пользовательского интерфейса присутствуют элементы интерфейса, воздействия на которые соответствуют этим интерфейсным функциям. Например, некоторые элементы интерфейса становятся доступны только после авторизации, HTML-формы с полями и кнопками располагаются не на всех страницах Web-приложения.
Условия доступности описываются в предусловии и определяются состоянием Web-приложения. Требования к функциональности описываются в постусловии в виде ограничений на состояние, в которое переходит Web-приложение в результате воздействия, описываемого интерфейсной функцией. Часто одному URL соответствуют пользовательские интерфейсы, содержащие одни и те же наборы интерфейсных функций. В таких случаях эти наборы удобно объединять в группы функций и специфицировать их как методы одного спецификационного класса. В других случаях одни и те же функции могут присутствовать сразу на нескольких интерфейсах, соответствующих разным URL. В этом случае интерфейсные функции удобно объединять в группы в зависимости от функционального назначения и специфицировать отдельно. Это позволяет получить хорошо структурированные спецификации, в которых дублирование описания функциональности сведено к минимуму. По сравнению с первым, этот вариант позволяет уделить большее внимание описанию именно функциональности Web-приложения, абстрагируясь от деталей обработки HTTP-запросов и ответов, что существенно упрощает моделирование работы пользовательских интерфейсов, обладающих сложным динамическим поведением. При тестировании вызов интерфейсной функции преобразуется в воздействия на соответствующие элементы пользовательского интерфейса Web-приложения. Для этого используются специальные средства (например, API Web-браузера), обеспечивающие доступ к внутреннему состоянию Web-браузера и позволяющие моделировать воздействия на элементы интерфейса. Эти же средства используются для получения информации о результатах воздействия, которые отражаются в состоянии пользовательского интерфейса. Такая информация необходима для проверки корректности поведения тестируемого Web-приложения. В отличие от первого варианта, для определения связи интерфейсных функций с Web-приложением требуются более сложные преобразования, так как обращение к одной интерфейсной функции может быть преобразовано в несколько последовательных воздействий на элементы пользовательского интерфейса.
При ручном описании этих преобразований потребуется больше усилий; кроме того, тестировщик должен обладать знаниями и навыками работы со специальными средствами доступа к внутреннему состоянию Web-браузера. Тем не менее, в большинстве случаев этот процесс можно автоматизировать при помощи дополнительной функциональности инструментов тестирования, реализующих технологию UniTesK. При создании тестовых сценариев для этого варианта удобно опираться на предлагаемый технологией UniTesK метод построения тестовой последовательности, основанный на обходе графа переходов конечного автомата. Часто в качестве состояния автомата удобно рассматривать страницы с одним и тем же URL, а в качестве переходов между состояниями – вызовы интерфейсных функций. При построении тестового сценария основной задачей пользователя становится описание перебора параметров интерфейсных функций. При этом не нужно описывать все интересные пути обхода страниц Web-приложения; обход достижимых состояний автомата будет автоматически реализован при помощи обходчика. Описание перебора параметров интерфейсных функций (т.е. перебор данных на странице, например, перебор значений полей формы) может быть автоматизировано при помощи некоторого интерактивного режима работы пользователя с инструментом. Этот же интерактивный режим работы, в принципе, может быть использован и для создания сценариев тестирования на основе подхода Capture & Playback, если пользователь все-таки захочет вручную выделить некоторые пути обхода страниц. Итак, во втором варианте пользователю предлагается более «естественный» язык для создания теста – в терминах интерфейсных элементов Web-приложения и воздействий на них. Описания становятся более понятными, что, как следствие, снижает требования к квалификации разработчиков тестов. Недостатком этого варианта по сравнению с первым можно считать отсутствие возможности протестировать работу Web-приложения на некорректных HTTP-запросах.
Моделирование поведения на уровне HTTP
В первом варианте модель Web-приложения представляется одной интерфейсной функцией, описывающей HTTP-запрос к Web-приложению. Параметры этой функции – это параметры запроса (например, тип запроса (GET или POST), адрес (URL), параметры заголовка и т.д.) и список данных, которые передаются Web-приложению. Выходные параметры функции формируются на основе HTTP-ответа, пришедшего от Web-приложения.
Требования к функциональности формулируются в виде набора ограничений на выходные параметры в зависимости от значений входных параметров и модели состояния Web-приложения. Требования в большинстве случаев сильно различаются в зависимости от URL, поэтому спецификацию интерфейсной функции можно разделить на независимые спецификации нескольких интерфейсных функций, каждая из которых описывает поведение, характерное для конкретного семейства значений параметра, определяющего URL. Однако для больших Web-приложений такое описание требований получается громоздким и плохо структурируемым.
Каждая интерфейсная функция соответствует определенному запросу с некоторыми параметрами; в процессе работы тестовой системы вызов интерфейсной функции преобразуется в посылку соответствующего HTTP-запроса серверу. HTTP-запрос строится на основе формальных правил преобразования параметров, поэтому шаг технологии UniTesK, на котором происходит связывание требований с реализацией, полностью автоматизируется.
При создании тестовых сценариев для этого варианта наибольшую трудность представляет организация перебора параметров выделенных интерфейсных функций. Для каждого конкретного случая можно найти наиболее подходящий способ перебора параметров, однако это требует от тестировщика определенной квалификации и опыта.
Следует отметить, что этот вариант позволяет тестировать Web-приложение на устойчивость к некорректным HTTP-запросам, так как можно имитировать ситуации, которые не должны появиться в процессе нормальной работы с Web-приложением посредством браузера.
Направления дальнейшего развития
В данной работе мы представили расширение технологии UniTesK, которое автоматизирует процесс создания тестов для тестирования функциональности Web-приложений. Тесты строятся в терминах элементов интерфейса и воздействий на них в процессе интерактивной работы пользователя с инструментом, реализующим это расширение. Инструмент взаимодействует с Web-приложением, автоматизируя анализ его интерфейса в предположении, что основная функциональность Web-приложения реализована на стороне сервера.
В заключение рассмотрим возможные направления развития данного подхода. Одним из наиболее важных направлений является автоматизация поддержки тестового набора в актуальном состоянии при изменении интерфейса Web-приложения. Эта проблема присутствует во всех подходах, в которых тесты строятся на основе уже работающей реализации. Единственное относительно успешное решение заключается в локализации компонентов теста, зависящих от деталей реализации интерфейса Web-приложения, позволяющей сократить усилия по приведению тестов в соответствие с изменившимся интерфейсом.
Следующее направление – тестирование функциональности, реализованной в пользовательском интерфейсе. Напомним, что эта функциональность обычно заключается в проверке корректности входных данных и реализации дополнительных возможностей интерфейса. Для описания этой функциональности нужно использовать принципы выделения интерфейсных функций, основанные на более детальном описании взаимодействия пользователя с Web-браузером.
И, наконец, можно выделить направление, связанное с расширением видов тестирования, поддерживаемых инструментом, начиная от генерации некорректных HTTP-запросов для тестирования устойчивости Web-приложения и заканчивая использованием разработанных тестовых наборов для нагрузочного тестирования.
Применение UniTesK для тестирования Web-приложений
Технология UniTesK применялась для тестирования Web-приложений в нескольких проектах. В ходе разработки тестов выяснилось, что большая часть усилий тратится на создание медиаторов, которые переводят вызов интерфейсных функций в последовательность воздействий на Web-приложение. Анализ опыта показал, что большая часть этой работы может быть автоматизирована, опираясь на стандартизированную архитектуру пользовательского интерфейса Web-приложений. В принципе, эту особенность Web-приложений можно было бы использовать для автоматизации других шагов технологии UniTesK. В этом разделе будут рассмотрены варианты моделирования поведения Web-приложения в контексте возможной автоматизации шагов технологии UniTesK.
Моделирование определяется способом выделения интерфейсных функций и способом построения модели состояния Web-приложения. Первый вариант основывается на стандартном протоколе HTTP, который служит для взаимодействия между Web-браузером и Web-приложением. Поведение Web-приложения рассматривается на уровне HTTP, и этот уровень считается единственно возможным для обращения к Web-приложению. Во втором варианте за основу берется формальное описание интерфейса в виде HTML, которое используется Web-браузером для организации взаимодействия с пользователем. В этом варианте взаимодействие с Web-приложением происходит только посредством Web-браузера. И, наконец, в третьем варианте поведение Web-приложения моделируется без привязки к конкретному способу обращения, основываясь лишь на тестируемой функциональности.
Сравнение с другими подходами
В предлагаемый подход, по возможности, были включены достоинства распространенных подходов и инструментов, предназначенных для функционального тестирования Web-приложений. Этот подход, как и другие, позволяет строить тесты, оперируя терминами интерфейса и действий с ним; полученные тесты могут быть расширены с использованием итерации данных. Предоставляются средства для автоматического прогона полученных тестов, анализа их результатов и генерации отчетов о покрытии и обнаруженных ошибках. Инструмент, реализующий данный подход, может быть использован для создания тестов в стиле Capture & Playback с сохранением всех достоинств этого подхода к тестированию. В реализации описанного подхода также присутствует и основное достоинство подхода Keyword Driven – хорошая архитектура тестового набора, обеспечивающая устойчивость при изменении интерфейса.
В то же время предложенный подход отличается от других рядом преимуществ. В отличие от подхода Capture & Playback он позволяет автоматически генерировать тестовые последовательности, покрывающие различные тестовые ситуации. Таким образом, в этом подходе затраты на создание комплекта тестов того же качества становятся меньше. Другим достоинством данного подхода является возможность создания тестов для не полностью корректной реализации. Если в реализации присутствует ошибка, заключающаяся в том, что при некотором воздействии приложение переходит на некорректную страницу, то инструмент, реализующий Capture & Playback, ошибочно запоминает результат этого перехода как правильный. Добавление этого теста в автоматизированный тестовый набор будет возможно только после исправления ошибки – нужно, чтобы инструмент запомнил корректный результат. В описанном же подходе при описании модели можно явно указать ожидаемую страницу и ее параметры, после чего инструмент будет рассматривать любой другой результат как ошибочный и генерировать соответствующие отчеты об ошибках.
Подход Keyword Driven не предоставляет возможности автоматизации разработки тестов и хорошо автоматизирует только выполнение тестов. Описанный подход автоматизирует как выполнение, так и разработку тестов.
К перечисленным преимуществам можно добавить возможность автоматизированного анализа интерфейса Web-приложения, благодаря чему пользователь может выбирать интерфейсные функции из списка функций, автоматически найденных на странице. Кроме того, в дополнение к традиционным источникам данных для итерации параметров, таких как файлы различных форматов и базы данных, инструмент позволяет извлекать данные из интерфейса Web-приложения, что удобно использовать для организации динамически изменяемого перебора параметров.
Сравнение возможной автоматизации вариантов моделирования
Сравним рассмотренные варианты. Цель сравнения – выбрать вариант для тестирования Web-приложений, который обеспечивал бы наибольшую автоматизацию процесса разработки тестов при реализации инструментальной поддержки. Вместе с тем, инструментальная поддержка должна обеспечивать высокое качество функционального тестирования на уровне UniTesK, обладая при этом простотой использования и освоения. Каждый вариант мы будем рассматривать, исходя из следующих критериев. Во-первых, рассмотрим каждый вариант с позиции уровня автоматизации каждого шага технологического процесса UniTesK (последний шаг – выполнение тестов и анализ результатов – не рассматривается, так как инструменты UniTesK уже автоматизируют этот шаг в достаточной степени). Во-вторых, рассмотрим уровень абстракции получаемой в каждом варианте модели требований, поскольку более абстрактные модели облегчают повторное использование, а также обеспечивают простоту разработки и сопровождения получаемых тестов. В-третьих, рассмотрим предъявляемые каждым вариантом требования к квалификации пользователя, что обобщает простоту использования и обучения работе с инструментом. Результаты сравнения представлены в Таблице 1.
Таблица 1. Сравнение рассмотренных вариантов возможного моделирования Web-приложений с использованием технологии UniTesK.
Прокомментируем результаты, приведенные в таблице. Результатом анализа функциональности тестируемой системы является список интерфейсных функций с входными и выходными параметрами. При моделировании без привязки к уровню взаимодействия этот выбор осуществляется пользователем полностью вручную, исходя из представлений о функциональности тестируемой системы. В других вариантах моделирования можно предложить формальный способ выделения интерфейсных функций на основе анализа интерфейса Web-приложения (может быть, с использованием интерактивного режима).
Формализация требований трудно поддается автоматизации, как и всякий переход от неформального к формальному, но в рамках моделирования на уровне Web-браузера можно предложить автоматизацию формализации некоторой части требований с использованием интерактивного режима.
Проблема связывания требований с реализацией решается посредством автоматической генерации медиаторов при моделировании как на уровне Web-браузера, так и на уровне HTTP.
Для моделирования без привязки к уровню взаимодействия для создания медиаторов можно предложить воспользоваться интерактивным режимом работы с инструментом, при котором для каждой интерфейсной функции определяется последовательность воздействий на элементы пользовательского интерфейса Web-приложения. При разработке тестовых сценариев можно пользоваться стандартными средствами инструментов семейства UniTesK, которые позволяют автоматизировать процесс задания основных элементов тестового сценария. Однако для моделирования на уровне Web-браузера можно предложить дополнительные средства для организации перебора параметров и идентификации различных тестовых ситуаций, например, извлекать данные для перебора из интерфейса Web-приложения или выбирать элементы интерфейса, идентифицирующие состояние. При моделировании на уровне HTTP описание функциональности и тестирование осуществляется в терминах HTTP-запросов, что заставляет пользователя разбираться с большим объемом технической информации, повышая тем самым требования к его квалификации. Моделирование на уровне Web-браузера позволяет описывать функциональность и проводить тестирование в терминах элементов пользовательского интерфейса и воздействий на них, что является естественным языком для разработчика тестов. Описание, выполненное в таких терминах, позволяет отразить требования к функциональности на приемлемом уровне абстракции, не сосредотачиваясь на деталях технологий, лежащих в основе Web-приложения. Третий вариант не ограничивает пользователя в свободе выбора уровня описания функциональности, но вместе с тем не предоставляет дополнительных возможностей по автоматизации, возлагая всю работу на пользователя, что требует от него определенных навыков и опыта. Описанные варианты моделирования были опробованы в ходе тестирования Web-приложений с использованием технологии UniTesK. Все шаги технологического процесса были реализованы с использованием инструментов UniTesK без дополнительной автоматизации, которая упоминалась в обзоре вариантов моделирования.Анализ процесса разработки показал необходимость и подтвердил выводы о возможности дополнительной автоматизации шагов технологии. Кроме того, опыт передачи тестовых наборов, разработанных с помощью технологии UniTesK, в реальное использование показал, что моделирование без привязки к уровню взаимодействия требует от разработчиков и последующих пользователей хорошего знания технологии UniTesK. В то же время, моделирование на уровне Web-браузера более естественно воспринималось пользователями, тестирующими Web-приложения и не владеющими технологией UniTesK. Оценивая рассмотренные варианты с этих позиций, можно сказать, что моделирование на уровне Web-браузера является наиболее подходящим для дальнейшей автоматизации и дополнительной инструментальной поддержки. В следующем разделе мы остановимся более подробно на реализации дополнительной инструментальной поддержки этого подхода.
Существующие подходы к функциональному тестированию Web-приложений
Самым распространенным является подход, называемый Capture & Playback (другие названия – Record & Playback, Capture & Replay). Суть этого подхода заключается в том, что сценарии тестирования создаются на основе работы пользователя с тестируемым приложением. Инструмент перехватывает и записывает действия пользователя, результат каждого действия также запоминается и служит эталоном для последующих проверок. При этом в большинстве инструментов, реализующих этот подход, воздействия (например, нажатие кнопки мыши) связываются не с координатами текущего положения мыши, а с объектами HTML-интерфейса (кнопки, поля ввода и т.д.), на которые происходит воздействие, и их атрибутами. При тестировании инструмент автоматически воспроизводит ранее записанные действия и сравнивает их результаты с эталонными, точность сравнения может настраиваться. Можно также добавлять дополнительные проверки – задавать условия на свойства объектов (цвет, расположение, размер и т.д.) или на функциональность приложения (содержимое сообщения и т.д.). Все коммерческие инструменты тестирования, основанные на этом подходе, хранят записанные действия и ожидаемый результат в некотором внутреннем представлении, доступ к которому можно получить, используя или распространенный язык программирования (Java в Solex [2]), или собственный язык инструмента (4Test в SilkTest [3] от Segue, SQABasic в Rational Robot [4] от IBM, TSL в WinRunner [5] от Mercury). Кроме элементов интерфейса, инструменты могут оперировать HTTP-запросами (например, Solex [2]), последовательность которых также может записываться при работе пользователя, а затем модифицироваться и воспроизводиться.
Основное достоинство этого подхода – простота освоения. Создавать тесты с помощью инструментов, реализующих данный подход, могут даже пользователи, не имеющие навыков программирования. Вместе с тем, у подхода имеется ряд существенных недостатков. Для разработки тестов не предоставляется никакой автоматизации; фактически, инструмент записывает процесс ручного тестирования.
Если в процессе записи теста обнаружена ошибка, то в большинстве случаев создать тест для последующего использования невозможно, пока ошибка не будет исправлена (инструмент должен запомнить правильный результат для проверки). При изменении тестируемого приложения набор тестов трудно поддерживать в актуальном состоянии, так как тесты для изменившихся частей приложения приходится записывать заново. Этот подход лучше всего использовать для создания прототипа теста, который впоследствии может служить основой для ручной доработки. Одна из возможных доработок – параметризация теста для проверки тестируемого приложения на различных данных. Этот подход называется тестированием, управляемым данными (Data Driven [6, 7]). Основное ограничение – перебираемые данные не должны изменять поведение тестируемого приложения, поскольку проверки, записанные в тестовом сценарии, не подразумевают какой-либо анализ входных данных, т.е. для каждого варианта поведения нужно создавать свой сценарий тестирования со своим набором данных. Некоторые инструменты, реализующие Capture & Playback, предоставляют возможность по перебору данных (например, e-Tester [8] от Empirix); кроме того, над большинством распространенных инструментов существуют надстройки (Convergys Auto Tester [6] – надстройка над WinRunner). Описанные подходы основываются на построении тестов с использованием тестируемого приложения. В подходе KeywordDriven [7, 9] предпринимается попытка сделать процесс создания тестов независимым от реализации. Суть подхода заключается в том, что действия, выполняемые в ходе тестирования, описываются в виде последовательности ключевых слов из специального словаря («нажать», «ввести», «проверить» и т.д.). Специальный компонент тестовой системы переводит эти слова в воздействия на элементы интерфейса тестируемого приложения. Таким образом, никакого программирования для создания тестов не нужно. Единственное, что нужно менять при изменении интерфейса, – это компонент, который отвечает за перевод слов из «словаря» в последовательность воздействий на приложение.
Комплект тестов может разрабатываться пользователями, не владеющими навыками программирования, однако для поддержания комплекта в рабочем состоянии программирование все-таки необходимо. В качестве примера инструмента, поддерживающего такой подход к разработке тестов, можно привести Certify [10] от WorkSoft, в котором поддерживается библиотека функций для работы с каждым компонентом интерфейса (окна, гиперссылки, поля ввода и т.д.) и предоставляется язык воздействий на эти элементы (InputText, VerifyValue, VerifyProperty и т.д.). Основные преимущества этого подхода заключаются в том, что он позволяет создавать тесты, не дожидаясь окончания разработки приложения, руководствуясь требованиями и дизайном интерфейса. Созданные тесты можно использовать как для автоматического выполнения, так и для ручного тестирования. Основной недостаток этого подхода – отсутствие автоматизации процесса разработки тестов. В частности, все тестовые последовательности разрабатываются вручную, что приводит к проблемам, как на стадии разработки, так и на стадии сопровождения тестового набора. Эти проблемы особенно остро проявляются при тестировании Web?приложений со сложным интерфейсом.
Технология UniTesK
Большинство проблем, присущих рассмотренным подходам разработки тестов, решены в технологии UniTesK, разработанной в Институте системного программирования РАН. Технология хорошо себя зарекомендовала при функциональном тестировании разнообразных систем (ядро операционной системы, стеки протоколов, компиляторы). Опыт применения технологии для тестирования Web-приложений показал, что UniTesK может служить хорошей базой для тестирования такого класса приложений. В этом разделе мы остановимся на основных моментах технологии UniTesK (более детальную информацию о ней можно найти в [11, 12, 13, 14]); в последующих разделах рассмотрим особенности применения технологии для тестирования Web-приложений.
Технология UniTesK – это технология разработки функциональных тестов на основе моделей, которые используются для оценки корректности поведения целевой системы3 и автоматической генерации последовательностей воздействий, далее называемых тестовыми последовательностями.
Оценка корректности поведения целевой системы осуществляется в рамках следующего представления об устройстве интерфейса целевой системы. Предполагается, что целевая система предоставляет набор интерфейсных функций, и все воздействия на нее осуществляются только через вызовы этих интерфейсных функций. Параметры воздействий, передаваемые целевой системе, описываются входными параметрами интерфейсной функции. Результат воздействия (реакция системы) представляется выходными параметрами, значения которых могут зависеть от истории взаимодействий целевой системы с окружением. Информация об истории моделируется внутренним состоянием целевой системы. Внутреннее состояние влияет на выходные параметры интерфейсных функций и может изменяться в результате их работы.
Следует заметить, что в рамках данной статьи для тестирования Web-приложений рассматривается представление, в котором воздействия на целевую систему и получение ее реакции на это воздействие (выходные параметры интерфейсной функции) рассматриваются как атомарное действие.
Под атомарностью действия понимается, что следующее воздействие можно произвести только после получения реакции на предыдущее. Технология UniTesK также позволяет представлять целевую систему и как систему с отложенными реакциями, т.е. как систему, разрешающую воздействие до получения всех реакций на предыдущее. Корректность поведения целевой системы оценивается с точки зрения его соответствия поведению некоторой «эталонной» модели, называемой спецификацией. В технологии UniTesK эталонная модель описывается неявно в виде требований к поведению каждой интерфейсной функции. При задании эталонной модели можно описывать функции и их параметры в достаточно обобщенном виде, отвлекаясь от несущественных подробностей. Основными компонентами тестовой системы являются итератор тестовых воздействий, оракул и медиатор. Задачей итератора тестовых воздействий, работающего под управлением обходчика, является построение тестовой последовательности,
обеспечивающей заранее определенный критерий тестового покрытия. Задачей оракула является оценка корректности поведения целевой системы. Задача медиатора – преобразовывать тестовое воздействие в последовательность реальных воздействий на целевую систему и на основании доступной информации построить новое модельное состояние целевой системы после вызова. В качестве языка описания компонентов тестовой системы используются спецификационные расширения обычных языков программирования, таких как C# и Java. В этих расширениях реализованы три вида специальных классов, предназначенных для описания компонентов тестовой системы. Из спецификационных классов генерируются оракулы, из медиаторных – медиаторы, а из сценарных – итераторы тестовых воздействий. В спецификационных классах описываются спецификационные методы, каждый из которых соответствует некоторой интерфейсной функции и содержит формальное описание требований к поведению целевой системы при взаимодействии с ней через данную интерфейсную функцию. Сценарные классы предназначены для описания тестовых сценариев, содержащих описание единичных воздействий и правил итерации их параметров.
Медиаторы генерируются на основе медиаторных классов, которые связывают интерфейсные функции с воздействиями на целевую систему. Схема работы тестовой системы, разработанной по технологии UniTesK, представлена на рисунке 2. Основной шаг работы тестовой системы устроен следующим образом. Обходчик выбирает очередное сценарное воздействие. Сценарное воздействие содержит несколько обращений к целевой системе, представляющих собой вызов интерфейсной функции с определенным набором значений входных параметров. Вызов интерфейсной функции передается оракулу, который, в свою очередь, передает его медиатору. Медиатор преобразует вызов интерфейсной функции в последовательность действий над тестируемой системой, получает результат этих действий от тестируемой системы и преобразует его в значения выходных параметров интерфейсной функции. Медиатор также синхронизирует модель состояния тестируемой системы, используемую оракулом для оценки корректности поведения, с ее реальным состоянием. Оракул, зная значения входных и выходных параметров интерфейсной функции, а также состояние целевой системы, оценивает корректность ее поведения в рамках данного взаимодействия. Если вердикт оракула является отрицательным, то это значит, что тестовая система нашла несоответствие между поведением целевой системы и требованиями к ней. По завершении выполнения одного шага управление возвращается обходчику, который выбирает следующее сценарное воздействие или принимает решение о прекращении тестирования. Все события, происходящие в процессе тестирования, находят свое отражение в трассе теста. На основе трассы генерируются различные отчеты, помогающие в анализе результатов тестирования. Процесс разработки тестов с помощью технологии UniTesK можно представить в виде следующей последовательности шагов4: (1) анализ функциональности тестируемой системы; (2) формализация требований к функциональности; (3) связывание формализованных требований с реализацией; (4) разработка сценариев тестирования; (5) исполнение тестов и анализ результатов. Рассмотрим каждый из этих шагов более подробно. В результате анализа функциональности необходимо определить интерфейс тестируемой системы.
Для этого требуется выделить функции, предоставляемые системой, и для каждой такой функции определить, что выступает в качестве ее входных и выходных параметров. На этапе формализации требований для каждой интерфейсной функции, выявленной на предыдущем шаге, необходимо описать ограничения на значения выходных параметров в зависимости от значений входных параметров и истории предыдущих взаимодействий с тестируемой системой. Для этого в технологии UniTesK используется широко известный подход программных контрактов [15]. В основе этого подхода лежат инварианты данных, а также предусловия и постусловия интерфейсных операций. При
связывании требований с реализацией необходимо описать, как каждая интерфейсная функция отображается на реализацию тестируемой системы. В рамках этого отображения требуется установить правила преобразования вызовов интерфейсных функций в последовательность действий над тестируемой системой, а также правила построения модели состояния тестируемой системы. Для систем с прикладным программным интерфейсом, когда взаимодействие через интерфейсную функцию соответствует вызову функции тестируемой системы, установление такого отображения может быть автоматизировано при помощи интерактивных шаблонов, предоставляемых инструментами семейства UniTesK.
Тестовые сценарии строятся на основе конечно-автоматной модели целевой системы, которая используется для динамической генерации последовательностей тестовых воздействий. Сценарий определяет, что именно рассматривается как состояние автомата, и какие интерфейсные функции с какими наборами аргументов могут быть вызваны в каждом состоянии. Алгоритмы UniTesK обеспечивают вызов каждой интерфейсной функции с каждым набором ее параметров в каждом достижимом состоянии. Для описания сценария необходимо задать способ идентификации состояний и способ итерации входных воздействий в зависимости от текущего состояния. Инструменты семейства UniTesK предоставляют интерактивные шаблоны, которые позволяют упростить разработку тестовых сценариев. На заключительном этапе технологического процесса происходит выполнение созданных тестов, автоматическая генерация отчетов о результатах тестирования и анализ этих результатов.На основе анализа принимаются решения о создании запросов на исправление дефектов, обнаруженных в тестируемой системе, или о доработке самих тестов с целью повышения уровня покрытия.
приложениями мы будем называть любые
В данной статье Web- приложениями мы будем называть любые приложения, предоставляющие Web-интерфейс. В настоящее время такие приложения получают все большее распространение: системы управления предприятиями и драйверы сетевых принтеров, интернет-магазины и коммутаторы связи – это только небольшая часть приложений, обладающих Web интерфейсом. В отличие от обычного графического пользовательского интерфейса Web-интерфейс отображается не самим приложением, а стандартизированным посредником – Web-браузером. Web-браузер берет на себя все взаимодействие с пользователем и обращается к Web-приложению только в случае необходимости. Описание пользовательского интерфейса предоставляется браузеру в стандартном представлении, в роли которого обычно выступает HTML [1]. На рисунке 1 представлен процесс работы типичного Web-приложения. Пользователь взаимодействует с приложением посредством Web-браузера, который при необходимости обращается с запросом к Web-приложению, чтобы выполнить ту или иную операцию. Результатом такого обращения является полное или частичное обновление интерфейса приложения, отображаемого в браузере. При обращении к Web-приложению браузер посылает запрос по одному из протоколов доступа (HTTP, HTTPS или др.). Web-приложение обрабатывает запрос и возвращает браузеру описание обновленного интерфейса. Web-приложения в первую очередь характеризуются тем, что их пользовательский интерфейс имеет стандартизированную архитектуру, в которой: 1) для взаимодействия с пользователем используется Web-браузер; 2) взаимодействие с пользователем четко разделяется на этапы, в течение которых браузер работает с одним описанием интерфейса; 3) эти этапы разделяются однозначно выделяемыми обращениями от браузера к приложению; 4) для описания интерфейса применяется стандартное представление ((HTML); 5) коммуникации между браузером и приложением осуществляются по стандартному протоколу (HTTP). Web-приложения можно рассматривать как клиент/серверные приложения, в которых функциональность реализуется как на серверной, так и на клиентской стороне.
реализованная на клиентской стороне, как
Функциональность, реализованная на клиентской стороне, как правило, сводится к проверке вводимых данных и реализации дополнительных возможностей интерфейса, что реализуется путем использования скриптовых возможностей, встроенных в HTML (использование Java-script, VBScript и т.д.). В этой статье мы будем рассматривать функциональное тестирование именно серверной части, оставляя рассмотрение функциональности клиентской части в качестве темы будущих исследований. В этом случае основной интерес представляют взаимодействия браузера с сервером. Эти взаимодействия хорошо формализованы, поскольку осуществляются на основе протокола HTTP. Четкая формализация взаимодействий может служить основой для автоматизации функционального тестирования. С другой стороны, представление интерфейса в виде HTML также четко формализовано. Кроме того, в этом описании интерфейса можно выделить действия, приводящие к взаимодействию с сервером. Эти действия связаны с воздействиями на кнопки, активизацией гиперссылок и реакциями на различные события, закодированные в скриптовой части интерфейса. Таким образом, формальное описание интерфейса Web-приложений также предоставляет широкие возможности для автоматизации функционального тестирования. Но как наилучшим образом использовать потенциал, предоставляемый стандартизированной архитектурой интерфейса Web-приложения? Исследованию этого вопроса и посвящена данная работа. Статья построена следующим образом. В разделе 2 мы рассмотрим существующие подходы к автоматизации функционального тестирования Web-приложений. В разделе 3 будут представлены основные сведения о технологии автоматизации тестирования на основе моделей UniTesK. Затем мы проанализируем различные варианты моделирования Web-приложений в рамках технологии UniTesK и по результатам этого анализа представим расширение базовой технологии UniTesK, специально адаптированное для функционального тестирования Web-приложений. В заключение, мы рассмотрим пути дальнейшего развития предложенного подхода.
Аннотация
В статье описывается методика автоматической генерации наборов позитивных и негативных тестов для тестирования фазы синтаксического анализа. Предлагаются критерии покрытия для таких наборов, основанные на модельном подходе к тестированию, и методы генерации наборов тестов, удовлетворяющих предложенным критериям. Также приводятся результаты практического применения описанной методики к тестированию синтаксических анализаторов различных языков, в том числе языков C и Java.
Автоматическая генерация позитивных
С.В. Зеленов, С.А. Зеленова
Труды Института Системного Программирования РАН, 2004 г.
Критерии покрытия
Как видно из описания LL- и LR-анализаторов, основной момент их работы – принятие решения о дальнейших действиях на основании некоторых неполных данных (прочитанной части входного потока). Для LL-анализатора ситуации выбора соответствует пара (нетерминал на вершине стека, текущий входной символ), а для LR-анализатора – пара (символ состояния конечного автомата на вершине стека, текущий входной символ). Отсюда возникают следующие критерии покрытия для позитивных тестовых наборов:
(PLL) Покрытие всех пар
(нетерминал A, допустимый следующий токен t),
где пара (A,t) считается покрытой тогда и только тогда, когда в тестовом наборе существует последовательность токенов, являющаяся предложением целевого языка, имеющая вывод S


(PLR) Покрытие всех пар
(символ si состояния конечного автомата, помеченный символом X переход из состояния si),
где пара (si,X) считается покрытой тогда и только тогда, когда в тестовом наборе существует предложение языка, имеющее вывод S
(NLLR) Пусть A – нетерминал. Последовательность токенов t1...tr назовем допустимой для A предпоследовательностью токенов, если существует сентенциальная форма ?t1...trA?, выводимая из стартового правила.
Рассмотрим объединение множеств

Заметим, что для такой грамматики покрытие всех пар (состояние конечного автомата, переход из этого состояния в другое) достигается при покрытии всех пунктов грамматики. Рассмотрим следующий критерий покрытия для наборов позитивных тестов: (WPLR) Покрытие всех пар (пункт ? = B > ?•X? грамматики G, допустимый первый токен t для символа X). Пара (?,t) считается покрытой тогда и только тогда, когда в тестовом наборе существует предложение языка, имеющее вывод S

т.е. ?t1...tr выводится из ??, а ? – из ??. Рассмотрим объединение множеств
Говорят, что мутант убит, если на некоторых входных данных его выход отличен от выхода исходной программы. Если имеется множество тестовых входных данных для программы, то с помощью мутационного анализа (mutation analysis) можно оценить качество этих тестов. Именно, если имеется множество мутантов, то критерий покрытия говорит, что все мутанты должны быть убиты. В случае синтаксического анализатора логично в качестве мутируемого материала рассматривать грамматику языка, т.к. ошибочный анализатор фактически распознает другой язык. В этом случае грамматика-мутант будет убита, если найдется последовательность токенов, принадлежащая языку, задаваемому этой грамматикой-мутантом и не принадлежащая исходному языку (в терминах анализаторов это как раз будет означать, что анализатор-мутант распознал данное предложение, а исходный анализатор – нет, т.е. анализатор-мутант оказался убитым). 2 Существует связь между предлагаемым подходом и методом мутационного тестирования. Именно, для любой последовательности токенов, являющейся негативным тестом в описанном выше смысле (т.е. предложением языка, “испорченным” с помощью вставки/замены “нехорошего” токена) можно построить грамматику-мутант такую, что данный негативный тест будет являться предложением языка, описываемого этой грамматикой-мутантом. Одним из принципов мутационного тестирования является так называемый эффект взаимосвязи (coupling effect): при обнаружении простых ошибок будут обнаруживаться и более сложные (см. [16]). Согласно этому эффекту взаимосвязи, мутации должны быть простыми. Заметим, что предлагаемый подход вполне согласуется с этим принципом. Продолжение
Позитивные и негативные тесты для синтаксического анализатора
В данной работе парсером мы называем булевскую функцию, заданную на множестве последовательностей токенов и принимающую значение “истина”, если последовательность является предложением данного формального языка, и “ложь” – иначе. Конечно, реальные парсеры могут иметь дополнительную функциональность (например, помимо булевского значения выдавать дерево разбора или идентификацию ошибки), но здесь мы такую функциональность не рассматриваем.
Позитивный тест для парсера – это последовательность токенов, на которой парсер выдает вердикт “истина”, т.е. последовательность токенов, являющаяся предложением целевого языка.
Негативный тест для парсера – это последовательность токенов, на которой парсер выдает вердикт “ложь”, т.е. последовательность токенов, не являющаяся предложением целевого языка.
Для построения какого-нибудь позитивного теста достаточно, следуя правилам грамматики и ограничив рекурсию правил, вывести из стартового символа некоторую сентенциальную форму, состоящую из одних токенов. При построении же негативных тестов возникают два вопроса: насколько произвольна должна быть соответствующая последовательность токенов, и как добиться того, чтобы она действительно не принадлежала целевому языку. Сначала ответим на второй вопрос: как получить последовательность токенов, гарантированно не принадлежащую множеству предложений целевого языка.
Рассмотрим грамматику G= (T ,N,P,S). Для каждого грамматического символа X ?T ?N, определим множество UX вхождений символа X в грамматику G. Это множество состоит из всех пар
(правило p ?P, номер i символа в правиле p)
таких, что символ, стоящий на i-ом месте в правой части правила p является грамматическим символом X. Пару (p,i) ?UX будем называть вхождением символа X в правило p.
Пусть t – токен. Для каждого вхождения u ?Ut, u = (p,i), p = X > ?t? токена t в грамматику G можно построить множество Fu токенов t'?T таких, что существует вывод
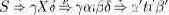
Здесь греческие буквы обозначают некоторые субсентенциальные формы, т.е.
последовательности нетерминалов и токенов. Если в грамматике G существует вывод S




Предварительные сведения
В этом разделе мы приводим некоторые сведения из теории синтаксического анализа. Более подробное изложение приведенных фактов можно найти в известной книге А. Ахо, Р. Сети и Д. Ульмана (см. [5]).
Грамматика формального языка задается четверкой G = (T,N,P,S), где T – множество терминальных символов или токенов; N – множество нетерминальных символов; P – список правил грамматики; S – стартовый символ грамматики. Множество предложений формального языка, задаваемого грамматикой G, будем обозначать

Дадим несколько определений.
Расширением грамматики G (или просто расширенной грамматикой) называется грамматика G' = (T,N',P',S'), где S' – новый нетерминальный символ, а к множеству правил добавлено правило S' > S.
Сентенциальной формой будем называть последовательность грамматических символов – нетерминалов и токенов. Далее, греческими буквами из начала алфавита (?, ?, ?, ?, ...) мы будем обозначать какие-либо сентенциальные формы. Пустую сентенциальную форму будем обозначать через ?.
Правосентенциальной формой называется сентенциальная форма, для которой существует правый вывод из стартового правила.
Пример. Рассмотрим следующую грамматику:
| S > AB |
| A > cd |
| B > eCf |
| C > Ae |
В ней сентенциальная форма cdB не имеет правого вывода, т.е. не может быть получена с помощью последовательного раскрытия самых правых нетерминалов. Примером правосентенциальной формы может служить форма AeCf. >
Основой правосентенциальной формы называется подпоследовательность ее символов, которая может быть свернута в некоторый нетерминал, такая, что сентенциальная форма, полученная из исходной после свертки, может быть свернута в стартовый символ.
Пример. Пусть грамматика та же, что и в предыдущем примере. Форма AeCf, как мы уже заметили, является правосентенциальной. В ней есть две подпоследовательности символов Ae и eCf, которые могут быть свернуты в нетерминалы C и B соответственно. Однако основой является только последовательность eCf, так как сентенциальная форма CCf невыводима из стартового символа.
> Активным префиксом правосентенциальной формы называется префикс, не выходящий за границы самой правой основы этой формы. Пунктом грамматики G называется правило вывода с точкой в некоторой позиции правой части. Множество всех пунктов грамматики G будем обозначать через

На каждом шаге рассматривается символ на вершине стека X и текущий входной символ a. Действия анализатора определяются этими двумя символами: если X = a = $, то анализатор прекращает работу и сообщает об успешном завершении разбора; если X = a ? $, анализатор удаляет из стека символ X и переходит к следующему символу входного потока; если X является нетерминалом, анализатор ищет такую альтернативу раскрытия символа X, для которой символ a является допустимым первым символом. После того, как требуемая альтернатива найдена, символ X в стеке заменяется обратной последовательностью символов альтернативы. Например, если искомая альтернатива X > ABC, то анализатор заменит X на вершине стека на последовательность CBA, т.е. на вершине стека окажется символ A. Конфликты, возникающие в процессе поиска альтернатив, могут разрешаться, например, с помощью “заглядывания вперед”, т.е. просмотра нескольких входных символов вместо одного. Анализатор завершает работу, когда на вершине стека оказывается символ конца строки $. Рассмотрим теперь LR-анализатор, построенный на основе стека. У такого LR-анализатора имеются две основные операции: перенос символа из входного потока в стек; свертка нескольких последовательных символов на вершине стека в некоторый нетерминал. Работа анализатора происходит так, что в стеке все время находится активный префикс некоторой правосентенциальной формы. При переносе символа и свертке на вершину стека кладется символ состояния sj конечного автомата V, кодирующий текущий активный префикс. LR-анализатор принимает решение о переносе или свертке, исходя из пары (символ sj, текущий токен входного потока). Анализатор завершает работу, когда в стеке оказывается стартовый символ грамматики.
к надежности которого чрезвычайно высоки.
Компилятор является инструментом, требования к надежности которого чрезвычайно высоки. И это неудивительно, ведь от правильности работы компилятора зависит правильность работы всех скомпилированных им программ. Из-за сложности входных данных и преобразований задача тестирования компиляторов является весьма трудоемкой и непростой. Поэтому вопрос автоматизации всех фаз тестирования (создания тестов, их прогона, оценки полученных результатов) стоит здесь особенно остро. Синтаксический анализ является частью функциональности любого компилятора. От корректности синтаксического анализа зависит корректность практически всей остальной функциональности – проверки семантических ограничений, оптимизирующих преобразований, генерации кода. Поэтому решение задачи тестирования синтаксических анализаторов является базой для решения задач тестирования всех остальных компонент компилятора. Для очень многих языков программирования существует формальное описание синтаксиса – описание грамматики языка в форме BNF, а для тех языков, для которых существуют только эталонные компиляторы (например, COBOL), делаются активные попытки построить такое описание (см.[9, 10, 14]). BNF языка является одновременно и спецификацией функциональности синтаксического анализа, таким образом, в этой области наиболее привлекательным является тестирование на основе спецификаций (см. [17]). Существование формального описания позволяет автоматизировать процесс построения тестов, что существенно снижает трудозатраты, а систематичность тестирования повышает доверие к его результатам. Построением тестов по грамматике занимались многие авторы. Основополагающей работой в этой области является работа [18], в которой сформулирован следующий критерий покрытия для множества позитивных тестов: для каждого правила в данной грамматике в множестве тестов должно присутствовать предложение языка, в выводе которого используется это правило. В той же работе Пардом предложил метод построения минимального тестового набора, удовлетворяющего этому критерию.
Однако указанный критерий оказался недостаточным. Ламмель в работе [9] показал, что тестовые наборы, построенные алгоритмом Пардома, не обнаруживают простейших ошибок. Ламмель также предложил более сильный критерий покрытия, состоящий в том, что покрывается каждая пара правил, одно из которых можно применить непосредственно после другого. Предлагаемые другими авторами методы являются вероятностными (см. [7, 13, 11, 12]) и не описывают критериев покрытия, и потому для них возникает вопрос остановки генерации тестов, который решается, например, с помощью введения вероятностей появления правил и уменьшения этих вероятностей при каждом новом появлении правила в выводе. В любом случае завершение работы алгоритма за конечное время является проблемой. Кроме того, произвольность остановки генерации нарушает систематичность тестирования. Все приведенные выше работы касаются генерации позитивных тестов для синтаксического анализатора (т.е. тестов, являющихся предложениями целевого языка). В настоящее время работы, предлагающие методы генерации негативных тестов для синтаксических анализаторов (т.е. тестов, не принадлежащих целевому языку), практически отсутствуют. Однако такие тесты также важны, поскольку пропуск неверной последовательности лексем на этапе синтаксического анализа может привести к аварийному завершению компиляции. В работе [8] высказано предположение, что если имеется генератор предложений языка из грамматики (генератор позитивных тестов для синтаксического анализатора), то для генерации негативных тестов для синтаксического анализатора можно использовать метод мутационного тестирования (mutation testing)1 (см. [6, 15]). Идея состоит в том, что в исходную грамматику вносятся изменения (мутации) для получения грамматик, описывающих близкие, но не эквивалентные исходному языки. Эти мутированные грамматики подаются на вход генератору тестов для получения потенциально негативных тестов. Общие проблемы данного подхода состоят в следующем: Грамматика-мутант может оказаться эквивалентной исходной грамматике.
Такие мутанты должны быть выявлены и не должны использоваться для генерации тестов. Даже если грамматика-мутант не эквивалентна исходной, полученные из нее тесты могут оказаться правильными. Выявить эти тесты можно лишь прогнав их через эталонный синтаксический анализатор, которого может и не быть (например, в случае создания нового или расширения существующего языка). В настоящей работе описаны критерии покрытия, нацеленные на алгоритмы синтаксического анализа. Такой подход представляется оправданным, поскольку тестовые наборы строятся для тестирования синтаксических анализаторов, и эффективность тестового набора должна оцениваться исходя из характеристик, относящихся к тестируемым компонентам (т.е. синтаксическим анализаторам), таких как, например, покрытие функциональности или кода. Данная методика разработана в рамках общего модельного подхода к тестированию компиляторов (см. [2, 3, 4]). Мы рассматриваем известные алгоритмы синтаксического анализа в качестве алгоритмов, моделирующих поведение синтаксического анализатора. Как уже говорилось, в литературе практически отсутствуют работы, посвященные генерации негативных тестов. Настоящая работа призвана закрыть этот пробел. Статья состоит из введения и трех разделов. В первом разделе содержатся сведения из теории алгоритмов синтаксического анализа. Второй раздел посвящен описанию предлагаемой методики. В нем вводятся понятия позитивных и негативных тестов, описываются критерии покрытия для тестовых наборов, опирающиеся на алгоритмы синтаксического анализа, а также приводятся алгоритмы построения наборов, удовлетворяющих этим критериям покрытия. В третьем разделе описаны результаты практического применения методики.
Анализаторы и метрики
Измерение тестового покрытия производится с помощью соответствующих анализаторов, которые делятся на две группы: инструментирующие исходный код и "бинарники". Принцип действия в обоих случаях состоит во вставке в код приложения вызовов специальных функций между инструкциями. Затем, во время работы приложения, подсчитывается количество вызванных функций, отношение которых к их общему числу и составляет коэффициент тестового покрытия.
Библиотеки для генерации mock-объектов позволяют автоматически создавать mock-объекты по заданному интерфейсу, а также определить ожидаемый порядок вызова и параметры функций mock-объектов.
Средства мутационного тестирования или вставки дефектов позволяют оценить качество тестов. Они работают с помощью инструментирования кода, модифицируя его таким образом, чтобы тесты заканчивались неудачно. Широкой практики применения таких средств у нас, к сожалению, пока не наработано.
Как и любая другая методология, TDD достаточно непросто встраивается в старые проекты. Технические и человеческие проблемы внедрения в общих чертах уже рассматривались; кроме того, существует ряд организационных моментов, о которых также хотелось бы упомянуть.
Прежде всего, для успешного внедрения необходима ясная, выраженная в цифрах задача. В случае TDD, как правило, задача сводится к достижению определенного коэффициента покрытия кода, что, в общем, удобно. Важно обеспечить доступность метрик, для этого хорошо использовать, например, e-mail reporting. Другой неплохо зарекомендовавший себя вариант - настенный график, отображающий колебания в coverage. Необходимым условием успешного применения метрик является регулярность их сбора. В идеале метрики должны собираться автоматически. Сбор метрик должен быть максимально прост, чтобы каждый программист мог самостоятельно оценивать результаты своей работы.
Чтобы тесты воспринимались всерьез, нужно делать их запуск частью стандартной процедуры сборки "билдов". Если тесты на собранном "билде" проходят неудачно, имеет смысл останавливать "билд".
Когда проект большой, а coverage стремится к нулю, модульное тестирование часто кажется бессмысленным из-за необъятности задачи (на доведение coverage до приемлемых значений пришлось бы потратить слишком большие усилия). Пытаться любой ценой повысить coverage в таких условиях, как правило, действительно крайне трудно, зато очень хорошо работает правило, запрещающее его снижать.
В этом случае тесты пишутся только тогда, когда затрагивается какой-либо код: во-первых, при написании нового кода; во-вторых, при рефакторинге; в-третьих, во время bug-fixing. Неплохо зарекомендовал себя подход, при котором весь новый код должен иметь coverage значительно больший, чем общепроектная норма, вплоть до 100%.
В заключение хочется подчеркнуть, что главный положительный эффект от TDD состоит в том, что этот стиль позволяет нам быть значительно более уверенными в своем коде. Как сказал Кент Бек, TDD - это способ управления страхом в программировании. Речь, конечно, не о том страхе, который порождается плохим владением предметной областью или инструментарием, здесь тесты не спасут. Но при решении сложных и очень сложных проблем модульное тестирование - один из лучших способов проявить разумную осторожность.
Модульное тестирование и Test-Driven Development, или Как управлять страхом в программировании
Сергей Белов,
менеджер проекта компании StarSoft Development Labs
, #21/2005
Модульное тестирование имеет довольно длинную по компьютерным меркам историю. Впервые о нем заговорили в 1975 году (именно тогда оно упоминается в знаменитом "Мифическом человеко-месяце" Брукса), затем в 1979-м его подробно описал в книге "The Art of Software Testing" Гленфорд Майерс. А через 12 лет, в 1987-м, IEEE приняла специальный стандарт модульного тестирования ПО.
Тем не менее наблюдаемый в последние годы рост популярности модульных тестов связан почти исключительно с распространением так называемых "легких" методологий, и особенно с экстремальным программированием. Начало этой тенденции положил Кент Бек своей книгой "Extreme Programming Explained", увидевшей свет в 1999 году, где, помимо прочего, были сформулированы основные идеи Test-Driven Development (TDD). Главная мысль автора очень проста: если тестирование - это хорошо, значит, программисты должны постоянно тестировать свой код. Набор рекомендаций, позволяющих добиться этой цели на практике, и составляет сегодня ядро TDD. Существует несколько распространенных определений TDD. Каждое из них акцентирует внимание на определенной стороне вопроса. В первом приближении удобно считать, что TDD - это методика разработки, позволяющая оптимизировать использование модульных тестов. Хочется подчеркнуть, что речь идет именно об оптимальном, а не максимальном применении. Задача, которую преследует TDD, - достижение баланса между усилиями и результатом.
Пять причин
В классическом XP тесты принято считать основным средством документирования кода, своего рода исполняемой спецификацией. Даже в том случае, если эта точка зрения кажется чересчур экстремальной, тесты можно применять по меньшей мере в качестве примеров использования кода. В отличие от настоящей документации тесты не могут не быть актуальными. Закономерный вопрос: если модульное тестирование в рамках TDD позволяет добиваться таких замечательных результатов, почему оно не было широко распространено до этого?
Известно пять основных причин, которыми люди объясняют свое нежелание тестировать. Все эти причины касаются модульного тестирования вообще, вне зависимости от методологий, и мы в XP с ними по-прежнему сталкиваемся. Разница между традиционным и экстремальным подходами состоит в том, что TDD предлагает разумные ответы для каждой из этих причин.
Начнем с самого простого аргумента типа "тестировать - не моя работа" или "тестеры и так все найдут". Он, как правило, выдвигается людьми, полагающими, что единственная задача модульного тестирования - снижение количества "багов". Возражения подобного рода обычно снимаются, когда удается объяснить, что TDD прежде всего помогает программистам, а не тестерам. Как только возражающая сторона осознает возможности модульного тестирования как инструмента разработки, такой аргумент, что называется, теряет силу.
Во-вторых, среди программистов бытует мнение, что тестировать - скучно. В рамках традиционного подхода, когда тесты пишутся после кода, для уже работающих модулей, тестировать действительно неинтересно. Нет ощущения, что создаешь что-то новое и полезное. Но в случае с "Test First" ситуация изменяется в противоположную сторону, и написание тестов превращается в дизайн методов, а дизайн - одна из самых увлекательных практик программирования. Кроме того, тесты дают возможность сразу ощутить положительный результат своего труда: цель находится не за горизонтом, а рядом и достижима очень быстро.
Программисты, постоянно практикующие "Test First", на скуку не жалуются.
Не менее часто приходится слышать что-нибудь вроде "модульное тестирование - это здорово, но времени на него у нас нет". Что ж, как уже говорилось, тестирование действительно увеличивает затраты времени на кодирование (по разным оценкам, на величину от 15 до 100%). С другой стороны, тестирование радикально сокращает затраты времени на:
отладку;
рефакторинг;
общение между программистами и тестерами по поводу "багов" и другие последствия попадания ошибок в очередной build.
Соотношение, как правило, складывается в пользу тестирования. Кроме того, необходимо учитывать, что кодирование тестов - это хорошо прогнозируемая по времени величина, в отличие от отладки или общения, оценить которые в лучшем случае сложно, а зачастую и невозможно. Таким образом, использование модульных тестов не только сокращает в общем и целом сроки разработки, но и делает их более предсказуемыми.
Иногда программисту кажется, что тот или иной класс или метод невозможно протестировать. Скорее всего, такому специалисту просто нужна помощь в нахождении технического решения. Несмотря на то что существуют области, традиционно считающиеся трудными для тестирования (GUI, к примеру), ситуаций, когда тестирование невозможно в принципе, пока не выявлено.
Вместе с тем в отдельных случаях дизайн модулей, классов или методов действительно мешает тестированию. Обычно это происходит в системах, где TDD вводится постфактум и где уже существует большое количество кода, не покрытого тестами. В такой ситуации перед тестированием приходится модифицировать существующий код. Часто удается ограничиться изменением областей видимости классов и методов.
Наконец, программисты порой не считают нужным тестировать, утверждая, что код, который они написали, работает и так. Иногда такая позиция оправдывается. Тем не менее необходимо помнить, что модульное тестирование надежно выявляет некоторые классы ошибок. Если код не тестировался, никто не может дать гарантии, что эти ошибки в нем отсутствуют.Кент Бек выражает эту же мысль более резко: единственное безопасное предположение, которое можно сделать относительно кода, который не тестировался, - это то, что он не работает.
Практические рекомендации
Причины, позволяющие программистам оправдать отсутствие тестов, сами по себе с введением TDD никуда не исчезают. Но TDD предоставляет простые средства, позволяющие почти полностью нейтрализовать их негативное влияние.
Перейдем к практическим рекомендациям. Несмотря на то что концепция модульного тестирования относительно проста, использование TDD в реальных проектах требует от программистов, и особенно от "техлидов", определенных навыков. Прежде всего, для успешного применения TDD необходимо умение собирать и интерпретировать некоторые стандартные тестировочные метрики. В XP-группе для оценки качества тестирования применяются:
коэффициент покрытия кода (code coverage); количество тестов; количество asserts; количество строк кода в модульных тестах; суммарное время исполнения тестов.Наиболее важный показатель - коэффициент тестового покрытия, или code coverage, измеряемый как отношение числа инструкций, выполненных тестами, к общему числу инструкций в модуле или приложении. Общий coverage приложения является основным средством оценки полноты модульного тестирования, и в нашем случае даже существует соглашение с заказчиком относительно его минимально допустимого уровня. Как правило, удовлетворительным считается coverage не ниже 75% или более, в зависимости от конкретного приложения. 100% сoverage не является чем-то из ряда вон выходящим и достаточно легко достигается при использовании "Test First". Использовать сoverage для оценки состояния модульных тестов следует осторожно. Эта метрика скорее позволяет выявить проблемы, чем указать на их отсутствие. "Плохие" значения coverage четко сигнализируют о том, что тестов в приложении недостаточно, в то время как "хорошие" значения не позволяют сделать обратного вывода. Проблема в том, что полнота тестов никак не связана с их корректностью. За рамками coverage остается также важный вопрос о диапазонах параметров функций. Тем не менее coverage удобно применять, с одной стороны, для общего наблюдения за тестированием в проекте, а с другой - для выявления не покрытых тестами участков кода.
Три других показателя обычно имеет смысл рассматривать вместе. В отличие от coverage, количество тестов, asserts и строк кода интереснее всего наблюдать в динамике. При нормальном использовании TDD все три значения должны расти ежедневно и равномерно, причины резких изменений необходимо выявлять.
Некоторый интерес представляет анализ отношений между этими и другими метриками: например, большая разница между количеством asserts и тестов может говорить о том, что тесты в среднем крупнее, чем нужно. Подтвердить или опровергнуть это утверждение может среднее количество строчек кода в тесте. Иногда имеет смысл рассматривать такие показатели, как среднее количество ежедневно добавляемых тестов, отношение тестов к основному коду по количеству строк и другие, но это скорее уже экзотика.
Время исполнения тестов выступает важной метрикой по двум причинам. Во-первых, резкое ухудшение времени исполнения тестов является достаточно надежным сигналом появления проблем с производительностью приложения. Во-вторых, чем дольше выполняются тесты, тем менее удобно с ними работать и тем реже программисты их запускают. Поэтому необходимо следить за тем, чтобы время работы тестов не увеличивалось по небрежности, а иногда имеет смысл даже прилагать некоторые усилия по их оптимизации.
В заключение разговора о метриках отмечу, что в XP-группе хорошо зарекомендовала себя практика их ежедневного автоматизированного сбора с рассылкой report'а команде. Анализом результатов, как правило, занимаются "PM" и "техлид". Метрики, несмотря на удобство работы с ними, в большинстве случаев не позволяют оценить тесты по целому ряду важных неформальных критериев. Поэтому существует набор требований к тестам, отслеживаемых, как правило, на code review. К ним относятся:
Простота. Тесты кроме всего остального должны объяснять код, который они используют, и делать это максимально прозрачно для постороннего человека образом. Правильное именование тестов. Существуют разные соглашения, но в любом случае название должно адекватно отражать суть теста. Не допускается зависимость тестов друг от друга или от порядка вызова.
Выполнение этого правила позволяет отлаживать тесты произвольными группами. Тесты должны быть атомарными, каждый из них должен проверять ровно один тестовый случай. Громоздкие и сложные тесты необходимо разбивать на несколько более мелких. Разумеется, к тестам применяются те же требования стандартов кодирования, что и к основному коду. Один из главных вопросов в модульном тестировании - что нужно тестировать и в каком объеме? Классический ответ TDD: тестировать нужно все, что потенциально может не работать. К сожалению, руководствоваться такой расплывчатой формулировкой в реальном проекте бывает не всегда просто. Наиболее практичный критерий - тестовое покрытие. Тестов должно быть написано как минимум столько, чтобы coverage находился в пределах нормы.
В соответствии с идеями TDD в большинстве случаев, кроме тестов, необходимых для обеспечения coverage, программисты пишут дополнительные тесты на ситуации, которые они по каким-либо причинам хотят проверить дополнительно. Такая практика приветствуется. Модульное тестирование, как уже отмечалось, не является "серебряной пулей" и может использоваться далеко не всегда. Так, например:
Обычно в модульных тестах не проверяется performance. С технической точки зрения, это можно делать, и некоторые тестировочные среды даже предоставляют для этого специальные средства. Но требования по производительности обычно указываются для приложения в целом, а не для отдельных функций; кроме того, performance testing часто занимает большое количество времени. Как правило, не имеет смысла тестировать чужой код и автоматически сгенерированный код. На уровне модульного тестирования часто тяжело или невозможно проверять сложные функциональные требования к приложению. Этим у нас занимаются тестеры с помощью автоматизации или ручного тестирования. Иногда в силу различных причин принимается решение вообще не тестировать ту или иную функциональность. Так, в XP-группе в настоящее время модульные тесты не пишутся для сборок, имплементирующих GUI, хотя технически это вполне возможно.
Модульное тестирование - это специфическая область программирования. Чтобы получить общее представление о его особенностях, рассмотрим некоторые паттерны, применяющиеся в программировании тестов.
Необходимость запускать тесты отдельными наборами заставляет использовать механизмы структурирования тестов. В зависимости от конкретной среды, тесты организуют либо в иерархические наборы (Boost Test Library), либо в пространства имен (NUnit). Многие frameworks, кроме того, предоставляют возможность задать категорию теста, это удобно для того, чтобы запускать тесты из разных веток одновременно. Правила категоризации тестов имеет смысл определять в стандартах кодирования.
Важнейшим паттерном модульного тестирования, поддерживаемым всеми развитыми frameworks, являются SetUp/TearDown-методы, предоставляющие возможность выполнения кода перед и после запуска теста или набора тестов. Как правило, существуют отдельные методы SetUp/TearDown уровня тестов и test suites. Важной и очень удобной возможностью являются SetUp/TearDown-методы для всех тестов (уровень сборки в терминах mbUnit).
Основная задача SetUp/TearDown - как правило, создание тестовых наборов данных. При тестировании кода, работающего с базами данных на запись, в этих методах производится backup и восстановление базы либо создаются и откатываются транзакции.
Mock-объекты - тестировочный паттерн, суть которого состоит в замене объектов, используемых тестируемым кодом, на отладочные эквиваленты. Например, для тестирования кода, обрабатывающего обрыв коннекции к базе данных, вместо настоящей коннекции можно использовать специальный mock-объект, постоянно выбрасывающий нужное исключение.
Mock-объекты удобно использовать, если:
заменяемый объект не обладает необходимым быстродействием; заменяемый объект тяжело настраивать; нужное поведение заменяемого объекта сложно смоделировать; для проверки call-back-функций; для тестирования GUI. Существуют библиотеки для динамической генерации Mock-объектов по заданным интерфейсам.
На практике регулярно приходится тестировать один и тот же код с разными комбинациями параметров. Row Test - это тестовая функция, принимающая несколько предопределенных наборов значений:
[RowTest] [Row("Monday", 1)] ... [Row("Saturday", 7)] public void TestGetDayOfWeekName(string result, int arg) { Assert.AreEqual(result, Converter.GetDayOfWeekName(arg)); } Combinatorial Test - тестовая функция, проверяющая код на всех возможных комбинациях для одного или нескольких массивов значений:
[Factory] public static int[] Numbers() { int[] result = { 1, ..., 9 }; return result; } [CombinatorialTest ] public void TestMultiplicationTable ( [UsingFactories("Numbers") int lhs, [UsingFactories("Numbers") int rhs) { Assert.AreEqual(lhs * rhs, Foo.Multiply(lhs, rhs)); } Прямая поддержка комбинаторного и строчного тестирования во framework серьезно облегчает тестирование чувствительного к параметрам кода. Хорошим примером такого framework является mbUnit.
Инструментарий модульного тестирования богат и разнообразен. Разница в ощущениях между использованием правильного и неправильного средства также будет большой. Не вдаваясь в описание конкретных продуктов, рассмотрим основные виды ПО, применяемого для модульного тестирования.
Главный инструмент модульного тестирования, конечно, unit test framework. Большинство современных framework базируются на дизайне, предложенном Беком в 1994 году в статье "Simple Smalltalk Testing". Задача framework - предоставлять библиотеки для создания тестов и средства их запуска. При выборе framework, с технической точки зрения, наиболее важно учитывать наличие необходимых клиентов (командная строка, GUI, модули для запуска из-под NAnt/Ant или IDE), поддержку используемых паттернов тестирования и reporting.
Поддержка тестирования из IDE в идеале должна включать в себя средства для запуска тестов по одному и группами с разной гранулярностью, под отладчиком и без него. Полезной является возможность измерения coverage для классов и сборок.Для применения "Test First" удобны средства генерации пустых определений для еще ненаписанных методов.
Три цвета
С практической точки зрения, основой TDD является цикл "red/green/refactor". В первой фазе программист пишет тест, во второй - код, необходимый для того, чтобы тест работал, в третьей, при необходимости, производится рефакторинг. Последовательность фаз очень важна. В соответствии с принципом "Test First", следует писать только такой код, который абсолютно необходим, чтобы тесты выполнялись успешно.

Попробуем проиллюстрировать этот цикл простейшим примером. Допустим, нам необходим метод, преобразующий числа от 1 до 7 в названия соответствующих дней недели. Следуя принципу "Test First", вначале пишем тест для этого метода:
[Test, ExpectedException(typeof(ArgumentException))] public void TestGetDayOfWeekNameInvalidArgument() { Converter.GetDayOfWeekName(8); }Затем, создаем метод-заглушку на тестируемом классе, необходимую для того, чтобы проект собрался:
static public string GetDayOfWeekName(int dayNumber) { return string.Empty; }Заглушку следует писать так, чтобы тест не выполнялся - это поможет удостовериться, что тест правильно реагирует на ошибку. Другая, более важная задача "красной" фазы состоит в том, чтобы в процессе написания теста определить сигнатуры тестируемых методов, порядок их вызова и другие особенности работы с ними. Как правило, имеет смысл начинать тестирование метода с наиболее общей, дефолтной ситуации, которая в нашем случае заключается в том, что в метод подаются числа, выходящие за пределы заданного диапазона. Поэтому мы пишем тест, который закончится удачно только в том случае, если тестируемый метод выбросит исключение заданного типа.
В "зеленой" фазе мы имплементируем и отлаживаем наш метод. При наличии альтернатив имеет смысл использовать самую простую имплементацию. Если возникает необходимость написать код, который не проверяется тестом, необходимо вернуться в красную фазу и исправить тесты.
static public string GetDayOfWeekName(int dayNumber) { throw new ArgumentException(); }Добившись успешного выполнения всех написанных тестов, просматриваем код в поисках потенциально полезных рефакторингов.
Чаще всего в этой фазе приходится убирать дублируемый код и изменять имена переменных, методов и классов. Иногда в фазе рефакторинга не нужно делать ничего, кроме повторного просмотра написанного кода. В данном случае мы имеем дело именно с такой ситуацией.
После завершения цикла "red - green - refactor" его нужно повторить для следующего участка функциональности. Для нас это случай, когда числа попадают в нужный диапазон. Пишем несложный тест и проверяем, что он не работает. Assert в модульных тестах является стандартным способом документировать наши предположения.
[Test] public void TestGetDayOfWeekName() { Assert.AreEqual("Monday", Converter.GetDayOfWeekName(1)); ... Assert.AreEqual("Saturday", Converter.GetDayOfWeekName(7)); }
В "зеленой" фазе мы снова заставляем тест работать.
static public string GetDayOfWeekName(int dayNumber) { switch (dayNumber) { case 1: return "Monday"; ... case 7: return "Saturday"; } throw new ArgumentException(); }
В заключительной фазе цикла иногда приходится полностью менять имплементацию. В частности, в нашем случае хотелось бы снизить цикломатическую сложность кода за счет замены switch'а на хэш-таблицу. Запуск тестов после рефакторинга докажет, что ничего не было сломано.
static public string GetDayOfWeekName(int dayNumber) { Hashtable ht = new Hashtable(); ht[1] = "Monday"; ht[7] = "Saturday"; string result = ht[dayNumber] as string; if (result == null) throw new ArgumentException(); return result; }
Как правило, цикл "red - green - refactor" должен занимать от 5 до 20 минут, хотя исключения, конечно, встречаются. Не следует работать в нескольких фазах одновременно: рефакторить код, например, в "красной" фазе неразумно. Чем больше тестов отлаживается в одном цикле, тем хуже; в идеале нужно работать только с одним тестом одновременно.
Обычно программистам, впервые сталкивающимся с "Test First", этот стиль кажется значительно более трудоемким.
Доля правды в этом, безусловно, есть: для тестирования все-таки приходится писать дополнительный код. Давайте попробуем разобраться, что мы приобретаем взамен.
Ранее считалось, что модульное тестирование имеет только одну цель - уменьшение количества "багов". XP значительно усиливает роль тестирования и выделяет пять его основных функций:
Традиционная: уменьшение количества "багов".
Поддержка низкоуровневого дизайна.
Поддержка рефакторинга.
Поддержка отладки.
Наконец, тест помогает документировать код.
Значение традиционной роли модульного тестирования в последнее время в TDD-сообществе обычно не подчеркивается. Часто можно встретить утверждения, что смысл TDD вообще не в тестировании и снижение количества ошибок - просто приятный побочный эффект. Связано это с тем, что, во-первых, этим эффектом значение тестирования действительно не исчерпывается, а во-вторых, в реальных программах никакое количество модульных тестов не в состоянии гарантировать полное отсутствие ошибок.
Конечно, модульные тесты отлично выявляют такие виды "багов", как бесконечный цикл, невыход из рекурсии, присвоение в неправильную переменную и многие другие. Из опыта хорошо известно, что в коде, для которого тесты существуют, дефектов всегда значительно меньше. Но кое-что после них все равно остается. Поэтому модульное тестирование должно быть дополнительной, а не окончательной линией защиты от ошибок.
Модульное тестирование, при некотором навыке, играет важную роль в качестве средства поддержки дизайна. Чтобы написать тест, необходимо детально продумать интерфейс проектируемого класса и протокол его использования. Что еще более важно, тестирование в рамках TDD позволяет получить простой способ оценки полноты интерфейсов: необходимым и достаточным считается такой интерфейс, который позволяет выполнить все написанные тесты. Все, что находится за этими рамками, считается ненужным. Наконец, использование тестов в качестве инструмента дизайна заставляет программиста в первую очередь концентрироваться на интерфейсе, а уже во вторую - на имплементации, что также положительно влияет на результат.
Значение тестов для рефакторинга переоценить невозможно. Любой, даже самый небольшой рефакторинг, как известно, требует наличия написанных тестов. Эта мысль важна настолько, что Мартин Фаулер в своей книге "Refactoring" посвятил модульному тестированию целую главу. Конечно, некоторые виды рефакторингов, такие, как, например, переименование полей, вполне возможно применять и без тестов. Но набор модульных тестов, покрывающих большую часть приложения, позволяет модифицировать систему значительно более агрессивно и со значительно более предсказуемыми результатами. Именно сочетание рефакторинга и тестов позволяет XP-программистам быстро изменять систему в любом нужном заказчику направлении. И именно поэтому мы можем позволить себе не искать гибких решений, а использовать самые простые (цена изменений при наличии тестов не слишком высока).
Разработчики знают, как тяжело порой бывает отладить какой-нибудь метод, глубоко закопанный в большом приложении. Иногда не удается проверить только что написанный код, потому что он еще нигде и никак не используется. Часто воспроизведение тестовой ситуации занимает чересчур много времени. В некоторых ситуациях программисты даже разрабатывают специальные утилиты, позволяющие отладить тот или иной компонент отдельно от всей системы.
При использовании модульных тестов подобных проблем просто не возникает. Если нужно что-нибудь проверить - пишем тест. Тесты, вообще говоря, представляют собой практически идеальную отладочную среду. Они находятся полностью под контролем программиста и при правильном применении позволяют вызвать любой код в широком диапазоне условий.
Кроме того, модульное тестирование ведет к сокращению общих затрат времени на отладку. Для большинства ошибок, найденных при модульном тестировании, отладка вообще не требуется, их видно сразу. Даже сложные "баги" отлаживать становится проще, поскольку точно известны место их возникновения (код, который был написан только что) и условия воспроизведения (тест, который сейчас отлаживается).Искать те же самые ошибки в работающем приложении почти всегда оказывается значительно более сложным и долгим делом.
Чем могут помочь модели
В голове разработчика и тестировщика всегда присутствует та или иная «модель» устройства программы, а также «модель» ее желаемого поведения, исходя из которой, в частности, составляются списки проверяемых свойств и создаются соответствующие тестовые примеры. (Заметим, что это разные модели; первые часто называют архитектурными, а вторые — функциональными или поведенческими.) Они зачастую составляются на основе документов или обсуждений в неформальном виде.
Разработка моделей и спецификаций связана с «математизацией» программирования. Попытки использовать различные математические подходы для конструирования и даже генерации программ предпринимались с первых лет возникновения компьютеров. Относительный успех был достигнут в теории компиляторов, реляционных баз данных и в нескольких узкоспециальных областях; серьезных результатов в большинстве практических областей достичь не удалось. Многие стали относиться к формальным методам в программировании скептически.
Новый всплеск интереса к формальным методам произошел в первой половине 90-х. Его вызвали первые результаты, полученные при использовании формальных моделей и формальных спецификаций в тестировании.
Преимущества тестирования на основе моделей виделись в том, что:
тесты на основе спецификации функциональных требований более эффективны, так как они в большей степени нацелены на проверку функциональности, чем тесты, построенные только на знании реализации; на основе формальных спецификаций можно создавать самопроверяющие (self-checking) тесты, так как из формальных спецификаций часто можно извлечь критерии проверки результатов целевой системы.Однако не было ясности в отношении качества подобных тестов. Модели обычно проще реализации, поэтому можно было предположить, что тесты, хорошо «покрывающие» модель, слишком бедны для покрытия реальных систем. Требовались широкие эксперименты в реальных проектах.
Модель — некоторое отражение структуры и поведения системы. Модель может описываться в терминах состояния системы, входных воздействий на нее, конечных состояний, потоков данных и потоков управления, возвращаемых системой результатов и т.д.
Для отражения разных аспектов системы применяются и различные наборы терминов. Формальная спецификация представляет собой законченное описание модели системы и требований к ее поведению в терминах того или иного формального метода. Для описания характеристик системы можно воспользоваться несколькими моделями в рамках нескольких формализмов. Обычно, чем более общей является нотация моделирования, тем больше трудностей возникает при автоматизации тестирования программы на основе модели/спецификации, описанной в этой нотации. Одни нотации и языки больше ориентированы на доступность и прозрачность описания, другие — на последующий анализ и трансляцию, в частности, трансляцию спецификации в тест. Предпринимались попытки разработки языка формальных спецификаций, удовлетворяющего требованиям промышленного использования (например, методология RAISE), однако широкого применения они не нашли.
Имеется несколько ставших уже классическими нотаций формальных спецификаций: VDM, Z, B, CCS, LOTOS и др. Некоторые из них, например, VDM, используются преимущественно для быстрого прототипирования. Язык B удобен для анализа, в частности для аналитической верификации моделей. Все эти языки активно используются в рамках университетских программ. В реальной практике для описания архитектурных моделей используется UML, а для построения поведенческих моделей — языки SDL/MSC, исполнимые диаграммы UML и близкие к ним нотации.
Перечисленные языки и нотации для поведенческих моделей, к сожалению, не обладают достаточной общностью. Они хорошо себя зарекомендовали в телекоммуникационных приложениях и практически бесполезны для описания функциональности программных систем «общего вида»: операционных систем, компиляторов, СУБД и т.д.
На роль инструментов разработки тестов для подобных систем претендует новое поколение средств описания моделей/спецификаций и средства генерации тестов на проверку согласованности поведения реализации заданной модели.
Инструменты тестирования на основе моделей
Test Real Time — один из первых представителей этой группы. Более широкие возможности предоставляет Jtest компании Parasoft. Интересен инструментарий компании Comformiq. Семейство инструментов разработки тестов на основе моделей предлагает Институт системного программирования РАН в кооперации с компанией ATS. Поскольку семейство UniTesK авторам знакомо существенно ближе, мы изложим общую схему подхода тестирования на основе моделей на примерах из UniTesK.
 |
| Рис. 1. Фазы процесса разработки спецификаций и тестов |
Общая схема процесса разработки спецификаций и тестов состоит из четырех фаз (рис. 1).
Первая фаза относительно коротка, но в реальных проектах она важна. Именно здесь закладывается уровень абстрактности модели. Модель должна быть максимально простой: это позволит требовать исчерпывающего набора тестов. В то же время, модель должна быть содержательной, раскрывать специфику тестируемой реализации. Таким образом, задача первой фазы — найти компромисс между абстрактностью и детальностью.
Задача второй фазы — описание требований к поведению системы. Многие подходы (например, SDL) предлагают описывать исполнимые модели, которые можно рассматривать как прототипы будущей реализации. Задание требований в таком случае определяется формулой «реализация должна вести себя так же, как модель». Подход понятен, но, к сожалению, во многих реальных ситуациях он не работает. Допустим, в заголовке некоего сообщения, построенного моделью, указано одно время, а в аналогичном заголовке от реализации — несколько другое. Это ошибка или нет? Еще один пример. Модель системы управления памятью сгенерировала указатель на свободный участок памяти, а реальная система выдала другой указатель: модель и система работают в разных адресных пространствах. Ошибка ли это?
Инструменты тестирования — реальная практика
Закончив экскурс в методику, вернемся к вопросу, какие инструменты тестирования используются в настоящее время и насколько они соответствуют новым представлениям о месте тестирования в процессе разработки программ.
На данный момент в наибольшей мере автоматизированы следующие этапы работ: исполнение тестов, сбор полученных данных, анализ тестового покрытия (для модульного тестирования обычно собирают информацию о покрытых операторах и о покрытых логических ветвях), отслеживание статуса обработки запросов на исправление ошибок.
Обзор инструментов тестирования будем вести в обратном порядке — от системного тестирования к модульному.
Широко распространены инструменты тестирования приложений с графическим пользовательским интерфейсом. Их часто называют инструментами функционального тестирования. Если уровень ответственности приложения не велик, то таким тестированием можно ограничиться; подобное тестирование наиболее дешево.
В данном виде тестирования широко применяются инструменты записи-воспроизведения (record/playback); из наиболее известных продуктов можно назвать Rational Robot (компания IBM/Rational), WinRunner (Mercury Interactive), QARun (Compuware). Наряду с этим существуют инструменты для текстовых терминальных интерфейсов, например, QAHiperstation компании Compuware.
Для системного нагрузочного тестирования Web-приложений и других распределенных систем широко используется инструментарий LoadRunner от Mercury Interactive; он не нацелен на генерацию изощренных сценариев тестирования, зато дает богатый материал для анализа производительности, поиска узких мест, сказывающихся на производительности распределенной системы.
Примерная общая схема использования инструментов записи-воспроизведения такова:
придумать сценарий (желательно, на основе систематического анализа требований); провести сеанс работы в соответствии с данным сценарием; инструмент запишет всю входную информацию, исходившую от пользователя (нажатия клавиш на клавиатуре, движения мыши и проч.), и сгенерирует соответствующий скрипт.Полученный скрипт можно многократно запускать, внося в него при необходимости небольшие изменения.
При записи скрипта можно делать
При записи скрипта можно делать остановки для того, чтобы указывать, какие ответы системы в конкретной ситуации надо рассматривать как правильные, какие вариации входных данных пользователя возможны и т.д. При наличии таких вариаций при очередном воспроизведении теста инструмент самостоятельно будет выбирать одну из определенных альтернатив. При несовпадении ответа системы с ожидаемым ответом будет фиксироваться ошибка.
Впрочем, возможности данного вида тестирования ограничены:
запись скриптов возможна только при наличии прототипа будущего графического интерфейса; поддержка скриптов очень трудоемка; часто скрипт легче записать заново, чем отредактировать; как следствие, проводить работы по созданию тестов параллельно с разработкой самой системы не эффективно, а до создания прототипа вообще невозможно. Следующий класс инструментов — инструменты тестирования компонентов. Примером является Test Architect (IBM/Rational). Такие инструменты помогают организовать тестирование приложений, построенных по одной из компонентных технологий (например, EJB). Предусматривается набор шаблонов для создания различных компонентов тестовой программы, в частности, тестов для модулей, сценариев, заглушек.
Отвечает ли этот инструмент требованию опережающей разработки тестов? В целом, да: для создания теста достаточно описания интерфейсов компонентов. Но есть и слабые места, которые, впрочем, присущи и большинству других инструментов. Так, сценарий тестирования приходится писать вручную. Кроме того, нет единой системы задания критериев тестового покрытия и связи этих критериев с функциональными требованиями к системе.
Последний из рассматриваемых здесь классов инструментов — инструменты тестирования модулей. Примером может служить Test RealTime (IBM/Rational), предназначенный для тестирования модулей на C++. Важной составляющей этого инструмента является механизм проверочных «утверждений» (assertion). При помощи утверждений можно сформулировать требования к входным и выходным данным функций/методов классов в форме логических условий, в аналогичной форме можно задавать инвариантные требования к данным объектов.Это существенный шаг вперед по сравнению с Test Architect. Аппарат утверждений позволяет систематическим образом представлять функциональные требования и на базе этих требований строить критерии тестового покрытия (правда, Test RealTime автоматизированной поддержки анализа покрытия не предоставляет).
В принципе, этим инструментом можно пользоваться при опережающей разработке тестов, но остается нереализованной все та же функция генерации собственно тестовых воздействий — эта работа должна выполняться вручную. Нет никакой технической и методической поддержки повторного использования тестов и утверждений.
Решение перечисленных проблем предлагает новое поколение инструментов, которые следуют подходу тестирования на основе модели (model based testing) или на основе спецификаций (specification based testing).
Новое качество, которое обещают новые инструменты
Как отмечалось выше, создатели инструментов тестирования обычно сталкиваются со следующими проблемами:
отсутствие или нечеткость определения критериев тестового покрытия, отсутствие прямой связи с функциональными требованиями; отсутствие поддержки повторного использования тестов; отсутствие автоматической генерации собственно теста (это касается как входных воздействий, так и эталонных результатов или автоматических анализаторов корректности реализации).Имеются ли у инструментов тестирования, которые для генерации теста используют модель или формальную спецификацию целевой системы, принципиальные преимущества перед традиционными средствами? Чтобы ответить на этот вопрос, укажем, как отмеченные проблемы решаются для инструментов, использующих модели.
Критерии тестового покрытия. Основной критерий — проверка всех утверждений, в частности, утверждений, определяющих постусловия процедур или методов. Он легко проверяется и легко связывается с функциональными требованиями к целевой системе. Так, инструменты UniTesK, инструменты для платформ Java и C# предоставляют четыре уровня вложенных критериев.
Повторное использование тестов. Уровень повторного использования существенно выше, чем у традиционных инструментов. Разработчик тестов пишет не тестовый скрипт, а критерии проверки утверждения и тестовый сценарий. И то, и другое лишено многих реализационных деталей, и поэтому их проще переиспользовать для новой версии целевой системы или для адаптации спецификаций и тестов для сходного проекта. Например, статистика UniTesK показывает, что уровень переиспользования для тестирования ядер разных операционных систем превышает 50%.
Автоматическая генерация тестов. Это главное достоинство новых инструментов; здесь они существенно опережают традиционные средства, поскольку используют не произвольные виды нотаций и методов моделирования и спецификации, а именно те, которые дают преимущества при автоматической генерации тестов. Так, утверждения позволяют сгенерировать тестовые «оракулы» — программы для автоматического анализа корректности результата; различные виды конечных автоматов или их аналоги позволяют сгенерировать тестовые последовательности.
К тому же, поскольку модели обычно проще, чем реализации, для них удается провести более тщательный анализ, поэтому набор тестов становится более систематическим.
Рассмотренные инструменты опробованы на реальных, масштабных проектах. Конечно, каждый проект несет в себе некоторую специфику, возможно, препятствующую исчерпывающему тестированию. Однако опыт использования данных инструментов показывает, что обычно удается достичь хороших результатов, лучших, чем результаты, полученные в аналогичных проектах при помощи ручного тестирования. Пользователи UniTesK, обычно, за приемлемый уровень качества принимают 70-80% покрытия кода целевой системы; при этом должен быть удовлетворен, как минимум, критерий покрытия всех логических ветвей в постусловиях. Для некоторых сложных программ (в том числе, для блока оптимизации компилятора GCC) был достигнут уровень покрытия 90-95%.
Есть ли принципиальные ограничения в применимости данного подхода? Его практически невозможно применять в случае, когда по той или иной причине никто в цепочке заказчик — разработчик — тестировщик не смог или не захотел четко сформулировать требования к целевой системе. Впрочем, это не только ограничение, но и дополнительный стимул для улучшения процессов разработки, еще один повод объяснить заказчику, что вложения в фазу проектирования с лихвой окупаются сокращением общих сроков разработки и стоимости проекта.
Литература
Уокер Ройс. Управление проектами по созданию программного обеспечения. М.: Лори, 2002. Г. Майерс. Надежность программного обеспечения. М.: Мир, 1980. Элфрид Дастин, Джефф Рэшка, Джон Пол. Автоматизированное тестирование программного обеспечения. Внедрение, управление и эксплуатация. М.: Лори, 2003. Everette R. Keith. Agile Software Development Processes: A Different Approach to Software Design, www.cs.nyu.edu/courses/spring03/V22.0474-001/lectures/agile/AgileDevelopmentDifferentApproach.pdf.
Александр Петренко, Елена Бритвина, Сергей Грошев, Александр Монахов, Ольга Петренко ({petrenko, lena, sgroshev, monakhov, olga} @ ispras.ru) — сотрудники Института системного программирования РАН.
Рис. 2. Спецификационные расширения языков программирования на примере спецификации требований к методу sqrt, вычисляющему квадратный корень из своего аргумента
Обозначения элементов общей структуры спецификации метода:
S — Сигнатура операции
A — Спецификация доступа
< — Предусловие
B — Определение ветвей функциональности
> — Постусловие
Java:
Class SqrtSpecification { S Specification static double sqrt(double x) A reads x, epsilon { < pre { return x >= 0; } post { > if(x == 0) { B branch «Zero argument»; > return sqrt == 0; > } else { B branch «Positive argument»; > return sqrt >= 0 && > Math.abs((sqrt*sqrt-x)/x)<epsilon; > } } } }
Си:
S specification double SQRT(double x) A reads (double)x, epsilon { < pre { return x >= 0.; } coverage ZP { if(x == 0) { B return(ZERO, «Zero argument»); } else { B return(POS, «Positive argument»); } } post { > if(coverage(ZP, ZERO)) { > return SQRT == 0.; > } else { > return SQRT >= 0. && > abs((SQRT*SQRT — x)/x) < epsilon; > } } }
C#:
namespace Examples { specification class SqrtSpecification { S specification static double Sqrt(double x) A reads x, epsilon { < pre { return x >= 0; } post { > if(x == 0) { B branch ZERO («Zero argument»); > return $this.Result == 0; > } else { B branch POS («Positive argument»); > return $this.Result >= 0 && > Math.Abs( ($this.Result * $this.Result — x)/x) < epsilon; > } > } > } } }
Подходы к улучшению качества программ
«Борьба за качество» программ может вестись двумя путями. Первый путь «прост»: собрать команду хороших программистов с опытом участия в аналогичных проектах, дать им хорошо поставленную задачу, хорошие инструменты, создать хорошие условия работы. С большой вероятностью можно ожидать, что удастся разработать программную систему с хорошим качеством.
Второй путь не так прост, но позволяет получать качественные программные продукты и тогда, когда перечисленные условия соблюсти не удается — не хватает хороших программистов, четкости в поставке задачи и т.д. Этот путь предписывает стандартизировать процессы разработки: ввести единообразные требования к этапам работ, документации, организовать регулярные совещания, проводить инспекцию кода и проч. Одним из первых продвижений на этом фронте стало введение понятия жизненного цикла программной системы, четко определявшее необходимость рассмотрения многих задач, без решения которых нельзя рассчитывать на успех программного проекта.
В простейшем варианте набор этапов жизненного цикла таков:
анализ требований; проектирование (предварительное и детальное); кодирование и отладка ("программирование"); тестирование; эксплуатация и сопровождение.Стандартизованная схема жизненного цикла с четкой регламентацией необходимых работ и с перечнем соответствующей документации легла в основу так называемой «водопадной» или каскадной модели. Водопадная модель подразумевает жесткое разбиение процесса разработки программного обеспечения на этапы, причем переход с одного этапа на другой осуществляется только после того, как будут полностью завершены работы на предыдущем этапе. Каждый этап завершается выпуском полного комплекта документации, достаточной для того, чтобы разработка могла быть продолжена другой командой. Водопадная модель стала доминирующей в стандартах процессов разработки Министерства обороны США. Многие волей или неволей, даже отклоняясь от этой модели, в целом соглашались с ее разумностью и полезностью.
Водопадная модель требовала точно и полно сформулировать все требования; изменение требований было возможно только после завершения всех работ.
Водопадная модель не давала ответ на вопрос, что делать, когда требования меняются или меняется понимание этих требований непосредственно во время разработки.
В конце 80-х годов была предложена так называемая спиральная модель, был развит и проверен на практике метод итеративной и инкрементальной разработки (Iterative and Incremental Development, IID). В спиральной модели были учтены проблемы водопадной модели. Главный упор в спиральной модели делается на итеративности процесса. Описаны опыты использования IID с длиной итерации всего в полдня. Каждая итерация завершается выдачей новой версии программного обеспечения. На каждой версии уточняются (и, возможно, меняются) требования к целевой системе и принимаются меры к тому, чтобы удовлетворить и новые требования. В целом Rational Unified Process (RUP) также следует этой модели.
Позволило ли это решить проблему качества? Лишь в некоторой степени.
Проблема повышения качества программного обеспечения в целом и повышения качества тестирования привлекает все большее внимание; в университетах вводят специальные дисциплины по тестированию и обеспечению качества, готовят узких специалистов по тестированию и инженеров по обеспечению качества. Однако по-прежнему ошибки обходятся только в США от 20 до 60 млрд. долл. ежегодно. При этом примерно 60% убытков ложится на плечи конечных пользователей. Складывается ситуация, при которой потребители вынуждены покупать заведомо бракованный товар.
Вместе с тем, ситуация не безнадежна. Исследование, проведенное Национальным институтом стандартов и технологии США, показало, что размер убытков, связанных со сбоями в программном обеспечении, можно уменьшить примерно на треть, если вложить дополнительные усилия в инфраструктуру тестирования, в частности, в разработку инструментов тестирования.
Каково же направление главного удара? Что предлагают «наилучшие практики»?
В 80-е и 90-е годы ответ на этот вопрос звучал примерно так. Наиболее дорогие ошибки совершаются на первых фазах жизненного цикла — это ошибки в определении требований, выборе архитектуры, высокоуровневом проектировании.
Поэтому надо концентрироваться на поиске ошибок на всех фазах, включая самые ранние, не дожидаясь, пока они обнаружатся при тестировании уже готовой реализации. В целом тезис звучал так: «Сократить время между моментом ‘внесения’ ошибки и моментом ее обнаружения». Тезис в целом хорош, однако не очень конструктивен, поскольку не дает прямых рекомендаций, как сокращать это время.
В последние годы в связи с появлением методов, которые принято обозначать эпитетом agile («шустрый», «проворный») предлагаются и внедряются новые конструктивные методы раннего обнаружения ошибок. Скажем, современные модели, такие как Microsoft Solutions Framework (MSF, www.microsoft.com/rus/msdn/msf) и eXtreme Programming (XP), выделяют следующие рекомендации к разработке тестов:
все необходимые тесты должны быть готовы к моменту реализации той или иной части программы; при этом обычно один тест соответствует одному требованию; совокупность ранее созданных тестов должна (при неизменных требованиях) выполняться на любой версии программы; если же в требования вносятся изменения, то тесты должны меняться максимально оперативно.
Иными словами, ошибка — будь она в требованиях, в проекте или в реализации — не живет дольше момента запуска теста, проверяющего реализацию данного требования. Значит, хотя астрономическое время между «внесением» ошибки и ее обнаружением может оказаться и большим, но впустую усилий потрачено не очень много, реализация не успела уйти далеко.
Не будем останавливаться на справедливости этих положений и их эффективности. Как часто бывает, побочный эффект новшества оказался более значимым, чем собственно реализация этой идеи. В данном случае дискуссии вокруг «шустрых» методов привели к новому пониманию места тестирования в процессе разработки программного обеспечения. Оказалось, тестирование в широком понимании этого слова, т.е. разработка, пропуск тестов и анализ результатов, решают не только задачу поиска уже допущенных в программном коде ошибок. Серьезное отношение к тестированию позволяет предупреждать ошибки: стоит перед тем, как писать код, подумать о том, какие ошибки в нем можно было бы сделать, и написать тест, нацеленный на эти ошибки, как качество кода улучшается.
В новых моделях жизненного цикла тестирование как бы растворяется в других фазах разработки. Так, MSF не содержит фазы тестирования — тесты пишутся и используются всегда!
Итак, различные работы в процессе производства программ должны быть хорошо интегрированы с работами по тестированию. Соответственно, инструменты тестирования должны быть хорошо интегрированы со многими другими инструментами разработки. Из крупных производителей инструментов разработки программ, первыми это поняли компании Telelogic (набор инструментов для проектирования, моделирования, реализации и тестирования телекоммуникационного ПО, базирующийся на нотациях SDL/MSC/TTCN) и Rational Software (аналогичный набор, преимущественно базирующийся на нотации UML). Следующий шаг сделала компания IBM, начав интеграцию возможностей инструментов от Rational в среду разработки программ Eclipse.
Тезис XP — «Пиши тест перед реализацией» — хорош как лозунг, но в реальности столь же неконструктивен. Для крупных программных комплексов приходится разрабатывать тесты различного назначения: тесты модулей, интеграционные или компонентные тесты, системные тесты.
Тестирование на основе моделей
Александр Петренко, Елена Бритвина, Сергей Грошев, Александр Монахов, Ольга Петренко
18.09.2003

Индустрия программного обеспечения постоянно пытается решить вопрос качества, но насколько значимы ее успехи, на данный момент сказать довольно сложно. В статье идет речь о новом поколении инструментов тестирования, которые призваны повысить качество программ. Однако инструменты, даже автоматические, не в состоянии помочь, если их используют неправильно. Поэтому обсуждение инструментов предваряет изложение общих положений «правильного» тестирования.
Три составляющие тестирования — экскурс в теорию
Модульному тестированию подвергаются небольшие модули (процедуры, классы и т.п.). При тестировании относительного небольшого модуля размером 100-1000 строк есть возможность проверить, если не все, то, по крайней мере, многие логические ветви в реализации, разные пути в графе зависимости данных, граничные значения параметров. В соответствии с этим строятся критерии тестового покрытия (покрыты все операторы, все логические ветви, все граничные точки и т.п.).
Проверка корректности всех модулей, к сожалению, не гарантирует корректности функционирования системы модулей. В литературе иногда рассматривается «классическая» модель неправильной организации тестирования системы модулей, часто называемая методом «большого скачка». Суть метода состоит в том, чтобы сначала оттестировать каждый модуль в отдельности, потом объединить их в систему и протестировать систему целиком. Для крупных систем это нереально. При таком подходе будет потрачено очень много времени на локализацию ошибок, а качество тестирования останется невысоким. Альтернатива «большому скачку» — интеграционное тестирование, когда система строится поэтапно, группы модулей добавляются постепенно.
Распространение компонентных технологий породило термин «компонентное тестирование» как частный случай интеграционного тестирования.
Полностью реализованный программный продукт подвергается системному тестированию. На данном этапе тестировщика интересует не корректность реализации отдельных процедур и методов, а вся программа в целом, как ее видит конечный пользователь. Основой для тестов служат общие требования к программе, включая не только корректность реализации функций, но и производительность, время отклика, устойчивость к сбоям, атакам, ошибкам пользователя и т.д. Для системного и компонентного тестирования используются специфические виды критериев тестового покрытия (например, покрыты ли все типовые сценарии работы, все сценарии с нештатными ситуациями, попарные композиции сценариев и проч.).
UniTesK — унифицированное решение
UniTesK предлагает использовать так называемые неявные спецификации или спецификации ограничений. Они задаются в виде пред- и постусловий процедур и инвариантных ограничений на типы данных. Этот механизм не позволяет описывать в модели алгоритмы вычисления ожидаемых значений функций, а только их свойства. Скажем, в случае системы управления памятью модель будет задана булевским выражением в постусловии типа «значение указателя принадлежит области свободной памяти». Простой пример постусловия для функции «корень квадратный» приведен на риc. 2; одна и та же спецификация представлена в трех разных нотациях: в стиле языков Cи, Java и C#. Использование спецификационных расширений обычных языков программирования вместо классических языков формальных спецификаций — шаг, на который идут почти все разработчики подобных инструментов. Их различает только выразительная мощность нотаций и возможности анализа и трансляции спецификаций.
Третья фаза — разработка тестового сценария. В простейшем случае сценарий можно написать вручную, но в данной группе инструментов — это плохой тон. Тест, т.е. последовательность вызовов операций целевой системы с соответствующими параметрами, можно сгенерировать, отталкиваясь от некоторого описания программы или структуры данных. Будем называть такое описание сценарием. Компания Conformiq предлагает описать конечный автомат. Различные состояния автомата соответствуют различным значениям переменных целевой системы, переходы — вызовам операций этой системы. Определить автомат — это значит для каждого состояния описать, в какое состояние мы перейдем из данного, если обратимся к любой наперед заданной операции с любыми наперед заданными параметрами. Если такое описание получить легко, больше ничего делать не понадобится: инструмент сгенерирует тест автоматически и представит результаты тестирования, например, в виде MSC-диаграмм. Но легко ли это, скажем, для программы с одной целочисленной переменной и двумя-тремя операциями? Скорее всего, да. Однако в общем случае сделать попросту невозможно.
В UniTesK для генерации тестовых последовательностей конечный автомат не описывается, а генерируется по мере исполнения теста. Все, что требуется от разработчика теста, — это задание способа вычисления состояния модели на основании состояния целевой системы и способа перебора применяемых в текущем состоянии тестовых воздействий. Эти вычисления записываются в тестовых сценариях. Очередное тестовое воздействие выбирается на основании спецификации сценария в зависимости от результатов предыдущих воздействий. Такой подход обладает двумя важными преимуществами. Во-первых, это позволяет строить сложные тестовые последовательности в чрезвычайно компактной и легкой для написания и понимания форме. Во-вторых, тесты приобретают высокую гибкость: они легко могут быть параметризованы в зависимости от текущих потребностей тестирования и даже могут автоматически подстраиваться под незначительные изменения модели. На рис. 3 приведен пример сценарного метода.
 |
| Рис. 3. Пример сценарного метода, тестирующего вставку элемента в очередь с приоритетами |
В UniTesK используется единая архитектура тестов, подходящая для тестирования систем различной сложности, относящихся к разным предметным областям, и обеспечивающая масштабируемость тестов. Компоненты тестов, требующие написания человеком, отделены от библиотечных и генерируемых автоматически (см. рис. 4).
В реальных системах количество различимых состояний и количество допустимых в каждом из них тестовых воздействий очень велико, что приводит к комбинаторному «взрыву состояний».
Для борьбы с этим эффектом разработан механизм факторизации модели: те состояния целевой системы, различие между которыми несущественно с точки зрения задач данного теста, объединяются в одно обобщенное состояние модели; аналогичным образом объединяются в группы и тестовые воздействия. Процесс факторизации предоставляет разработчику свободу творчества, но, вместе с тем, он поддержан строгими исследованиями, определяющими достаточные условия, при соблюдении которых гарантированы корректность результатов и существенное сокращение времени тестирования при сохранении достигаемого тестового покрытия.
 |
| Рис. 5. Использование UniTesK в среде разработки Forte 4.0 |
Аннотация
Рассматриваются вопросы использования типовых решений (паттернов проектирования) для построения тестовых программ, основанных на обобщенных моделях тестируемых систем в форме неявно заданных конечных автоматов. В качестве базовой технологии применяется технология UniTesK [1].
Использование в проектах
Количество файлов в директории; количество выделенных идентификаторов; количество выделенных семафоров; количество элементов меню; количество слушателей сообщений интерфейса (action listeners); количество элементов списка (List); размер списка ожидающих обработки операций send, receive; количество сообщений в очереди; количество синхронизированных потоков (joined threads); количество потоков, которые могут быть синхронизированы (joinable); количество отмененных (canceled), заблокированных (blocked), отсоединенных (detached) потоков.
Размер множества свободных идентификаторов; размер множества ресурсов разделяемой памяти; размер множества выделенных буферов (allocated buffers); размер пула выделенных ресурсов; размер пула выделенных процессов; размер пула выделенных семафоров; размер множества активных RMI-объектов; размер множества идентификаторов активных RMI-объектов; размер множества дескрипторов очереди сообщений.
Произведение количества свободных ресурсов и количества выделенных ресурсов; количество свободных элементов в каждом пуле из списка; произведение количества выделенных элементов и множества идентификаторов; произведение количества слушателей и количества уникальных слушателей; количество элементов в списке для каждого списка из набора; произведение типа упорядочивания в отображении и размера отображения; произведение зарегистрированных RMI объектов и количества активных объектов RMI; произведение количества зарегистрированных и количества пересоздаваемых при перезапуске RMI-объектов; произведение количества зарегистрированных и количества экспортированных RMI-объектов; произведение глубины дерева, количества компаний и количества активных компаний; произведение типа доступа к очереди сообщений и ее размера; произведение максимального размера очереди, максимального размера сообщения и размера очереди; произведение количества ждущих вызовов send, receive, максимального размера очереди, размера очереди и типа блокировки; произведение количества заявок, количества заявок ожидающих обработку и количества заявок находящихся в обработке.
Паттерн использовался для деревьев, представляющих иерархию компаний, в которой дочерние компании присутствовали как в основной, так и в альтернативной иерархии. В качестве обобщенного состояния выбиралось мультимножество пар: количество дочерних компаний в основной иерархии и количество дочерних компаний в альтернативной иерархии.
Паттерн использовался для тестирования модели данных Service Data Objects, представляющей собой дерево со ссылками, в котором можно хранить XML-данные, реляционные данные, EJB. В качестве обобщенного состояния выбиралось мультимножество пар: количество дочерних вершин, количество ссылок на другие вершины.
Итерация параметров методов
Может использоваться простая итерация элементов списка, их конструирование. Обязательно присутствие методов, добавляющих элементы в список, увеличивающих длину списка, а также методов, удаляющих один или несколько элементов списка.
Допустимо использовать обобщение переходов. Обобщение в простом случае существенно сокращает количество переходов. В более сложных случаях обобщение позволяет побороть недетерминизм, возникающий при зависимости методов добавления и удаления от свойств элементов списка.
Для итерации параметров предпочтительнее использовать обобщение параметров по ветвям функциональности, соответствующим наличию или отсутствию во множестве добавляемого или удаляемого элемента.
Для обеспечения более детального покрытия, нежели покрытие ветвей, может использоваться сочетание обобщений по ветвям и по более детальному покрытию. В случае недетерминированности обобщенных переходов по более детальному покрытию обобщение по ветвям обеспечивает существование детерминированного подавтомата и позволяет использовать обходчик детерминированных подавтоматов.
В сочетании с обобщением параметров, обеспечивающих существование детерминированного подавтомата, может использоваться и простая итерация параметров. Такая итерация, как правило, обеспечивает большее число различных переходов и позволяет покрыть более разнообразные тестовые ситуации, например, тестовые ситуации, зависящие от элементов множества.
В итерациях обязательно присутствие методов, добавляющих элементы во множество, увеличивающих размер множества, а также методов, удаляющих один или несколько элементов множества.
Вообще говоря, итерация параметров зависит от элементов произведения и в каждом случае выбирается по-разному. Однако существует два достаточно распространенных случая.
Первый случай - произведение одинаковых обобщенных состояний, являющихся обобщением одинаковых структур. В этом случае к итерации параметров для каждого метода добавляется итерация по структурам, составляющим элементы произведения.
Второй случай - произведение разных обобщений одной и той же структуры. В этом случае итерации в ряде случаев можно оставить неизменными.
Будем считать, что интерфейс содержит методы add, delete и createRoot. У метода add имеются два параметра: вершина, к которой нужно добавить ребенка, и добавляемая вершина. Метод требует, чтобы вершина, к которой добавляется ребенок, существовала. У метода delete имеется один параметр - удаляемая вершина. Можно выделить две разновидности метода: метод удаляет только листовые вершины, метод удаляет все поддерево, корнем которого является заданная вершина. Метод createRoot создает корневую вершину; вершину можно создать, если дерево пусто.
Описанные таким образом методы оказываются детерминированными, так как по заданному дереву и набору параметров любого метода однозначно определяется вид результирующего дерева.
Легко видеть, что итерация вершин дерева в качестве параметров методов описывает недетерминированный автомат. На показано обобщенное состояние {0, 1, 1} и два соответствующих ему дерева, которые различаются порядком вершин. В этом обобщенном состоянии переход, соответствующий вызову метода add(C, D) , может переводить автомат как в обобщенное состояние {0, 1, 1, 1} так и в обобщенное состояние {0, 0, 1, 2} в зависимости от дерева, соответствующего исходному обобщенному состоянию.
Этот недетерминизм легко преодолеть, заменив итерацию вершин итерацией различных элементов мультимножества обобщенного состояния. Элементу мультимножества при выполнении перехода ставится в соответствие произвольная вершина дерева с заданным числом непосредственных детей.
Таким образом, имеем следующие переходы: add(i, A) ; delete(i) ; createRoot(A) ,
где i - элемент мультимножества обобщенного состояния, А - добавляемая вершина.
Переходы по методу add становятся детерминированными, так как мультимножество после перехода определяется однозначно: выбранный элемент мультимножества заменяется большим на единицу, и дополнительно к мультимножеству добавляется нуль (см. ).
Однако переходы по методу delete по-прежнему оказываются недетерминированными. В примере, показанном на , в состоянии {0, 0, 1, 2} результирующее состояние при удалении вершины без детей зависит от того, сколько было детей у родителя.
Краткое описание
В качестве обобщенного состояния выбирается длина списка, присутствующего в модельном состоянии или сконструированного на его основе.
В качестве обобщенного состояния выбирается размер множества, присутствующего в модельном состоянии или сконструированного на его основе.
В качестве обобщенного состояния выбирается произведение других обобщенных состояний.
В качестве обобщенного состояния выбирается мультимножество, элементами которого являются числа - количество непосредственных детей для каждой вершины дерева.
Литература
| 1. | В.В. Кулямин, А.К. Петренко, А.С. Косачев, И.Б. Бурдонов. Подход UniTesK к разработке тестов. Программирование, 29(6): 25-43, 2003. |
| 2. | Б. Бейзер. Тестирование черного ящика. Технологии функционального тестирования программного обеспечения и системы. Питер, 2004. |
| 3. | D. Lee and M. Yannakakis. Principles and methods of testing finite state machines - a survey. Proceedings of the IEEE, volume 84, pp. 1090-1123, Berlin, Aug 1996. |
| 4. | H. Robinson. Graph Theory Techniques in Model-Based Testing. Proceedings of the International Conference on Testing Computer Software, 1999. |
| 5. | S. Rosaria, H. Robinson. Applying Models in your Testing Process. Information and Software Technology. Volume 42, Issue 12, Sept. 2000. |
| 6. | W. Grieskamp, Y. Gurevich, W. Schulte, and M. Veanes. Generating Finite State Machines from Abstract State Machines. ISSTA 2002, International Symposium on Software Testing and Analysis, July 2002. |
| 7. | H. Robinson. Intelligent Test Automation. Software Testing and Quality Engineering, September/October 2000, pp. 24-32. |
| 8. | C. Alexander, S. Ishikawa, M. Silverstein, M. Jacobson, I. Fiksdahl-King, S. Angel. A Pattern Language. Oxford University Press, New York, 1977. |
| 9. | Э. Гамма, Р. Хелм, Р. Джонсон, Дж. Влиссидес. Приемы объектно-ориентированного проектирования. Паттерны проектирования. Спб: Питер, 2001. |
| 10. | I. Bourdonov, A. Kossatchev, A. Petrenko, and D. Galter. KVEST: Automated Generation of Test Suites from Formal Specifications. FM'99: Formal Methods. LNCS 1708, Springer-Verlag, 1999, pp. 608-621. |
| 11. | I. Bourdonov, A. Kossatchev, V. Kuliamin, and A. Petrenko. UniTesK Test Suite Architecture. Proc. of FME 2002. LNCS 2391, pp. 77-88, Springer-Verlag, 2002. |
| 12. | И.Б. Бурдонов, А.С. Косачев, В.В. Кулямин. Применение конечных автоматов для тестирования программ. Программирование, 26(2):61-73, 2000. |
| 13. | |
| 14. | I.B. Bourdonov, A.V. Demakov, A.A. Jarov, A.S. Kossatchev, V.V. Kuliamin, A.K. Petrenko, S.V. Zelenov. Java Specification Extension for Automated Test Development. Proceedings of PSI'01. LNCS 2244, pp. 301-307. Springer-Verlag, 2001. |
| 1(к тексту) | Работа поддержана грантом РФФИ (05-01-999). |
Область применения
Применяется для присутствующих в модельном состоянии списка, очереди, стека и любых других перечислений. Использование паттерна предполагает, что тестовые ситуации не зависят от элементов списка. Для покрытия разнообразных элементов списка предполагается использование дополнительных технических приемов: дополнительных сценарных методов, паттерна выделение элементов.
Применяется для множества, присутствующего в модельном состоянии, или сконструированного на его основе. Использование паттерна предполагает, что тестовые ситуации не зависят от элементов множества. Для покрытия ситуаций, зависящих от элементов множества, предполагается использование дополнительных технических приемов: дополнительных сценарных методов, паттерна выделение элементов.
Применяется совместно с другими паттернами. Позволяет объединять тестовые ситуации, задаваемые элементами декартова произведения. При увеличении количества элементов декартова произведения количество состояний резко возрастает. Если между состояниями нет зависимостей, то количество состояний произведения есть произведение количеств состояний, задаваемых каждым элементом. Опыт показывает, что допустимо произведение лишь небольшого числа элементов, в пределах десяти.
Применяется при тестировании программ, для описания поведения которых в качестве состояния спецификации используется дерево. Считается, что в спецификации описаны методы, позволяющие изменять структуру дерева и свойства узлов.
Обобщенное состояние
Используется целочисленное или натуральное состояние 0, 1, 2, … . Функция вычисления обобщенного состояния возвращает количество элементов списка. Для обеспечения конечности обобщенных состояний вводится ограничение на количество состояний, задаваемое как параметр сценария.
Используется целочисленное или натуральное состояние 0, 1, 2, … . Функция вычисления обобщенного состояния возвращает количество элементов множества. Для обеспечения конечности обобщенных состояний вводится параметр сценария, который может задавать ограничение как на количество состояний, так и на количество разнообразных элементов, итерируемых в сценарных методах.
Тип состояния зависит от типов элементов произведения. В общем случае можно пользоваться PairComplexGenState и ListComplexGenState, конструируемыми из пары и списка обобщенных состояний соответственно. Для произведения целочисленных состояний можно пользоваться классами обобщенных состояний IntPairGenState, IntTripleGenState, IntListGenState.
В качестве обобщенного состояния выбирается мультимножество, элементы которого - количество непосредственных дочерних вершин. Рассмотрим пример.
На рис. 7 показаны два дерева, в которых одна вершина имеет две дочерних, одна имеет одну дочернюю, и две вершины в каждом дереве не имеют дочерних вершин. Таким образом, обоим этим деревьям соответствует одно и тоже обобщенное состояние, мультимножество {0,0,1,2}.

Рис. 7. Примеры деревьев
Результаты подсчета количества обобщенных состояний в зависимости от числа вершин приведены в таблице 2. Как видно, количество обобщенных состояний значительно меньше числа корневых деревьев для того же числа вершин. Это делает данное обобщенное состояние практически пригодным для использования при тестировании.
| Число корневых деревьев | 1 | 9 | 719 | 87811 | 12826228 | 2067174645 |
| Число обобщенных состояний | 1 | 5 | 30 | 135 | 490 | 1575 |
Таблица 2. Количество обобщенных состояний
Вместе с тем, данное обобщенное состояние определяет разнообразные виды деревьев. Мультимножества вида {0, …, 0, N}, где N - количество вершин определяют широкие деревья, а мультимножества вида {0, 1, …, 1} определяют высокие деревья.
Описание паттернов
В этом разделе приводятся подробные описания четырех паттернов: длина списка, размер множества, декартово произведение и мультимножество чисел детей.
Паттерн размер отображения очень похож на паттерн размер множества применительно к множеству ключей отображения, отличие состоит только в дополнительной итерации значений отображения при добавлении элементов.
Паттерны число вершин дерева и код дерева - это упрошенные версии паттерна мультимножество чисел детей. Первый паттерн не покрывает деревья разнообразной структуры, однако позволяет тестировать деревья с большим количеством вершин. Второй паттерн позволяет протестировать деревья всевозможных структур, однако применим лишь для небольшого числа вершин.
Паттерн среднее состояние позволяет тестировать достижение максимального количества элементов в различных структурах данных (списках, множествах, отображениях, деревьях) за счет объединения всех промежуточных состояний между максимальным и минимальным состояниями в одно обобщенное состояние.
Паттерн единственное состояние применяется для тестирования методов, не зависящих от состояния, и для построения простого тестового сценария, в котором разнообразие покрываемых тестовых ситуаций полностью зависит от выбора итераций параметров методов.
Паттерн выделение элементов основан на выделении элементов, обладающих некоторыми свойствами. Он применяется совместно с другими паттернами: длина списка, размер множества, размер отображения, число вершин дерева и другими. Цель применения - покрытие тестовых ситуаций, зависящих от свойств элементов. Данный паттерн может применяться совместно с паттерном декартово произведение с целью достижения детерминизма.
Понятие паттерна
Паттерны представляют собой удачные решения часто встречающихся задач. Там, где использование процесса разработки тестового сценария приводит к хорошему результату, паттерны позволяют повторно использовать полученные результаты. Там, где использование процесса затруднительно, знание паттернов позволяет выделить части, к которым они применимы. Паттерны позволяют использовать инструментальную поддержку.
Паттерны, описываемые в данной статье, получены на основе анализа более чем десятилетнего опыта разработки тестов ИСП РАН [] в различных проектах: Nortel Networks (ядро ОС); Luxoft (банковское приложение); Intel (стандартная библиотека Java); Microsoft Research (протокол IPv6); Вымпелком (детализация по счетам); НИИ системных исследований РАН (ОС 2000); Persistent (Service Data Objects, реализация BEA).
Было проанализировано около трехсот тестовых сценариев. В результате анализа проектов выделено десять наиболее распространенных паттернов. Названия выделенных паттернов, их краткая характеристика и статистика использования показаны в таблице 1.
| Длина списка | В качестве обобщенного состояния выбирается длина списка | 13% | 41% |
| Размер множества | В качестве обобщенного состояния выбирается размер множества | 17% | |
| Размер отображения | В качестве обобщенного состояния выбирается размер отображения | 8% | |
| Число вершин дерева | В качестве обобщенного состояния выбирается число элементов дерева | 3% | |
| Декартово произведение | В качестве обобщенного состояния выбирается декартово произведение других обобщенных состояний | 18% | 39% |
| Выделение элементов | Паттерн основан на выделении элементов обладающих некоторыми свойствами | 5% | |
| Единственное состояние | В качестве обобщенного состояния выбирается одно единственное состояние | 10% | |
| Мультимножество чисел детей | В качестве обобщенного состояния выбирается мультимножество, элементами которого являются числа - количество непосредственных детей для каждой вершины дерева | 3% | |
| Код дерева | В качестве обобщенного состояния выбирается код дерева, однозначно определяющий его структуру | 2% | |
| Среднее состояние | Все промежуточные состояния объединяются в одно обобщенное состояние | 1% | |
| ? (без паттерна) | 20% |
Таблица 1. Паттерны проектирования
Наиболее широкое применение имеет группа паттернов с размером структуры данных в качестве обобщенного состояния: длина списка, размер множества, размер отображения, число вершин дерева.
Эти паттерны используются в более чем половине случаев применения паттернов. В большой части паттернов явным образом определяется обобщенное состояние; это такие паттерны, как длина списка, размер множества, размер отображения, число вершин дерева, единственное состояние, мультимножество чисел детей, код дерева, среднее состояние. Оставшиеся два паттерна декартово произведение и выделение элементов явным образом состояние не определяют, а используются совместно с другими паттернами. Паттерны покрывают большинство распространенных структур данных: списки, множества, отображения, деревья. Для объединения нескольких обобщенных состояний, соответствующих разным структурам данных, используется паттерн декартово произведение. В паттерне выделение элементов учитываются свойства элементов, так как в остальных паттернах при выборе обобщенного состояния предполагается, что тестовые ситуации от свойств элементов не зависят. Описание каждого паттерна состоит из следующих частей:
название; краткое описание; область применения; обобщенное состояние; итерация параметров методов; примеры; совместное использование; использование в проектах.
Название служит для краткого именования паттерна. Область применения описывает ситуации, в которых применим описываемый паттерн, а также известные расширения паттерна. В части примеров приводятся простые и наглядные примеры применения паттернов; в данной статье примеры приводятся на расширении языка Java []. В части совместного использования приводятся паттерны, с которыми можно удачно использовать описываемый паттерн. Примеры использования паттерна в проанализированных проектах описанываются в части использования в проектах.
Метод удаляет элемент по индексу
List modelList; // Метод добавляет элемент e в список. void add(Integer e); // Метод удаляет элемент по индексу index из списка. // Если индекс выходит за границы списка, // вырабатывается исключение IndexOutOfBoundsException. void remove(int index) throws IndexOutOfBoundsException; Тестовые ситуации для метода add: список пуст; список не пуст. Тестовые ситуации для метода remove: индекс index отсутствует в списке; индекс index есть в списке: список пуст; список содержит единственный элемент; список содержит больше одного элемента. Обобщенное состояние - IntGenState, параметр конструктора - длина списка modelList: modelList.size(). Для ограничения количества состояний в сценарий добавляется переменная int maxSize. Для метода add с использованием конструкции iterate итерируются элементы списка - целые числа; итерация происходит, только если длина списка не превышает maxSize. Для метода remove итерируются индексы списка: scenario boolean add() { //objectUnderTest - модель, содержащая спецификационные методы //add и remove if(objectUnderTest.modelList.size()<maxSize) { iterate(int i=0; i<10; i++; ) { //вызов спецификационного метода add objectUnderTest.add(new Integer(i)); } } return true; } scenario boolean remove() { iterate(int i=-1; i<=objectUnderTest.modelList.size(); i++; ) { //вызов спецификационного метода remove objectUnderTest.remove(i); } return true; }
Set modelSet; // Метод добавляет элемент e в множество. void add(Integer e); // Метод удаляет элемент e из множества. // Если элемент присутствовал во множестве, возвращает true, иначе false. boolean remove(Integer e); Тестовые ситуации для метода add: множество пусто; множество не пусто: добавляемый элемент присутствует в множестве; добавляемый элемент отсутствует в множестве. Тестовые ситуации для метода remove: множество пусто; множество содержит единственный элемент: удаляемый элемент присутствует во множестве; удаляемый элемент отсутствует во множестве; множество содержит более одного элемента: удаляемый элемент присутствует во множестве; удаляемый элемент отсутствует во множестве. Обобщенное состояние - IntGenState, параметр конструктора - размер множества modelSet: modelSet.size(). Для ограничения количества состояний в сценарий добавляется переменная int maxSize. Для методов add и remove итерируются ветви функциональности, соответствующие отсутствию или присутствию элемента во множестве. Для каждой ветви перебираются элементы множества до тех пор, пока не будет найден элемент, попадающий в выбранную ветвь функциональности. Для ограничения количества обобщенных состояний итерация для метода add происходит, только если размер множества не превышает maxSize. scenario boolean add() { //objectUnderTest - модель, содержащая спецификационные методы //add и remove if(objectUnderTest.modelSet.size()<maxSize) { // 0 - элемент отсутствует во множестве // 1 - элемент присутствует во множестве iterate(int b=0; b<2; b++; ) { //поиск элемента, удовлетворяющего заданной ветви for(int i=0; i<10; i++) { Integer e = new Integer(i); if(b==0 && !objectUnderTest.modelSet.contains(e) b==1 && objectUnderTest.modelSet.contains(e)) { //вызов спецификационного метода add objectUnderTest.add(e); break; } } } } return true; } scenario boolean remove() { iterate(int b=0; b<2; b++; ) { //поиск элемента, удовлетворяющего заданной ветви for(int i=0; i<10; i++) { Integer e = new Integer(i); if(b==0 && !objectUnderTest.modelSet.contains(e)) { b==1 && objectUnderTest.modelSet.contains(e)) { //вызов спецификационного метода remove objectUnderTest.remove(e); break; } } } return true; }
Пример 1. Произведение длин списков. Спецификация описывает список, такой же, как в примере для паттерна Длина списка. List modelList; // Метод добавляет элемент e в список. void add(Integer e); // Метод удаляет элемент по индексу index из списка. // Если индекс выходит за границы списка, // вырабатывается исключение IndexOutOfBoundsException. void remove(int index) throws IndexOutOfBoundsException; В сценарии заводится массив ListMediator testLists[], в котором хранятся списки, сконструированные для тестирования. Т.е. в этом массиве хранятся те же объекты, что используются для тестирования одного списка (objectUnderTest), - медиаторы списков с присоединенными оракулами. Обобщенное состояние - IntListGenState. При конструировании обобщенного состояния производится итерация по элементам массива testList и добавляется длина каждого списка modelList: modelList.size(). Так же, как и для тестирования одного списка, вводится ограничение на максимальную длину всех списков int maxSize. Для тестирования методов добавления и удаления в сценарных методах итерируются тестируемые списки, а затем параметры методов, так же, как для одного списка. scenario boolean add() { iterate(int i=0; i<=objectUnderTest.testLists.length; i++; ) { objectUnderTest = testLists[i]; //objectUnderTest - модель, содержащая спецификационные методы //add и remove if(objectUnderTest.modelList.size()<maxSize) { iterate(int j=0; j<10; i++; ) { //вызов спецификационного метода add objectUnderTest.add(new Integer(j)); } } } return true; } scenario boolean remove() { iterate(int i=0; i<=objectUnderTest.testLists.length; i++; ) { objectUnderTest = testLists[i]; iterate(int j=-1; j<=objectUnderTest.modelList.size(); j++; ) { //вызов спецификационного метода remove objectUnderTest.remove(j); } } return true; } Пример 2. Активные идентификаторы. // Отображение из идентификаторов объектов в статус объекта. // true - объект активный, false - объект неактивный Map modelMap; // Метод связывает ключ key со значением value. // Если ключ присутствовал в отображении, // возвращает предыдущее значение, связанное ключом, // иначе возвращает null.
Tree modelTree; // Метод добавляет вершину node к вершине parent, // если parent есть в дереве. // Если вершины parent нет в дереве, вершина не добавляется. add(Node parent, Node node); // Метод удаляет вершину node, если таковая есть в дереве // и является листовой. // Иначе вершина не удаляется. delete(Node node); // Метод создает корневую вершину; вершину можно создать, // если дерево пусто. Node createRoot(); Тестовые ситуации для метода add: родитель не существует; родитель существует: родитель не имеет дочерних вершин; родитель имеет дочерние вершины. Тестовые ситуации для метода delete: вершина не существует; вершина существует: вершина не имеет дочерних вершин; вершина имеет дочерние вершины. Тестовые ситуации для метода createRoot: дерево пусто; дерево не пусто. Обобщенное состояние - мультимножество целых чисел IntMultisetGenState. Считаем, что имеется метод, возвращающий вершину дерева по номеру от нуля до числа вершин в дереве modelTree.getNodeByIndex(int index) . IntMultisetGenState genstate = new IntMultisetGenState(); for(int i=0; i<objectUnderTest.modelTree.size(); i++) { Node node = objectUnderTest.modelTree.getNodeByIndex(i); genstate.addElement(node.children().size()); } Для ограничения количества состояний в сценарий добавляется переменная int maxSize. Для метода add итерируем элементы мультимножества, и для каждого элемента подбираем вершину с соответствующим количеством детей. Считаем, что имеется функция, которая возвращает вершину с указанным количеством детей getNodeWithChildrenSize(int size) ; если таких вершин несколько, возвращается произвольная. Итерация происходит, если количество вершин не превышает maxSize. scenario boolean add() { //objectUnderTest - модель, содержащая спецификационные методы //add и delete if(objectUnderTest.modelTree.size()<maxSize) { IntMultisetGenState ms = getGenState(); //итерация элементов мультимножества iterate(IntegerIteratorInterface iter = ms.getIterator(); !iter.stopIteration(); iter.next(); ) { //подбор соответствующей вершины Node parent = objectUnderTest.modelTree.getNodeWithChildrenSize(iter.value()); //итерация добавляемых вершин iterate(int j=0; j<10; j++) { Node node = new Node(j); //вызов спецификационного метода add objectUnderTest.add(parent, node); } } } return true; } Для метода delete итерируются номера вершин дерева, а также вводится дополнительный сценарный метод, гарантированно удаляющий вершину.
Процесс разработки тестового сценария
В технологии UniTesK задание конечного автомата, на основе которого строится тестовая последовательность, вынесено в отдельный компонент - тестовый сценарий []. В тестовом сценарии задаются обобщенные состояния и итерации параметров методов. Обобщенные состояния определяют состояния конечного автомата и задаются с помощью функции, возвращающей обобщенное состояние на основе состояния модели. Таким образом, состояния модели разбиваются на классы с одинаковым обобщенным состоянием. Обобщенные состояния позволяют уменьшить количество состояний автомата. Итерации параметров методов задают перебор параметров, с которыми следует вызвать методы, определяя тем самым возможные переходы автомата. Однако при таком задании переходов состояние после выполнения метода неизвестно до вызова метода. Поэтому окончательный вид автомата определяется только в процессе обхода автомата.
На основе описания обобщенного состояния и итераций параметров методов специальный компонент тестовой системы, называемый обходчиком, строит обход переходов автомата, получая тестовую последовательность. В процессе обхода, выполняя вызовы методов, обходчик определяет окончания переходов автомата.
Процесс разработки тестового сценария начинается с определения тестовых ситуаций (рис. 1). Тестовая ситуация определяет множество состояний, метод, и наборы параметров при которых она может быть покрыта. Тестовая ситуация является достижимой в данном состоянии, если в этом состоянии существует такой набор параметров, что метод, вызванный с этим набором параметров в данном состоянии, покрывает эту ситуацию. Тестовые ситуации позволяют определить, какие состояния являются «интересными» для тестирования, а также судить о разнообразности обобщенных состояний. Обобщенные состояния являются разнообразными, если они позволяют покрыть выбранные тестовые ситуации.
Основным источником тестовых ситуаций является покрытие, определенное в спецификациях, так как именно оно является основным критерием завершенности тестирования в технологии UniTesK.
При определении тестовых ситуаций могут учитываться также дополнительные соображения, не нашедшие отражения при определении покрытия в спецификации. Например, если в качестве модельного состояния используются деревья, то дополнительным соображением может быть наличие разнообразных деревьев: высоких, широких, сбалансированных и т.д. Подобные свойства сложно отображать в спецификации. Другой пример дополнительного соображения - перебор значений свойства, не определяющего внешнее поведение реализации и, соответственно, не отраженнного в спецификации. Однако внутреннее поведение реализации может зависеть от этого свойства, используемого для оптимизации.

Очевидно, что обход, покрывающий все переходы автомата, покроет все возможные тестовые ситуации.


На данный момент в инструментах UniTesK есть пять видов обходчиков: базовый обходчик; обходчик детерминированных автоматов; обходчик детерминированных автоматов с функцией сброса; обходчик автоматов, имеющих детерминированный, сильно связный покрывающий подавтомат; обходчик сильно дельта-связных автоматов. Во всех этих обходчиках требуется, чтобы число состояний и переходов было конечно. В базовом обходчике не используется обобщенное состояние; считается, что у автомата имеется одно единственное состояние, и, таким образом, не накладываются какие-либо дополнительные ограничения. В обходчике детерминированных автоматов требуется, чтобы автомат, описываемый сценарием, был детерминированным и сильно связным. В обходчике детерминированных автоматов с функцией сброса требуется детерминированность автомата, а сильная связность обеспечивается с помощью функции сброса, задаваемой разработчиком сценария. Четвертый обходчик может работать с недетерминированными автоматами, однако в нем требуется, чтобы существовал детерминированный сильно связный подавтомат, который содержит все состояния исходного автомата. В последнем обходчике требуется, чтобы для любых двух состояний автомата существовала адаптивная тестовая последовательность, ведущая из одного состояния в другое. Заметим, что этому требованию заведомо удовлетворяют автоматы, содержащие детерминированный сильно связный покрывающий подавтомат. Для удовлетворения требований обходчиков можно использовать следующие методы: дробление состояний; введение связующих переходов; обобщение переходов. Метод дробления состояний описан в [] (в статье ему соответствуют алгоритмы 1 и 2 построения дельта детерминированного и вполне определенного фактор-графа). Здесь он называется методом дробления, так как его применение для заданного начального обобщения состояний и переходов приводит к разбиению состояний, принадлежащих одному обобщенному состоянию, на несколько непересекающихся групп, которые образуют новые обобщенные состояния ().
Использование метода дробления позволяет во многих случаях достичь детерминированности автомата. Многие предлагаемые в данной статье паттерны могут быть получены применением метода дробления. Однако для применения метода требуется представление модели в виде конечного автомата. Преставление модели в виде конечного автомата зачастую бывает слишком сложным из-за слишком большого числа получающихся состояний и переходов. Кроме того метод применим не для всех автоматов. Метод дробления может построить автомат, удовлетворяющий требованиям обходчика, однако число его состояний может быть слишком велико. Тогда для уменьшения количества состояний можно жертвовать разнообразностью состояний. Метод связующих переходов используется совместно с обходчиком автоматов, имеющих детерминированный, сильно связный покрывающий подавтомат. К уже имеющемуся недетерминированному переходу добавляется дополнительный детерминированный переход, гарантированно переводящий систему в заданное состояние. Например, если метод в зависимости от некоторых свойств переводит систему в два разных состояния, можно ввести дополнительный переход (сценарный метод), при выполнении которого перед вызовом метода свойства устанавливаются таким образом, чтобы перейти в требуемое состояние. На рис. 5 показан метод add, который в зависимости от некоторых свойств либо изменяет, либо не изменяет состояние. Для обеспечения существования детерминированного подграфа вводится сценарный метод add2, гарантированно переводящий систему в новое состояние.

рис. 6).

Совместное использование
Используется совместно с паттерном выделение элементов. Для тестирования списков при максимальном заполнении рекомендуется использовать паттерн среднее состояние.
Используется совместно с паттерном выделение элементов. Для тестирования максимального заполнения множества рекомендуется использовать паттерн среднее состояние.
Используется совместно с паттерном выделение элементов. Для элементов декартова произведения используются другие паттерны.
Используется совместно с паттерном выделение элементов. Для тестирования максимального количества вершин в дереве рекомендуется использовать паттерн среднее состояние.
В тестировании на основе моделей
В тестировании на основе моделей модели используются для нескольких целей: для проверки соответствия тестируемой системы требованиям, представленным в модели; для задания покрытия; для генерации тестовых данных. Нас, в первую очередь, будет интересовать последний случай - применение моделей для генерации тестовых данных. При тестировании на основе моделей широко распространенным подходом к генерации тестовых данных является представление системы в виде конечного автомата и генерация тестовой последовательности на основе его обхода [, , ]. Авторы, использующие конечные автоматы для тестирования, отмечают, что это позволяет повысить качество тестирования, улучшить сопровождаемость тестов [, ]. В работе [] отмечается, что использование конечных автоматов дает возможность получать последовательности, которые было бы сложно получить при применении других подходов. В отличие от ручного тестирования и тестирования с автоматизированным прогоном тестов, при использовании автоматов тестовая последовательность строится автоматически. В случайных тестовых последовательностях сложно управлять тестами, направлять их на проверку определенных требований. В результате часть важных требований может быть не проверена вовсе. В данной работе в качестве базовой технологии рассматривается технология UniTesK []. В UniTesK для генерации тестовых данных используются модели конечных автоматов, задаваемые в тестовых сценариях. Тестовая последовательность получается автоматически в результате обхода такого автомата. Для проверки требований и задания покрытия используются формальные спецификации. Технология UniTesK позволяет использовать только тестовые сценарии без спецификаций; при этом проверка требований и оценка покрытия может производиться в тестовом сценарии. Паттерны, описываемые в статье, могут применяться для разработки тестовых сценариев и без использования спецификаций. Однако обычно применение технологии предполагает наличие спецификации системы, и поэтому мы будем считать, что для задания требований используется спецификация, определяющая модельное состояние.
использующие конечные автоматы для тестирования
Методы, использующие конечные автоматы для тестирования программ, накладывают ограничения на приемлемые размеры автоматов, при которых они применимы на практике. В этом смысле не является исключением и технология UniTesK, в которой приемлемое количество состояний составляет несколько сотен. Для борьбы с разрастанием состояний в UniTesK используется обобщение состояний, задаваемое в тестовом сценарии. Выбор обобщенного состояния в тестовом сценарии - это поиск компромисса между количеством состояний, их разнообразием и возможностями обходчика, использующего это состояние для построения тестовой последовательности. Процесс разработки тестовых сценариев по технологии UniTesK является сложной задачей. Процесс затрудняется тем обстоятельством, что количество состояний модели велико, а порой и бесконечно. Построение автомата приемлемых размеров не гарантируется; кроме того, не для всех моделей можно построить автомат, удовлетворяющий требованиям обходчиков. Поскольку окончательный вид автомата определяется в процессе обхода, проверка требований обходчика до запуска тестов затруднительна, что еще больше усложняет задачу. В данной статье предложены паттерны проектирования, позволяющие упростить разработку тестовых сценариев. Паттерны получены в результате анализа более чем десятилетнего опыта разработки тестов ИСП РАН в семи различных проектах. Было проанализировано около трехсот тестовых сценариев. Статистика показывает, что выделенные паттерны используются в 80% тестовых сценариев и лишь в 20% требуются дополнительные соображения. Паттерны представляют собой удачные решения часто встречающихся задач. Паттерны позволяют повторно использовать полученные результаты, передать опыт разработчиков тестовых сценариев. Знание паттернов дает возможность начинающему разработчику сценариев работать так, как работает эксперт; помогает выделить в модели части, к которым применимы паттерны. Использование паттернов позволяет опираться на библиотечные обобщенные состояния и автоматическую генерацию итераций параметров, поддерживаемые в инструментах тестирования. При использовании паттернов тестировщик может больше сосредоточиться на написании спецификаций к системе, нежели на выборе обобщенного состояния и итераций, которые должны удовлетворять требованиям обходчиков, сложно проверяемым без экспериментов. Паттерны покрывают большинство распространенных структур данных: списки, множества, отображения, деревья. Такие структуры наиболее часто встречаются при моделировании систем. Это дает уверенность в том, что и в дальнейшем в большинстве случаев можно будет использовать выделенные паттерны.
