Аннотация.
Компиляторы преобразуют исходный текст программы на языке высокого уровня в вид, пригодный для исполнения. Ошибки в компиляторе чреваты отказами или ошибками при выполнении исполняемых файлов, построенных компилятором, поэтому обеспечение корректности функционирования компилятора является важнейшей задачей. Одна из особенностей компиляторов заключается в том, что они принимают на вход и выдают данные с очень сложной структурой, поэтому при проведении верификации на практике можно исследовать поведение компилятора лишь на небольшом подмножестве входных программ. В статье представлен подход к верификации компиляторов, основанный на декомпозиции общей задачи компилятора, и представлены методы решения выделенных задач. Представленный подход использовался при верификации различных индустриальных компиляторов и трансляторов.
Извлечение тестов
Инструмент SynTesK предоставляет возможность в полностью автоматическом режиме систематически генерировать наборы тестов, удовлетворяющих сформулированным выше критериям покрытия.
В качестве входных данных генератор тестов принимает формальное описание грамматики целевого языка в форме BNF.
Имеется инструментальная поддержка метода SemaTesK, которая позволяет в полностью автоматическом режиме систематически генерировать наборы тестов, удовлетворяющих сформулированным выше критериям покрытия.
В качестве входных данных генератор тестов принимает формальное описание структуры абстрактных синтаксических деревьев целевого языка на языке TreeDL, а также описание контекстных условий целевого языка на языке SRL.
Для извлечения тестов в рамках метода OTK требуется разработать генератор тестов.
Генератор тестов состоит из двух компонентов. Первый, называемый итератором, отвечает за последовательную генерацию модельных структур в соответствии с выбранным критерием полноты. Второй компонент, называемый меппером, отвечает за отображение каждой модельной структуры в соответствующую корректную программу на языке входных данных компилятора.
В рамках метода OTK предоставляется мощная инструментальная поддержка для формального описания модели данных, а также для разработки всех требующихся компонентов генератора тестов [].
Генератор, разработанный с помощью OTK, позволяет для целевого аспекта back-end'а в автоматическом режиме систематически генерировать тестовые наборы с целью достижения выбранного критерия полноты.
Тесты представляют собой конечные автоматы. С каждым переходом в автомате сопоставляется выдача тестового воздействия. Для текстового задания таких автоматов в используемых расширениях языков программирования предусмотрены специальные конструкции (тестовые сценарии, сценарные функции и итераторы), которые позволяют описывать автоматы в компактном виде.
Критерии полноты тестирования
Мы рассматриваем известные алгоритмы синтаксического анализа (LL-анализ и LR-анализ, построенные на основе стека - см. []) в качестве алгоритмов, моделирующих поведение парсера.
Критерий полноты набора позитивных тестов для тестирования LL-анализатора:
(PLL) Покрытие всех пар вида
(нетерминал A, допустимый следующий токен t),
где пара (A, t) считается покрытой тогда и только тогда, когда в тестовом наборе существует предложение языка, обрабатывая которое LL-анализатор придет в ситуацию, когда на вершине стека будет находиться символ A, а текущим входным символом будет токен t.
Критерий полноты набора позитивных тестов для тестирования LR-анализатора:
(PLR) Покрытие всех пар вида
(символ s состояния конечного автомата,
помеченный символом X переход из состояния s),
где пара (s, X) считается покрытой тогда и только тогда, когда в тестовом наборе существует предложение языка, обрабатывая которое LR-анализатор придет в ситуацию, когда на вершине стека будет находиться символ s, а началом текущего входного потока будет последовательность токенов, отвечающая символу X.
Критерий полноты набора негативных тестов для тестирования LL-анализатора:
(NLLR) Покрытие всех пар
(нетерминал A; «некорректный» токен t'),
где пара (A, t') считается покрытой тогда и только тогда, когда среди тестов имеется последовательность токенов, не принадлежащая целевому языку, такая что LL-анализатор, обрабатывая эту последовательность, придет в ситуацию, когда после обработки как минимум R «правильных» токенов, на вершине стека будет находиться символ A, а текущим входным символом будет «некорректный» токен t'.
Критерий полноты набора негативных тестов для тестирования LR-анализатора:
(NLRR) Покрытие всех пар
(символ s состояния конечного автомата; «некорректный» токен t'),
где пара (s, t') считается покрытой тогда и только тогда, когда среди тестов имеется последовательность токенов, не принадлежащая целевому языку, такая, что LR-анализатор, обрабатывая эту последовательность, придет в ситуацию, когда после обработки как минимум R «правильных» токенов, на вершине стека будет находиться символ s, а текущим входным символом будет «некорректный» токен t'.
Существует семейство алгоритмов генерации тестов, удовлетворяющих этим критериям. Их подробное описание можно найти в работе [].
Следует особо отметить следующее важное свойство предложенных в этой работе алгоритмов генерации негативных тестов: алгоритмы гарантированно строят тесты, не принадлежащие целевому формальному языку. Это свойство позволяет отказаться при построении оракула от использования каких бы то ни было эталонных синтаксических анализаторов.
Разработан инструмент SynTesK [], в котором реализованы алгоритмы, удовлетворяющие критериям PLL и NLL1, а также критерию NLR1 для некоторого специального вида грамматик [].
Инструмент SynTesK успешно применялся для тестирования компиляторов реальных языков программирования, в т.ч. C и Java []. Практические результаты этого применения показали эффективность реализованных в SynTesK алгоритмов.
Литература
| 1.обратно | CMMI for Systems Engineering/Software Engineering, Version 1.02 (CMMI-SE/SW, V1.02) CMU/SEI-2000-TR-018 ESC-TR-2000-018 November 2000, P. 598 |
| 2.обратно | A .Aho, R. Sethi, J. D. Ullman. Compilers. Principles, Techniques, and Tools // Addison-Wesley Publishing Company, Inc. - 1985. |
| 3.обратно | М.В. Архипова. Генерация тестов для семантических анализаторов // Вычислительные методы и программирование. 2006, том.7, раздел 2, 55-70. |
| 4.обратно | А.В. Баранцев, И.Б. Бурдонов, А.В. Демаков, С.В. Зеленов, А.С. Косачев, В.В. Кулямин, В.А. Омельченко, Н.В. Пакулин, А.К. Петренко, А.В. Хорошилов. Подход UniTesK к разработке тестов: достижения и перспективы. // Труды ИСП РАН, Москва, 2004, т. 5, 121-156. |
| 5.обратно | А.В. Демаков. TreeDL: язык описания графовых структур данных и операций над ними. // Вычислительные методы и программирование. 2006, том 7, раздел 2, 117-127. |
| 6.обратно | С.В. Зеленов, С.А. Зеленова. Генерация позитивных и негативных тестов для парсеров // Программирование, том. 31, №6, 2005, 25-40. |
| 7.обратно | С.В. Зеленов, С.А. Зеленова, А.С. Косачев, А.К. Петренко. Применение модельного подхода для автоматического тестирования оптимизирующих компиляторов. |
| 8.обратно | С.В. Зеленов, Д.В. Силаков. Автоматическая генерация тестовых данных для оптимизаторов графических моделей. // Труды ИСП РАН, Москва, 2006, т. 9, 129-141. |
| 9.обратно | В. В. Кулямин, Н. В. Пакулин, О. Л. Петренко, А. А. Сортов, А. В. Хорошилов. Формализация требований на практике. Препринт. М.: ИСП РАН, 2006. 50 с. |
| 10.обратно | CTesK - инструмент для тестирования программного обеспечения, реализованного на языке C. |
| 11.обратно | ETSI ES 201 873-1 V3.1.1. Methods for Testing and Specification (MTS); The Testing and Test Control Notation version 3; Part 1: TTCN-3 Core Language. Sophia-Antipolis, France: ETSI, 2005. 210 с. |
| 12.обратно | JavaTESK - инструмент для тестирования программного обеспечения, реализованного на языке Java. |
| 13.обратно | OTK - инструмент для тестирования программных систем, работающих с данными, имеющими сложную структуру. |
| 14.обратно | SynTESK - инструмент для тестирования синтаксических анализаторов (парсеров) формальных языков. |
| 1(к тексту) | Работа частично поддержана грантом РФФИ 05-01-00999. |
| 2(к тексту) | Согласно Модели зрелости процесса разработки (Capability Maturity Model Integration) "верификация" определяется следующим образом: Верификация обеспечивает соответствие набора результатов работы требованиям, которые для них заданы []. |
| 3(к тексту) | Отметим, однако, что предлагаемый подход не отменяет интеграционного тестирования компилятора. |
| 4(к тексту) | Примеры контекстных условий: требование, чтобы все используемые переменные, методы и т.д. были объявлены в коде программы; требование, чтобы аргументы вызова метода по своему количеству и по своим типам соответствовали формальным параметрам вызываемого метода. |
| 5(к тексту) | Позитивный тест для парсера - это последовательность токенов, на которой парсер выдает вердикт "истина", т.е. последовательность токенов, являющаяся предложением целевого языка. |
| 6(к тексту) | Негативный тест для парсера - это последовательность токенов, на которой парсер выдает вердикт "ложь", т.е. последовательность токенов, не являющаяся предложением целевого языка. |
| 7(к тексту) | Имеются в виду все синтаксически корректные предложения. |
| 8(к тексту) | Позитивный тест для анализатора контекстных условий - это такое синтаксически корректное предложение, на котором анализатор контекстных условий выдает вердикт "истина", т.е. предложение, корректное с точки зрения статической семантики целевого языка. |
| 9(к тексту) | Негативный тест для анализатора контекстных условий - это такое синтаксически корректное предложение, на котором анализатор контекстных условий выдает вердикт "ложь", т.е. предложение, не корректное с точки зрения статической семантики целевого языка. |
| 10(к тексту) | В частности, данным методом была описана статическая семантика языков C и Java. |
Методы тестирования
Метод SemaTesK [] автоматической генерации тестов для тестирования анализаторов контекстных условий основан на использовании модели атрибутированных деревьев для конструктивного описания статической семантики целевого языка. Метод позволяет получать наборы как позитивных , так и негативных тестов для тестирования анализатора контекстных условий.
В методе SemaTesK используется формальное описание контекстных условий в форме зависимостей между вершинами абстрактного синтаксического дерева. Зависимость между некоторыми двумя вершинами индуцируется зависимостями между соответствующими атрибутами этих вершин. Одна из вершин, участвующих в контекстном условии, называется источником, а другая - целью в том смысле, что атрибуты вершины-цели зависят от атрибутов вершины-источника.
Этот метод дает возможность локализовать описание одного неформального контекстного условия в пределах одного формального правила, а также позволяет в подавляющем большинстве случаев задавать контекстные условия декларативно .
Построение тестов методом SemaTesK производится в соответствии со следующими критериями покрытия расположения контекстных условий в различных синтаксических контекстах.
Критерий полноты набора позитивных тестов для тестирования анализатора контекстных условий: Для каждого контекстного условия R из множества всех контекстных условий набор тестов должен содержать тексты, покрывающие R и такие, что соответствующее множество деревьев содержит все возможные вершины «источник» и «цель» во всех возможных синтаксических контекстах.
Критерий полноты набора негативных тестов для тестирования анализатора контекстных условий: Для каждой мутации R¯ каждого контекстного условия R из множества всех контекстных условий набор тестов должен содержать множество текстов, покрывающих R¯ и таких, что соответствующее множество деревьев содержит все возможные вершины «источник» и «цель» во всех возможных синтаксических контекстах.
Более подробное описание метода SemaTesK можно найти в работе [].
Следует особо отметить следующее важное свойство метода SemaTesK. Метод дает возможность непосредственно строить тесты, нацеленные на проверку корректности анализа контекстных условий. Это свойство позволяет в отличие от прочих известных методов отказаться при генерации тестов от использования фильтрации (селекции) позитивных/негативных тестов среди множества всех синтаксически корректных предложений данного языка, а также позволяет систематически генерировать тесты, удовлетворяющие адекватным критериям полноты.
Метод SemaTesK успешно применялся для тестирования компиляторов реальных языков программирования, в т.ч. C и Java []. Практические результаты этого применения показали эффективность метода SemaTesK.
Заметим, что особенно перспективным направлением использования метода SemaTesK является генерация тестов для разрабатываемых диалектов языков, так как вносить небольшие изменения в их описания достаточно просто, и таким образом количество ручного труда для приведения тестов в соответствие с очередной редакцией языка не велико.
Метод OTK [] автоматической генерации тестов для тестирования back-end'а основан на построении модели его входных данных на основе из абстрактного описания алгоритма работы back-end'а.
Метод OTK позволяет строить модели данных и разрабатывать на их основе генераторы тестов для компилятора, нацеленных на тестирование данного аспекта back-end'а.
Модель данных строится на основе абстрактного описания алгоритма работы тестируемого аспекта.
Алгоритм формулируется с использованием терминов, обозначающих сущности некоторого подходящего абстрактного представления входных данных, такого как граф потока управления, граф потока данных, таблица символов и пр. Back-end для осуществления своих действий ищет сочетания сущностей абстрактного представления программы, которые удовлетворяют некоторым шаблонам (например, наличие в программе циклов, наличие в теле цикла конструкций с определенными свойствами, наличие в процедуре общих подвыражений, наличие между инструкциями зависимости данных некоторого вида и пр.). При этом могут учитываться сущности лишь части терминов. Для построения модели данных рассматриваются только те термины, которые именуют сущности, задействованные хотя бы в одном шаблоне.
Итак, в результате анализа алгоритма выделяются термины и шаблоны, используемые в алгоритме. Далее на основании этой информации описывается множество модельных строительных блоков: каждому термину соответствует свой вид модельного строительного блока; строительные блоки могут связываться между собой и образовывать структуры, соответствующие шаблонам.
Модельной структурой называется граф, вершины которого - строительные блоки, а ребра - связи между строительными блоками. Модельная структура является абстракцией той части внутреннего представления структуры программы, которая существенна для целевого аспекта back-end'а.
Критерий полноты множества тестов формулируется в терминах построенной модели на основе информации о тех шаблонах, которые были выделены при анализе алгоритма.
Более подробное описание метода OTK можно найти в работе [].
Метод OTK успешно применялся при тестировании оптимизирующих компиляторов GCC, Open64, Intel C/Fortran compiler (см. []), а также для тестирования оптимизаторов графических моделей [], реализации протокола IPv6, подсистемы построения отчетов в биллинговой системе, обработчиков XML-логов []. Практические результаты этого применения показали эффективность метода OTK.
Методы верификации
Верификация встроенных возможностей языка основывается на методе OTK (см. предыдущий подраздел). Целевые конструкции моделируются на формальном языке TreeDL, из формальной модели генерируются тестовые программы. Оракул строится на основе сравнения трассы исполнения тестовой программы, откомпилированной тестируемым компилятором, с трассой выполнения программы, откомпилированной на эталонном компиляторе.
Далее мы будем рассматривать только вопросы тестирования библиотек, предоставляющих поддержку времени исполнения.
Верификация библиотек времени исполнения основывается на методе функционального тестирования с использованием технологии автоматизированного тестирования UniTESK.[].
Рассмотрим основные особенности UniTesK в приложении к тестированию программных интерфейсов: разделение построения тестовых воздействий и проверки правильности поведения целевой системы: тестовые воздействия строятся в тестовых сценариях, а проверка правильности поведения целевой системы осуществляется в тестовых оракулах; автоматизированное построение тестовых воздействий; представление функциональных требований к целевой системе в виде формальных спецификаций; автоматическая генерация тестовых оракулов из спецификаций; язык описания формальных спецификаций и тестовых воздействий «близок» к языку, на котором разработана целевая система; автоматически генерируются критерии качества покрытия требований; автоматически производится оценка качества покрытия требований при прогоне тестов.
Метод тестирования с использованием UniTESK подробно рассмотрен в препринте [].
Для работы с формальными спецификациями и спецификациями тестов разработаны пакеты инструментов CTesK [] и JavaTESK [].
Представленный метод использовался при тестировании системы поддержки исполнения компилятора Sun Java 1.4.
Моделирование
Для формального задания модели целевого языка используется представление грамматики языка в форме BNF.
Модель синтаксиса целевого языка задается в виде формального описания на языке TreeDL [] структуры корректных абстрактных синтаксических деревьев целевого языка.
Модель статической семантики целевого языка задается в виде списка контекстных условий. Для их формального описания используется язык SRL (Semantic Relation Language), специально разработанный для этой цели [].
Модель структуры входных данных задается в виде формального описания на языке TreeDL [].
Требования к программному интерфейсу формализуются как контрактные спецификации. Такой подход к спецификации основан на представлении об описываемой системе как наборе компонентов, взаимодействующих с окружением и между собой. Контрактная спецификация состоит из модельного состояния, которое моделирует внутреннее состояние системы поддержки исполнения, и набора спецификационных функций. Спецификационные функции формализуют требования к обработке входящих и исходящих функциональных вызовов посредством логических выражений в постусловиях. Такой подход к спецификации программных интерфейсов близок к логике Т. Хоара и концепции «проектирования на основе контрактов» Б. Майера.
Формальные спецификации программного интерфейса записываются на расширении языков программирования Си [] или Java []. Из формальных спецификаций автоматически генерируются тестовые оракулы - процедуры, которые выносят вердикт о соответствии наблюдаемого поведения системы спецификации.
Регламентирующие документы. Анализ требований
В рамках предлагаемого подхода под тестированием парсера понимается проверка соответствия парсера функциональным требованиям.
Функциональные требования извлекаются, как правило, из описания стандарта языка. Основное функциональное требование для парсера определяется множеством корректных предложений целевого языка. Обычно это множество описывается при помощи контекстно-свободной грамматики. Часто в тексте стандарта языка уже присутствует соответствующее описание в формальном виде.
В рамках метода SemaTesK под тестированием анализатора контекстных условий понимается проверка соответствия анализатора контекстных условий функциональным требованиям.
Функциональные требования извлекаются, как правило, из описания стандарта языка. Основное функциональное требование для анализатора контекстных условий определяется множеством предложений целевого языка, корректных с точки зрения статической семантики. Обычно это множество задается в стандарте при помощи описания синтаксиса языка в виде контекстно-свободной грамматики, а также при помощи описания контекстных условий в виде неформального текста. Основной работой по анализу требований в рамках метода SemaTesK является извлечение из стандарта языка и составление списка всех контекстных условий.
В рамках метода OTK под тестированием back-end'а в трансляторе понимается проверка соответствия семантики выходных данных, созданных back-end'ом, семантике соответствующих входных данных.
Структура входных данных извлекается из абстрактного описания алгоритма работы back-end'а (см. выше описание метода тестирования).
В рамках предлагаемого подхода под верификацией подсистемы поддержки времени исполнения понимается проверка соответствия этой подсистемы функциональным требованиям.
Функциональные требования, как правило, извлекаются из спецификации, или стандарта языка или описания эталонной реализации языка. Так, в случае языка TTCN3 функциональные требования представлены в частях 1, 4, 5 и 6 спецификации языка []. Требования к подсистеме поддержки исполнения Java приводятся в Java Language Specification, спецификаций Java SDK и Java Native Interface, опубликованных фирмой Sun.
Систематический подход к верификации функций компилятора
Функции компилятора тесно связаны, поэтому при верификации компилятора необходимо проверять корректность каждой из них. В предлагаемом подходе задача верификации компилятора декомпозируется на основе декомпозиции функциональности компилятора. Мы выделяем следующие задачи: Верификация синтаксического анализатора компилятора. Верификация семантического анализатора компилятора. Верификация оптимизаций и генерации кода. Верификация библиотек поддержки времени исполнения (runtime).
Некорректное функционирование подсистемы поддержки исполнения делает почти бесполезным весь компилятор - результат компиляции будет работать неверно из-за ошибок в этой подсистеме и, следовательно, станет непригодным для нужд пользователя. Тесная связь компилятора и подсистемы поддержки исполнения служит обоснованием того, чтобы включить верификацию подсистемы поддержки исполнения в общую задачу верификации компилятора.
Корректность оптимизаций и генерации кода определяет корректность создаваемых транслятором выходных данных. Поэтому верификация этой функциональности является основной задачей верификации компилятора.
От корректности синтаксического анализа и анализа контекстных условий зависит корректность основной функциональности транслятора - оптимизирующих преобразований, генерации кода. Поэтому решение задачи верификации анализа синтаксиса и контекстных условий является базой для решения задач верификации остальных функций компилятора.
В литературе выделяют два вида верификации - статическая верификация средствами анализа кода и аналитической верификации и динамическая верификация посредством тестирования. Компилятор любого практически полезного языка представляет собой настолько сложную систему, что статической верификации поддаются только отдельные небольшие подсистемы, например, отдельные блоки оптимизации. Для решения задач верификации, поставленных выше, на практике используются методы динамической верификации.
В связи с этим при проведении верификации компилятора и его функций необходимо решить следующий набор задач: автоматизация построения тестов: автоматизация генерации тестовых данных; автоматизация проверки корректности обработки тестовых данных (проблема построения оракула); определение критерия завершения верификации.
В данной работе мы предлагаем решать эти задачи на систематической основе.
Во всех задачах верификации методы верификации строятся по единой схеме (рис. 1).

Тестирование
Автоматический оракул для прогона позитивных тестов устроен так: проверяется, что результатом обработки каждого теста парсером является значение «истина». При применении тестов к реальному компилятору значение парсера «истина» трактуется следующим образом: в выводе компилятора отсутствуют сообщения о синтаксических ошибках.
Аналогично устроен оракул для прогона негативных тестов: проверяется, что результатом обработки каждого теста парсером является значение «ложь», то есть в выводе компилятора присутствуют сообщения об ошибках синтаксиса.
Автоматический оракул для прогона позитивных тестов устроен так: проверяется, что результатом обработки каждого теста анализатором контекстных условий является значение «истина». При применении тестов к реальному компилятору значение парсера «истина» трактуется следующим образом: в выводе компилятора отсутствуют сообщения о семантических ошибках.
Аналогично устроен оракул для прогона негативных тестов: проверяется, что результатом обработки каждого теста анализатором контекстных условий является значение «ложь», то есть в выводе компилятора присутствуют сообщения об ошибках семантики.
В рамках метода OTK оракул для тестирования back-end'а в компиляторе автоматически проверяет сохранение семантики выполнения программы во время обработки back-end'ом. Для этого в качестве тестовых воздействий меппером строятся такие программы, семантика выполнения которых полностью представляется их трассой. Такое свойство тестов позволяет свести задачу проверки сохранения семантики к сравнению трассы с некоторой эталонной трассой.
Работа такого автоматического оракула заключается в следующем:
каждый тест компилируется дважды - тестируемым компилятором и некоторым эталонным компилятором; обе откомпилированные версии запускаются на исполнение; полученные трассы сравниваются; считается, что тест прошел успешно в том и только том случае, если трассы эквивалентны.
При обходе автомата теста автоматически выдаются тестовые воздействия, связанные с текущим переходом автомата, собираются ответы целевой системы и выносится вердикт о соответствии наблюдаемого поведения системы её спецификации. Критерий полноты тестирования формулируется в терминах покрытия спецификации - должны быть покрыты все ветви функциональности, представленные в спецификационных функциях.
В ходе тестирования генерируется трасса теста, по которой генерируются отчёты. Отчёты содержат информацию о том, какие функции целевой системы тестировались и были ли выявлены в ходе тестирования расхождения со спецификацией.
Тестирование анализаторов контекстных условий
Анализатором контекстных условий мы называем булевскую функцию, заданную на множестве предложений данного формального языка и принимающую значение «истина», если в предложении выполняются все относящиеся к нему контекстные условия, и «ложь» - если хотя бы одно из этих контекстных условий нарушается.
Тестирование оптимизаций и генерации кода
Back-end'ом мы называем функцию, которая принимает на вход структуру обрабатываемых входных данных в некотором внутреннем представлении и генерирует соответствующие ей требуемые выходные данные. Функциональность back-end'а касается следующих аспектов: анализ внутреннего представления программы, проводящийся с целью обогащения его дополнительной информацией, которая требуется при генерации выходных данных; примерами подобного анализа являются, например, анализ графа потока управления программы, анализ потоков данных в программе и проч.; трансформации (оптимизации) внутреннего представления программы, проводящиеся с целью улучшения качества выходных данных в соответствии с выбранным критерием (например, размер или скорость работы программы); примерами подобных оптимизаций являются, например, удаление неиспользуемых частей входных данных, вычисление константных выражений на этапе трансляции, оптимизация размещения аргументов и промежуточных результатов вычислений в регистрах процессора и проч.; построение результирующего представления в выходном языке.
Верификация компиляторов - систематический подход
С.В. Зеленов, Н.В. Пакулин,
Труды Института системного программирования РАН
Верификация подсистемы поддержки исполнения (runtime support)
Рассмотрим несколько примеров подсистем поддержки исполнения. Для низкоуровневых языков, таких как Си и Си++, поддержка исполнения ограничивается тем, что в состав поставки компилятора включаются стандартные библиотеки этих языков.
Компилятор Java переводит исходный текст на языке Java в байт-код. Система поддержки времени исполнения включает в себя виртуальную машину Java, стандартную библиотеку классов Java SDK, в том числе, внутренние классы, обеспечивающие доступ к ресурсам операционной системы (ввод-вывод, потоки, и т.д.), набор средств взаимодействия Java-среды с окружением через JNI.
Другой пример относится к языку спецификации тестов TTCN3. Все известные в настоящее компиляторы TTCN3 построены как трансляторы - исходный текст на языке TTCN3 преобразуется в набор файлов на целевом языке (Си или Java), которые затем компилируются соответствующими компиляторами. Система поддержки времени выполнения представляет собой набор библиотек на целевом языке (Си или Java), которые реализуют встроенные возможности языка (таймеры, порты обмена сообщениями, стандартные функции и т.п.), предоставляют интерфейсы расширения (TCI и TRI) как сгенерированному коду, так и окружению, и, в зависимости от поставщика, различные дополнительные возможности.
Задачу верификации подсистемы поддержки исполнения можно разделить на следующие подзадачи: Верификация программного интерфейса, предоставляемого сгенерированному коду. Верификация встроенных возможностей языка и динамической семантики операций, предоставляемых подсистемой поддержки исполнения. Верификация интерфейсов взаимодействия с окружением. Эта задача может быть разделена на две подзадачи: Верификация интерфейсов, предоставляемых окружению для взаимодействия с исполняемой системой. Верификация интерфейса, который предоставляет подсистема поддержки исполнения в исходном языке.
Рассмотрим эти задачи на примере транслятора TTCN3, который преобразует исходный текст TTCN3 в набор файлов на языке Си. В этом случае задачи верификации можно сформулировать следующим образом: Верифицировать библиотеки непосредственно через предоставляемый ими интерфейс Си/Си++. Верификация встроенных возможностей языка заключается в том, чтобы проверить выполнение требований динамической семантики TTCN3 в той части, которая реализована в подсистеме поддержки исполнения - проверка требований к передаче сообщений через порты обмена сообщениями, обработке событий в инструкциях выбора alt, запуску и остановке компонентов и т.д. Верификация интерфейсов расширения заключается в проверке выполнения требований к стандартным интерфейсам расширения: Обращения к «скомпилированному тестовому набору» (Compiled Test Suite) извне через стандартные интерфейсы TCI и TRI, представленные в виде набора функциональных вызовов в программе на Си. Обращения к окружению скомпилированного тестового набора, представленные инструкциями и выражениями в исходных текстах на TTCN3, через стандартные интерфейсы TTCN3.
Аналогичные задачи можно сформулировать и для подсистем поддержки времени исполнения языка Java.
Верификация библиотеки поддержки исполнения. Необходимо учитывать, что почти все сервисы, предоставляемые поддержкой времени исполнения, представлены как классы Java, поэтому в данном случае верификация представляет собой тестирование Java-классов. Верификация встроенных возможностей языка (например, синхронизации доступа) и динамической семантики (например, создания и уничтожения объектов). Верификация интерфейсов расширения:
Обращения из Java-кода к ресурсам операционной системы через специализированные классы (потоки ввода-вывода, потоки исполнения Thread, класс System и т.д.), обращения из Java к внешним библиотекам, разработанным на других языках (JNI). Верификация программного интерфейса виртуальной машины Java и доступа к объектам Java через JNI из программ на Си.
Верификация синтаксического анализатора
Синтаксический анализ входного текста является частью функциональности любого транслятора. Парсером мы называем булевскую функцию, заданную на множестве последовательностей токенов и принимающую значение «истина», если последовательность является предложением данного формального языка, и «ложь» - в противном случае.
Задачу верификации парсера можно разделить на следующие подзадачи:
Проверка того, что парсер принимает предложения, принадлежащие целевому языку. Проверка того, что парсер отвергает предложения, не принадлежащие целевому языку.
Языки высокого уровня являются основным
Языки высокого уровня являются основным средством разработки программных систем. Спецификация языка высокого уровня задаёт класс текстов, принадлежащих этому языку, и определяет семантику исполнения программ, написанных на этом языке. Задача перевода текстов с языка высокого уровня в представление, выполнимое на вычислительной системе, решается комплексами программ, которые по традиции называют компиляторами. Ошибки в компиляторах приводят к тому, что выполнение результирующих исполнимых модулей отличается от поведения, определяемого спецификацией языка. Дефекты исполнимых модулей, вызванные ошибками в компиляторе, очень сложно выявлять и исправлять, и в целом корректность исполнимых модулей, построенных некорректным компилятором, вызывает сомнения. Корректность компилятора является необходимым требованием корректной и надёжной работы программного обеспечения, разработанного на соответствующем языке высокого уровня. Тем самым, задачу верификации компилятора можно считать одним из важнейших средств обеспечения надёжности программного обеспечения. Основной источник трудностей при верификации компилятора заключается в том, что компилятор принимает на вход данные со сложной структурой, большим количеством внутренних связей и обладающие очень сложной семантикой времени исполнения. Для снижения сложности задачи верификации компилятора мы предлагаем декомпозировать её на отдельные подзадачи, которые в совокупности покрывают всю функциональность компилятора . Функциональность, типичную для большинства компиляторов, можно условно декомпозировать на следующие задачи: Анализ синтаксической корректности исходного теста программы. Анализ выполнения контекстных условий в исходном тексте . Оптимизация внутреннего представления и генерация выходных данных. Результатом работы компилятора является объектный модуль на машинном языке или модуль на исполнимом промежуточном языке, таком как байт-код Java и Python или Intermediate Language платформы .NET. Для большинства компиляторов языков программирования, используемых на практике, генерируемый код исполняется в специализированном окружении, которое обобщённо называется run time support.
В рамках данной статьи мы будем пользоваться термином «подсистема поддержки исполнения». Подсистема поддержки исполнения тесно связана с компилятором. Например, каждый компилятор Си и Си++ поставляется со своим набором стандартных библиотек, причём библиотеки одного компилятора нельзя использовать для построения исполнимых файлов другим компилятором. Даже в тех случаях, когда промежуточный язык и стандартные библиотеки стандартизированы, существуют тесные зависимости между компилятором и средой исполнения. Например, для исполнения байт-кода Java в виртуальной машине Java компании IBM лучше всего для компиляции использовать компилятор Java именно этой фирмы; аналогично для исполнения байт-кода в виртуальной машине компании Sun следует компилировать исходные тексты компилятором Java, разработанным в Sun. В настоящей работе представлен подход к верификации компиляторов, основанный на технологии автоматизированного тестирования UniTESK[]. Методы, составляющие представленный подход, построены по единому шаблону формализации требований [].
В работе представлен систематический подход
В работе представлен систематический подход к верификации компиляторов. Общая задача верификации компилятора декомпозирована на подзадачи верификации отдельных аспектов функциональности компилятора. Декомпозиция задачи верификации позволяет начинать верификацию на ранних этапах создания компилятора и проводить её параллельно разработке. Тем самым, сокращается продолжительность цикла разработки компилятора и снижаются суммарные затраты на тестирование компилятора. Для всех выделенных подзадач предложены методы верификации, построенные в рамках единого подхода тестирования на основе формальных спецификации и моделей. Для всех методов существуют их подробные описания и инструментальная поддержка для их практического применения. Представленный подход использовался при тестировании компиляторов Си и Java, а также трансляторов расширений языков программирования, разработанных в ИСП РАН [].
Анализ и отображение результатов
Когда Rational Robot закончит выполнение тестов, результаты тестирования будут отображены в наглядном виде в Rational TestManager[6]. Это программа для управления отчётами о тестировании, и, в случае ошибочной ситуации, выдаётся достаточная информация об ошибке для её нахождения и исправления.
Типичный screenshot программы Rational TestManager представлен ниже на рисунке.

Автоматическая генерация тестов
Калинов А.Я., Косачёв А.С., Посыпкин М.А., Соколов А.А.,
Труды Института Системного Программирования РАН.
В статье излагается метод автоматической генерации набора тестов для графического интерфейса пользователя, моделируемого детерминированным конечным автоматом с помощью UML диаграмм действий. Метод заключается в построении обхода графа состояний системы с применением неизбыточного алгоритма обхода [1,2] и компиляции построенного обхода в тестовый набор.
Диаграмма состояний
Диаграмма состояний – это формальная спецификация всех состояний системы и возможных переходов между ними с помощью диаграмм действий. Но во избежание так называемого "взрыва состояний" был использован метод расширенных конечных автоматов (EFSM – Extended Finite State Machine). При этом выделяется множество так называемых управляющих состояний и множество переменных. Реальные же состояния системы описываются управляющими состояниями и наборами значений переменных. Каждому переходу приписывается (кроме обычных стимулов и реакций) предикат от значений переменных и действия по изменению значения переменных. EFSM позволяют существенно сократить размер описания, сохраняя практически всю информацию о системе.
На диаграммах имеются объекты типа State(Normal). Это управляющие элементы, или управляющие состояния. Переменные были введены как раз затем, чтобы не дублировать одно и тоже действие из разных состояний, а изобразить его один раз из одного управляющего состояния. Таким образом, каждому управляющему состоянию на диаграмме соответствует множество реальных состояний системы. То есть мы можем написать:
Состояние = . (где UML-State – есть управляющее состояние)Соответственно, переходы между управляющими состояниями обретают предусловия (guard condition), определяющие, из каких конкретно состояний, соответствующих данному управляющему состоянию, возможен переход, и действия (action), определяющие, в какое конкретно состояние ведёт этот переход. Предусловия и действия записываются на простом языке, в котором есть следующие конструкции:
конструкция ::= список предусловий | список действий список предусловий ::= предусловие | список предусловий, предусловие список действий ::= действие | список действий, действие предусловие ::= переменная = выражение действие ::= переменная := выражение выражение ::= переменная | константа переменная ::= символ{символ} константа ::= цифра{цифра} символ ::= буква | цифраТакой язык был выбран из-за простоты интерпретации, что упростило написание интерпретатора.
Но, как оказалось, перечисленных возможностей вполне достаточно для описания большинства возможностей графического интерфейса.
Ниже приведён пример диаграммы состояний с двумя переменными и одной поддиаграммой.


Переход по событию ‘Connect to Server’ из управляющего состояния ‘mpCWorkshop’ означает переход в поддиаграмму, соответствующую объекту типа Activity ‘Connect to Server’, и дальнейший переход к состоянию ‘Connect to Server’. Переход по событию ‘Close’ из управляющего состояния ‘Connect to Server’ ведёт в конечное управляющее состояние на этой поддиаграмме, что означает переход из Activity ‘Connect to Server’ на главной диаграмме в управляющее состояние mpCWorkshop. Переход по событию ‘Connect’ из управляющего состояния ‘Connect to Server’ ведёт в объект типа Decision, в котором происходит разветвление в зависимости от значения переменной ‘server’. Если сервер запущен (‘server=1’), то устанавливается соединение (‘connect:=1’), и, как и в случае 2, переход в конечное управляющее состояние этой поддиаграммы ведёт в управляющее состояние mpCWorkshop главной диаграммы. Если сервер не запущен (‘server=1’), то переход ведёт в управляющее состояние mpCWorkshop этой поддиаграммы (это модальный диалог-предупреждение о том, что соединение не может быть установлено). Из этого управляющего состояния возможны два перехода – по событию ‘OK’ переход ведёт в управляющее состояние ‘Connect to Server’, а по событию ‘Cancel’, как и в случае 2, переход ведёт в управляющее состояние mpCWorkshop главной диаграммы. Переход по событию ‘Exit’ из управляющего состояния ‘mpCWorkshop’ ведёт в конечное управляющее состояние главной диаграммы, что означает переход к начальному управляющему состоянию этой диаграммы, и дальнейший переход в состояние mpCWorkshop. Итак, можно составить набор правил, определяющих переходы между состояниями:
Переход между состояниями осуществляется по событию и может состоять из нескольких переходов между управляющими элементами на диаграмме, к каковым относятся объекты типа State(Normal), Start State, End State, Activity, Decision, а также переход в поддиаграмму или возвращение из неё. Событие есть непустое имя перехода. Событие есть у всех переходов, начинающихся в управляющих элементах типа State(Normal), и только у них. Переход из управляющего состояния типа State(Normal) происходит по событию. Переход из управляющего состояния типа Start State, End State, Activity, Decision происходит без события. Переход между состояниями начинается и заканчивается только в управляющих элементах типа State(Normal). Переход между состояниями атомарный. Каждый переход между управляющими элементами может иметь предусловия и действия. Наличие пустого предусловия по умолчанию означает его истинность. Пустое действие означает отсутствие изменения значений переменных. Каждый переход может иметь несколько предусловий, разделённых оператором ",". Каждый переход может иметь несколько действий, разделённых оператором ",". Переходы детерминированы, то есть не может существовать двух переходов с одинаковым событием (или оба без события), начинающихся в одном управляющем состоянии и обладающих предусловиями, которые допускают одновременное выполнение. На каждой диаграмме должны существовать начальное и конечное (не обязательно одно) управляющие состояния (на главной диаграмме конечное состояние может не существовать). Поддиаграммы есть у объектов типа Activity, и только у них. Если переход из какого-либо управляющего элемента ведёт в управляющий элемент типа Activity, это означает переход к начальному управляющему элементу поддиаграммы, соответствующей элементу типа Activity, и дальнейший переход без события. Если переход из какого-либо управляющего элемента ведёт в конечный управляющий элемент какой-либо поддиаграммы, то это означает переход к управляющему элементу типа Activity, которому соответствует эта поддиаграмма, и дальнейший переход из этого элемента без события. Если переход из какого-либо управляющего элемента ведёт в управляющий элемент типа Decision, это означает продолжение перехода от этого элемента без события. Дальше диаграмма, составленная по таким правилам, подаётся на вход генератору тестов.
Кроме этого с каждым объектом на диаграмме (модель, диаграммы, управляющие элементы, переходы) связаны требования (спецификации) к данному объекту. Эти требования размещаются в поле Documentation, предусмотренное Rational Rose для каждого объекта на диаграмме. Эта требования записываются в виде инструкций на языке SQABasic, которые выполняет Rational Robot. В большинстве случаев с переходами связаны инструкции, означающие какие-то действия пользователя, а с управляющими элементами связаны инструкции, означающие требования к данному состоянию, которые может проверить Rational Robot, По сути данный набор инструкций реализует оракул этого состояния.
Генератор тестов
Генератор строит по диаграмме состояний набор тестов. Условием окончания работы генератора является выполнение тестового покрытия. В данном случае в качестве покрытия было выбрано условие прохода по всем рёбрам графа состояний, то есть выполнения каждого доступного тестового воздействия из каждого достижимого состояния.
Структурно генератор тестов состоит из следующих компонентов:
Интерпретатор Итератор Обходчик КомпиляторИнтерпретатор осуществляет переход между состояниями в соответствие с введёнными ранее правилами. В случае успешного перехода он останавливается и возвращает указатель на тот управляющий элемент, в котором он остановился, в случае неудачи он останавливается и выводит сообщение о возникшей ошибке (обычно это несоответствие введённым правилам). Для замыкания диаграммы вводится дополнительное условие: если переход из какого-либо управляющего элемента ведёт в конечный управляющий элемент главной диаграммы, то это означает переход к её начальному управляющему элементу и дальнейший переход без события.
Связь интерпретатора с обходчиком выполняет итератор переходов. В соответствие с выбранным алгоритмом обхода, итератор возвращает событие, переход по которому ещё не был совершён из данного состояния. Если все переходы были совершены, итератор возвращает пустое событие.
Обходчик есть ключевой компонент генератора тестов. Чтобы построить тестовый набор, он строит обход ориентированного графа состояний, проходя по всем дугам графа. Алгоритм его работы взят из [7,8,9]. Прибегнуть к специальному алгоритму обхода ориентированного графа заставило то обстоятельство, что граф состояний скрыт - на диаграмме действий изображён граф, состоящий из управляющих элементов. Это значит, что заранее неизвестны все возможные состояния графа, поэтому мы и воспользовались неизбыточным алгоритмом обхода ориентированного графа. В процессе работы обходчик вызывает итератор переходов для получения событий, соответствующих не пройденным переходам, и интерпретатор событий, последовательность которых формируется в соответствие с алгоритмом.
Обходчик останавливается на любом графе, вынося вердикт, совершен обход или нет. В том случае, если нет, то выводится отладочная информация о причинах, не позволивших его совершить, чтобы можно было быстро их устранить (обычно это либо несоответствие правилам, либо тупиковое состояние).
Компилятор (здесь термин компиляция подразумевается в его "не программистском" смысле – сборка). Как уже говорилось, с каждым объектом на диаграмме (модель, диаграммы, управляющие элементы, переходы) связан некоторый набор инструкций на языке SQABasic, которые выполняет Rational Robot. В большинстве случаев с переходами связаны инструкции, означающие какие-то действия пользователя, а с управляющими элементами связаны инструкции, означающие оракул этого состояния. В процессе обхода графа состояний, пройденный путь компилируется в тестовые файлы, содержащие инструкции для Rational Robot. Компиляция происходит путём записи информации, связанной с каждым пройденным объектом. Далее приведен фрагмент вызова функции записи документации:
Автоматическая генерация тестов по диаграммам действий имеет следующие преимущества перед остальными подходами к тестированию графического интерфейса:Генератор тестов есть программа(script), написанная на языке ‘Rational Rose Scripting language’(расширение к языку Summit BasicScriptLanguage). В Rational Rose есть встроенный интерпретатор инструкций, написанных на этом языке, посредством которого можно обращаться ко всем объектам модели (диаграммы состояний).
Спецификация автоматически интерпретируется (тем самым она проверяется и компилируется в набор тестов).
Если какая-то функциональность системы изменилась, то диаграмму состояний достаточно изменить в соответствующем месте, и затем сгенерировать новый тестовый набор. Фактически, это снимает большую часть проблем, возникающих при организации регрессионного тестирования.
Гарантия тестового покрытия. Эта гарантия даётся соответствующим алгоритмом обхода графа состояний.
Обработка ошибочной ситуации
В результате применения предложенного подхода была поднята некоторая проблема. А именно, как продолжать прогон тестов после его останова во время ошибочной ситуации. На данный момент существует несколько вариантов её разрешения:
Ошибка исправлена разработчиками в разумные сроки. Сознательно специфицируется именно ошибочное поведение системы. Данная функциональность вообще не тестируется (например, у соответствующего перехода ставится невыполнимое предусловие). Тестирование продолжается со следующего теста. При этом нужно привести систему в состояние, соответствующее начальному состоянию следующего теста.Обзор имеющихся средств автоматического тестирования графического интерфейса
Самым распространённым способом тестирования графического интерфейса является ручное тестирование. Естественно, у такого подхода имеются серьёзные недостатки, и самый главный из них – большая трудоёмкость, которая часто становится критичной при организации регрессионного тестирования. Другим недостатком такого подхода является отсутствие гарантий выполнения каждого доступного воздействия из каждого возможного состояния системы. Таким образом, приходится полагаться на однозначность реакции системы на одинаковые воздействия из разных состояний, то есть считать эти состояния эквивалентными для данного воздействия.
Другим способом организации тестирования является автоматическое тестирование [2]. Существуют два раскрытия этого термина:
Ручное написание тестов и их автоматический прогон. Автоматическая генерация тестов.Из наиболее доступных инструментов для автоматизированного тестирования можно выделить следующие пять:
WinRunner QA Run Silk Test Visual Test RobotПеречисленные инструменты применяются для автоматизированного тестирования, в том числе при тестировании GUI. В своей статье [3] Рэй Робинсон приводит сравнительную таблицу (см. таб. 1) этих инструментов по способности удовлетворять заданные потребности пользователя. При этом рассматриваются различные свойства этих инструментов:
Запись и проигрывание тестов Возможности Web-тестирования Возможности базы тестов и функции для работы с ней Объектное представление Сравнение рисунков Обработка ошибочных ситуаций Сравнение свойств объектов Возможности расширения языка И т.п.(по 5-бальной шкале, наивысшая оценка - 1)
| WinRunner | QA Run | Silk Test | Visual Test | Robot | |
| Object Tests | 1 | 1 | 1 | 2 | 1 |
| Support | 1 | 2 | 2 | 2 | 2 |
| Ease of use | 2 | 2 | 3 | 3 | 1 |
| Cost | 3 | 2 | 3 | 1 | 2 |
| Integration | 1 | 1 | 3 | 2 | 1 |
| Environment support | 1 | 2 | 2 | 3 | 2 |
| Extensible Language | 2 | 2 | 1 | 2 | 1 |
| Object Identity Tool | 2 | 1 | 2 | 1 | 1 |
| Object Name Map | 1 | 2 | 1 | 4 | 4 |
| Test/Error recovery | 2 | 2 | 1 | 2 | 2 |
| Image testing | 1 | 1 | 1 | 2 | 1 |
| Object Mapping | 1 | 1 | 1 | 2 | 1 |
| Data functions | 2 | 2 | 2 | 3 | 1 |
| Database tests | 1 | 1 | 1 | 4 | 1 |
| Web Testing | 1 | 2 | 2 | 3 | 2 |
| Record & Playback | 2 | 1 | 1 | 3 | 1 |
Таблица 1.
Кроме самых распространённых, имеется много других инструментов для автоматического прогона тестов, созданных вручную. Но эти инструменты не предоставляют возможности автоматической генерации тестов (исключая процесс записи теста).
В основе всех этих инструментов лежат средства формального описания тестов (разного рода скриптовые языки). Тесты пишутся вручную. Данный подход имеет существенные недостатки. Один из них состоит, как и при полностью ручном подходе, в недостаточной систематичности. Другим серьёзным недостатком является трудность при организации регрессионного тестирования. При изменении тестируемой системы возникает необходимость переписывания (редактирования) большого количества тестов. То есть, например, система изменилась в одном месте – а тесты приходится модифицировать в несравненно большем количестве мест. Причём если некоторые такие проблемы можно обойти созданием набора вызываемых функций, которые также можно изменять в одном месте, то другие (например, изменение в логике программы) так просто не решаются. Кроме того, остаётся проблема дублирования одних и тех же действий (написание одного и того же тестового кода) при совершении одного и того же события из разных состояний. Такой метод сменил ручной прогон тестов на ручное написание самих тестов для дальнейшего автоматического прогона, но само их написание по-прежнему остаётся трудоёмким занятием.
Доступные инструменты для автоматической генерации тестов для GUI нам не известны. Поэтому мы в первую очередь сконцентрировали свои усилия именно на автоматизации генерации тестов для GUI по формальной спецификации. Причем при разработке средств формальной спецификации GUI мы старались максимально использовать существующие, привычные для пользователей методы и инструменты.
Описание подхода
Правильность функционирования системы определяется соответствием реального поведения системы эталонному поведению. Для того чтобы качественно определять это соответствие, нужно уметь формализовать эталонное поведение системы. Распространённым способом описания поведения системы является описание с помощью диаграмм UML (Unified Modeling Language) [4]. Стандарт UML предлагает использование трех видов диаграмм для описания графического интерфейса системы:
Диаграммы сценариев использования (Use Case). Диаграммы конечных автоматов (State Chart). Диаграммы действий (Activity).С помощью UML/Use Case diagram можно описывать на высоком уровне наборы сценариев использования, поддерживаемых системой [5]. Данный подход имеет ряд преимуществ и недостатков по отношению к другим подходам, но существенным с точки зрения автоматизации генерации тестов является недостаточная формальная строгость описания.
Широко распространено использование UML/State Chart diagram для спецификации поведения системы, и такой подход очень удобен с точки зрения генерации тестов. Но составление спецификации поведения современных систем с помощью конечных автоматов есть очень трудоёмкое занятие, так как число состояний системы очень велико. С ростом функциональности системы спецификация становится всё менее и менее наглядной.
Перечисленные недостатки этих подходов к описанию поведения системы преодолеваются с помощью диаграмм действий (Activity). С одной стороны нотация UML/Activity diagram является более строгой, чем у сценариев использования, а с другой стороны предоставляет более широкие возможности по сравнению с диаграммами конечных автоматов. Следующие причины определяют пригодность диаграмм действий для моделирования графического интерфейса:
Графический интерфейс пользователя (GUI) в большинстве случаев удобно представить в виде конечного автомата, так как поведение системы зависит от состояния, в котором она находится, и воздействия пользователя (и, может быть, других внешних воздействий). GUI имеет иерархичную структуру.Действительно, модальные диалоги (те, которые перехватывают управление) удобно моделировать с помощью отдельной диаграммы состояний (для верхней диаграммы это поддиаграммы), инкапсулируя тем самым их функциональность. Диаграмма действий позволяет специфицировать систему таким образом, при котором отсутствует дублирование одинаковых событий из разных состояний. Достигается это использованием на диаграмме управляющих элементов, из которых возможны тестовые воздействия, а не самих состояний. Спецификация диаграммами действий удобна для восприятия человеком. Другими словами, спецификация графического интерфейса с помощью диаграмм действий является достаточно естественным способом описания требований к графическому интерфейсу. Причём при таком подходе сохраняется вся сила формальных спецификаций – как показывает опыт, большая часть ошибок выявляется именно на этапе составления спецификации системы.
Итак, перейдём к детальному рассмотрению предлагаемого подхода.
Для создания прототипа работающей версии данного подхода использовался инструмент Rational Rose [6]. Он использовался в первую очередь для спецификации графического интерфейса пользователя при помощи диаграмм действий UML.
Для прогона сгенерированных по диаграмме состояний тестов использовался инструмент Rational Robot [6]. Из возможностей инструмента в работе мы использовали следующие:
1. Возможность выполнять тестовые воздействия, соответствующие переходам между состояниями в спецификации.
2. Возможность проверять соответствие свойств объектов реальной системы и эталонных свойств, содержащихся в спецификации. Из тех возможностей, которые доступны с помощью этого инструмента, используется проверка следующих свойств объектов:
Наличие и состояние окон (заголовок, активность, доступность, статус). Наличие и состояние таких объектов, как PushButton, CheckBox, RadioButton, List, Tree и др. (текст, доступность, размер). Значение буфера обмена. Наличие в оперативной памяти запущенных процессов. Существование файлов. Общая схема генерации и прогона тестов выглядит следующим образом:
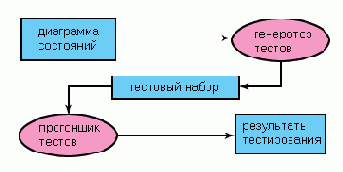
Поставленная задача
Разработка и реализация методов автоматизированной генерации набора функциональных тестов для GUI mpC Workshop[10,11].
mpC Workshop – это среда для разработки приложений для параллельных вычислений на языке mpC[12,13,14] с функциональностью графического интерфейса типичной для такого типа систем. Ниже приведён типичный screenshot mpCWorkshop:

Для тестирования базовой функциональности была составлена базовая диаграмма состояний и переходов mpC Workshop. Ниже приведены фрагменты это диаграммы (включая поддиаграммы).
Главная диаграмма выглядит следующим образом:
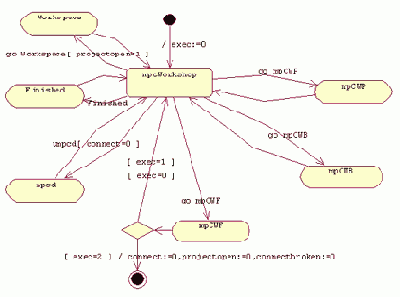
Такие объекты типа Activity, как "mpCWP", "mpCWB", "mpCWF", "mpcd", "Finished", "Workspace" означают наличие под собой поддиаграмм. Ниже приведены поддиаграммы, соответствующие объектам" mpCWP" и " mpCWB".


С Activity "Connect to Server" связана следующая поддиаграмма:

Как видно из рисунков, на этих поддиаграммах тоже есть поддиаграммы. Фактически, каждый объект типа Activity скрывает под собой часть функциональности системы. Под "mpCWB" содержится описание функциональности, связанной с работой с сервером, под "mpCWP" содержится описание функциональности, связанной с работой с проектом, под "mpCWF" содержится описание функциональности, связанной с работой с файлами, и т.д.
В этой базовой диаграмме используется 12 переменных с начальными значениями, приведёнными ниже:
connect, 0 connectbroken,0 mpcd, 0 exec, 2 build,0 compile,0 projectopen, 0 projectbuild, 0 projectexist, 0 projectpathenter, 0 projectpathcorrect, 0 openfilempcifproject,0Практически с каждым объектом на диаграмме связаны тестовые инструкции на языке SQABasicScript. Ниже в таблице приведены примеры этих инструкций, связанных с управляющими состояниями и переходами:
| mpCWorskhop | Window SetContext, "Caption={mpC Worksho*}; State=Enabled", "Activate=1; Status=MAXIMIZED" Result = ModuleVP (Exists, "Name = mpcworkshop.exe", "ExpectedResult = PASS") |
| go mpCWP | InputKeys "%p" |
| Connect | Window SetContext, "Caption={mpC Worksho*}; State=Disabled", "Activate=0; Status=MAXIMIZED" Window SetContext, "Caption=Connect to server; State=Enabled", "Activate=1" PushButton Middle_Click, "Text=Start server;State=Enabled" PushButton Middle_Click, "Text=Close;State=Enabled" PushButton Middle_Click, "Text=Advanced >>;State=Enabled" PushButton Middle_Click, "Text=Connect;State=Enabled" CheckBox Middle_Click, "Text=Once" CheckBox Middle_Click, "Text=Hidden" ListView Click, "Text=List1;\;ItemText=DIVER", "" uConnect PushButton Click, "Text=Connect;State=Enabled" |
И так далее….
Генератор тестов для данной диаграммы генерирует тесты за время порядка 1-й минуты. Суммарный размер выходных тестов равен 1541024 байта, что примерно равно 1.5 мегабайта.
На данной диаграмме изображено 14 управляющих состояний, тогда как в процесее генерации тестов воспроизводится 258 реальных состояний системы (то есть управляющих состояний и значений переменных).
Ниже приведен начальный кусок сгенерированного тестового кода. Видно, что тестовые воздействия перемежаются с оракулом заданных свойств состояний. Также вставляется строка: '------cutting line------.
Она вставляется после каждого законченного набора тестовых инструкций, связанных с одним объектом диаграммы. Эта строка требуется для осмысленного разрезания сгенерированного скрипта, так как его размер примерно равен 1.5 мегабайта, а у прогонщика тестов Rational Robot есть ограничение на тест в размере 20 килобайт. Таким образом, большой тест разрезается на маленькие кусочки по линиям разреза для дальнейшего последовательного прогона.
Sub Main ' copyright by ISP RAS 2004 ' implemented by A.Sokolov SQALogMessage sqaPass, "Starting test № 0", "" ' Initially Recorded: 07.06.2004 20:20:53 ' Class № 0 with name . ' Attributes: connect = 0, connectbroken = 0, mpcd = 0, exec = 2, build = 0, compile = 0, projectopen = 0, projectbuild = 0, projectexist = 0, projectpathenter = 0, projectpathcorrect = 0, openfilempcifproject = 0, IDState = 0, workDirectory$ = "E:\Alexey\Work\mpCGUITesting\mpCGUITestingProjects" '------cutting line------ StartApplication "mpcWorkshop" '------cutting line------ … Прогон сгенерированного теста длится около 50-ти минут. Скорость ввода символов и нажатия на объекты системы ограничена возможностями инструмента, но, тем не менее, она велика, и человеку практически невозможно совершать действия с такой скоростью.
Практические результаты
В ходе выполнения работы был обнаружен ряд ошибок в графическом интерфейсе mpC Workshop. Наибольшее количество ошибок было найдено на этапе составления спецификации системы. Это характерная черта использованного метода составления спецификации – по реальной работе системы. То есть на момент формализации графического интерфейса системы продукт mpC Workshop был уже разработан и реализован, таким образом сам процесс составления спецификации был уже своеобразным тестированием системы. На этом этапе было найдено порядка 10-15 ошибок в системе.
После того, как была составлена спецификация основной функциональности тестируемой системы, был сгенерирован тестовый набор, ей соответствующий. После его прогона была выявлена одна трудноуловимая ошибка.
Прогонщик тестов
В качестве прогонщика тестов мы используем Rational Robot, который выполняет сгенерированные наборы инструкций. В случае удачного выполнения всех инструкций выносится вердикт – тест прошёл. В противном случае, если на каком-то этапе выполнения теста, поведение системы не соответствует требованиям, Robot прекращает его выполнение, вынося соответствующий вердикт – тест не прошёл.
Развитие подхода
Предложенный подход генерации набора тестов, на наш взгляд, дальше можно развивать в следующих направлениях:
Внедрение асинхронности. Диаграммы действия UML позволяют моделировать асинхронное поведение системы. Использование других инструментов для специфицирования системы и прогона тестов. Внедрение зависимости инструкций, соответствующих объекту на диаграмме, от набора значений переменных текущего состояния (либо печатать в трассу сами действия, либо подставлять значения переменных в соответствующие поля инструкций). Использование более полной проверки состояний объектов системы с помощью Verification Point – данная возможность используется сейчас слабо. Использование инструкций, связанных с диаграммой, во всех управляющих элементах этой диаграммы для сокращения их дублирования. Использование функций от набора значений переменных в управляющих элементах диаграммы для проверки состояния объектов системы. Использование не самих наиболее часто встречающихся функций, а только их вызовов – для сокращения дублирования тестового кода. Предоставление тестеру, составляющему спецификацию системы, некоторого набора шаблонов, позволяющих быстро сгенерировать соответствующую диаграмму вместе с соответствующими тестовыми инструкциями.Список литературы
1. С.Канер, Д.Фолк, Е.К.Нгуен, Тестирование программного обеспечения.
2. Э.Дастин, Д.Рэшка, Д.Пол, Автоматизированное тестирование программного обеспечения.
3. Ray Robinson, AUTOMATION TEST TOOLS, Date Created: 1st March 2001, Last Updated: 11th Sept 2001.
4. UML. http://www.omg.org/technology/documents/formal/uml.htm
5. С.Г.Грошев, Тестирование на основе сценариев, дипломная работа. МГУ, ВМиК.
6. P.Kruchten. The Rational Unified Process. An introduction. //Rational Suite documentation. http://www.interface.ru/rational/rup01_t.htm
7. И.Б.Бурдонов, А.С.Косачёв, В.В.Кулямин, "Неизбыточные алгоритмы обхода ориентированных графов. Детерминированный случай." "Программирование", -2003, №6–стр 59-69
8. И.Б.Бурдонов, А.С.Косачёв, В.В.Кулямин, А.Хорошилов, Тестирование конечных автоматов. Отчет ИСП РАН.
9. http://www.ispras.ru/~RedVerst/
10. A.Kalinov, K.Karganov, V.Khatzkevich, K.Khorenko, I.Ledovskih, D.Morozov, and S.Savchenko, The Presentation of Information in mpC Workshop Parallel Debugger, Proceedings of PaCT-2003, 2003.
11. http://mpcw.ispras.ru/
12. A.Lastovetsky, D.Arapov, A.Kalinov, and I.Ledovskih, "A Parallel Language and Its Programming System for Heterogeneous Networks", Concurrency: Practice and Experience, 12(13), 2000, pp.1317-1343.
13. A.Lastovetsky, Parallel Computing on Heterogeneous Networks. John Wiley & Sons, 423 pages, 2003, ISBN: 0-471-22982-2.
14. http://www.ispras.ru/~mpc/
15. И.Б.Бурдонов, А.С.Косачёв, В.В.Кулямин, А.К.Петренко "Подход UniTesK к разработке тестов", "Программирование", -2003, №6–стр 25-43
Тестовый набор
В процессе построения обхода, генератор тестов компилирует набор тестов - инструкции на языке SQABasic. Эти инструкции есть чередование тестовых воздействий и оракула свойств объектов, соответствующих данному состоянию.
Для того, чтобы продолжать тестирование, когда один тест не прошёл, в генератор тестов встроена возможность выбора – генерировать один большой тест или набор атомарных тестов. Атомарный тест – тот, который не требует приведения системы в состояние, отличное от начального состояния.
В связи с наличием ограничения инструмента прогона тестов на тестовую длину, в тесты после каждой законченной инструкции вставляется строка разреза. Во время прогона по этим строкам осуществляется разрез теста в случае, если его длина превышает допустимое ограничение. После прохождения части теста до строки разреза продолжается выполнение теста с первой инструкции, следующей за строкой разреза. Нарезку и сам прогон тестов осуществляет прогонщик тестов.
Практически все программные системы предусматривают
Практически все программные системы предусматривают интерфейс с оператором. Практически всегда этот интерфейс – графический (GUI – Graphical User’s Interface). Соответственно, актуальна и задача тестирования создаваемого графического интерфейса.
Вообще говоря, задача тестирования создаваемых программ возникла практически одновременно с самими программами [1]. Известно, что эта задача очень трудоёмка как в смысле усилий по созданию достаточного количества тестов (отвечающих заданному критерию тестового покрытия), так и в смысле времени прогона всех этих тестов. Поэтому решение этой задачи стараются автоматизировать (в обоих смыслах).
Для решения задачи тестирования программ с программным интерфейсом (API – Application Program Interface: вызовы методов или процедур, пересылки сообщений) известны подходы – методы и инструменты – хорошо зарекомендовавшие себя в индустрии создания программного обеспечения. Основа этих подходов следующая: создается формальная спецификация программы, и по этой спецификации генерируются как сами тесты, так и тестовые оракулы – программы, проверяющие правильность поведения тестируемой программы. Спецификации, как набор требований к создаваемой программе, существовали всегда, Ключевым словом здесь является формальная спецификация. Формальная спецификация – это спецификация в форме, допускающей её формальные же преобразования и обработку компьютером. Это позволяет анализировать набор требований с точки зрения их полноты, непротиворечивости и т.п. Для задачи автоматизации тестирования эта формальная запись должна также обеспечивать возможность описания формальной связи между понятиями, используемыми в спецификации, и сущностями языка реализации программы.
В наиболее распространенных подходах используются специализированные языки формальных спецификаций, но существуют определенные трудности внедрения таких подходов в индустрию. Другой подход заключается в расширении обычных языков программирования (или других, привычных для пользователей языков) средствами спецификаций. Такой подход используется в методологии UniTesK [15]. В данной статье описана попытка применения такого подхода к автоматизации тестирования графических интерфейсов.
в настоящей работе методика автоматизации
Предложенная в настоящей работе методика автоматизации генерации тестов для GUI была разработана и апробирована с августа 2003 г. по май 2004 г. в ходе выполнения проекта по тестированию mpC Workshop. Исследование методов автоматизированной генерации тестов для GUI сейчас активно развивается.
Аннотация.
В работе описан общий подход к построению автоматического оракула для тестирования генераторов кода в трансляторах текстов на формальных языках, а также предложена инструментальная поддержка для практического использования этого подхода. Приводятся результаты практического применения описанного подхода к тестированию генератора кода транслятора описаний схем баз данных на языке SQL.
Близкие работы
Вопросу автоматического тестирования блока синтаксического разбора посвящены работы [], [], [], []. Автоматическое тестирование блока анализа статической семантики рассматривалось в [], []. Для этих блоков, понимаемых как булевские функции, в перечисленных работах предлагаются вполне удовлетворительные подходы к автоматизации их тестирования - как систематической генерации тестов, так и анализу результатов работы.
Для решения задачи автоматической генерации тестов для back-end'а предлагаются следующие подходы. Один подход - это генерация различных синтаксически корректных предложений целевого языка с последующим отбором корректных программ методом проверки сгенерированного предложения на соответствие ASM спецификации (см. [], []). Достоинство этого подхода состоит в использовании формальной спецификации для описания класса корректных программ. Однако недостатком подхода является несистематичность и неэффективность процесса построения тестов. Другой подход состоит в генерации тестов на основе модели входных данных back-end'а в соответствии с некоторым критерием тестового покрытия, формулируемым в терминах модели (см. [], []). Достоинствами подхода являются использование формальных моделей данных и эффективная генерация тестов. В качестве недостатка можно указать необходимость ручной разработки некоторых компонентов генератора тестов.
Для решения задачи построения автоматического оракула для back-end'а предлагаются следующие подходы. Ряд исследователей рассматривает способы построения оракулов для тестирования некоторых специальных видов оптимизаторов, основанные на анализе абстрактного внутреннего представления программы (см. [], []). Их достоинство состоит в четкой нацеленности на проверку оптимизатора. Однако недостатком подобных подходов является то, что, как правило, при тестировании реального компилятора внутреннее представление программы недоступно извне. Попытка избавиться от этого недостатка основана на идее инструментирования объектного кода компилятором []. Однако здесь проблема заключается в том, что для реализации этой идеи требуется вмешательство непосредственно в работу компилятора, что обычно невозможно сделать при тестировании реального коммерческого компилятора.
Принципиально другим подходом к построению автоматического оракула для back-end'а является предлагаемый в ряде работ оракул, который проверяет сохранение семантики программы в процессе компиляции путем сравнения поведения откомпилированной программы с некоторым эталоном. Имеются исследования, в которых в качестве эталона рассматривается поведение той же программы, но откомпилированной другим «эталонным» компилятором []. Близкий подход состоит в сравнении трассы выполнения теста с эталонной трассой []. В других исследованиях в качестве эталона рассматривается поведение той же программы, интерпретируемой ASM машиной (см. [], []). Эти подходы являются вполне приемлемыми, однако они годятся лишь для случая тестирования компиляторов и интерпретаторов.
Литература
| 1.обратно | B. Beizer. Software Testing Techniques. // van Nostrand Reinhold, 1990. |
| 2.обратно | A.G. Duncan, J.S.Hutchison. Using Attributed Grammars to Test Designs and Implementation // In Proceedings of the 5th international conference on Software engineering. Piscataway, NJ, USA: IEEE Press, 1981. 170-178. |
| 3.обратно | J. Hannan, F. Pfenning. Compiler Verification in LF. // Proc. 7th Annual IEEE Symposium on Logic in Computer Science (1992) 407-418. |
| 4.обратно | J. Harm, R. Lämmel. Two-dimensional Approximation Coverage // Informatica Journal. 24. 2000. № 3. |
| 5.обратно | C. Jaramillo, R. Gupta, M.L. Soffa. Comparison Checking: An Approach to Avoid Debugging of Optimized Code. // ACM SIGSOFT 7th Symposium on Foundations of Software Engineering and European Software Engineering Conference, LNCS, 1687 (1999) 268-284. |
| 6.обратно | A. Kalinov, A. Kossatchev, M. Posypkin, V. Shishkov. Using ASM Specification for automatic test suite generation for mpC parallel programming language compiler. // Proc. Fourth International Workshop on Action Semantic, AS'2002, BRICS note series NS-02-8 (2002) 99-109. |
| 7.обратно | A.S. Kossatchev, P. Kutter, M.A Posypkin. Automated Generation of Strictly Conforming Tests Based on Formal Specification of Dynamic Semantics of the Programming Language // Programming and Computing Software. July 2004. Volume 30. Issue 4. 218-229. |
| 8.обратно | V. Kuliamin, A. Petrenko. Applying Model Based Testing in Different Contexts. // Proceedings of seminar on Perspectives of Model Based Testing, Dagstuhl, Germany, September 2004. |
| 9.обратно | R. Lämmel. Grammar testing // In Proc. of Fundamental Approaches Software Engineering. 2029. 2001. 201-216. |
| 10.обратно | W. McKeeman. Differential testing for software. // Digital Technical Journal, 10(1):100-107, 1998. |
| 11.обратно | T.S. McNerney. Verifying the Correctness of Compiler Transformations on Basic Blocks using Abstract Interpretation. // In Symposium on Partial Evaluation and Semantics-Based Program Manipulation (1991) 106-115. |
| 12.обратно | G. Necula. Translation Validation for an Optimizing Compiler. // Proc. ACM SIGPLAN Conference on Programming Language Design and Implementation (2000) 83-95. |
| 13.обратно | A.K. Petrenko. Specification Based Testing: Towards Practice // LNCS 2244. 2001. 287-300. |
| 14.обратно | P. Purdom. A Sentence Generator For Testing Parsers // BIT. 1972. № 2. 336-375. |
| 15.обратно | M. Wand, Zh. Wang. Conditional Lambda-Theories and the Verification of Static Properties of Programs. // Proc. 5th IEEE Symposium on Logic in Computer Science (1990) 321-332. |
| 16.обратно | M. Wand. Compiler Correctness for Parallel Languages. // Conference on Functional Programming Languages and Computer Architecture (FPCA) (1995) 120-134. |
| 17.обратно | М.В. Архипова. Генерация тестов для семантических анализаторов // Вычислительные методы и программирование. 2006, том.7, раздел 2, 55-70. |
| 18.обратно | А.В. Баранцев, И.Б. Бурдонов, А.В. Демаков, С.В. Зеленов, А.С. Косачев, В.В. Кулямин, В.А. Омельченко, Н.В. Пакулин, А.К. Петренко, А.В. Хорошилов. Подход UniTesK к разработке тестов: достижения и перспективы. // Труды ИСП РАН, Москва, 2004, т. 5, 121-156. |
| 19.обратно | А.В. Демаков. TreeDL: язык описания графовых структур данных и операций над ними. // Вычислительные методы и программирование. 2006, том 7, раздел 2, 117-127. |
| 20.обратно | А.В. Демаков, С.В. Зеленов, С.А. Зеленова. Генерация тестовых данных сложной структуры с учетом контекстных ограничений. // Труды ИСП РАН, Москва, 2006, т. 9, 83-96. |
| 21.обратно | С.В. Зеленов, С.А. Зеленова. Генерация позитивных и негативных тестов для парсеров // Программирование, том. 31, №6, 2005, 25-40. |
| 22.обратно | С.В. Зеленов, С.А. Зеленова, А.С. Косачев, А.К. Петренко. Применение модельного подхода для автоматического тестирования оптимизирующих компиляторов |
| 23.обратно | С.В. Зеленов, Д.В. Силаков. Автоматическая генерация тестовых данных для оптимизаторов графических моделей. // Труды ИСП РАН, Москва, 2006, т. 9, 129-141. |
| 24.обратно | RelaxNG. |
Построение оракула для генератора кода
В подходе к построению оракула для тестированию генераторов кода в трансляторах, предлагаемом в настоящей работе, реализуется классическая идея сравнения реального результата работы тестируемой системы с ожидаемым результатом [].
В качестве основы для организации тестирования применяется модельный подход, описанный выше в предварительных сведениях. Однако в нашем случае из каждой модельной структуры генератор тестов, кроме собственно входных тестовых данных,ё должен создавать также и ожидаемый эталонный результат трансляции - либо полностью, либо лишь некоторую абстрактную выжимку, своего рода систему показателей, характеризующих ключевые свойства выходных данных транслятора. Для этого генератор тестов должен содержать два разных меппера: один для отображения модельной структуры во входные тестовые данные, другой для ее отображения в эталонную систему показателей выходных данных (см. Рис. 3).
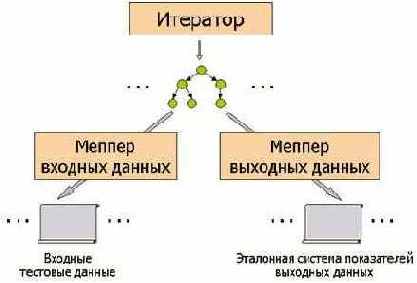
Рис. 3.Схема генерации входных данных и эталонного результата
Для того чтобы было возможно организовать два разных отображения из одной модельной структуры, модель должна строиться с учетом информации не только о входном представлении данных (см. ), но и об их выходном представлении.
В простейшем случае, когда транслятор лишь «переводит» термины входного представления в какие-то соответствующие термины выходного представления, оказывается, что одна и та же модель пригодна для моделирования как входных, так и выходных данных.
В случае же, когда транслятор сначала осуществляет некоторый анализ входных данных, а лишь затем генерирует выходные данные, содержащие результаты проведенного анализа, модель следует обогатить дополнительными элементами, которые представляют собой соответствующие результаты анализа. При этом итерацию модельных структур следует организовать так, чтобы элементы модели, соответствующие «результатам анализа», конструировались непосредственно в процессе итерации - это возможно, например, если организовать итерацию одних элементов модели в зависимости от уже созданного значения другого элемента модели.
Далее мы будем говорить о предложенной схеме генерации тестовых данных в контексте тестирования не всего генератора кода в целом, а лишь некоторого ограниченного его аспекта, поскольку это существенно упрощает модель и облегчает разработку итераторов и мепперов.
Итак, генератор тестов вместе с входными данными генерирует также соответствующую эталонную систему показателей выходных данных.
При использовании такой схемы генерации тестовых данных анализ правильности работы генератора кода в трансляторе состоит в проверке результата работы транслятора на соответствие созданной генератором тестов эталонной системе показателей (см. Рис. 4).

Предварительные сведения
В работе [] предложен подход к автоматическому тестированию оптимизирующих компиляторов на основе моделей. Модель строится на основе абстрактного описания алгоритма заданной оптимизации.
Алгоритм оптимизации формулируется с использованием терминов, обозначающих сущности некоторого подходящего абстрактного представления программы, такого как граф потока управления, граф потока данных, таблица символов и пр. Оптимизатор для осуществления своих трансформаций ищет сочетания сущностей абстрактного представления программы, которые удовлетворяют некоторым шаблонам (например, наличие в программе циклов, наличие в теле цикла конструкций с определенными свойствами, наличие в процедуре общих подвыражений, наличие между инструкциями зависимости данных некоторого вида и пр.).
После анализа алгоритма строится модель: каждому термину соответствует свой элемент модели, причем элементы модели могут путем связывания друг с другом образовывать структуры, соответствующие шаблонам.
Процесс генерации тестов осуществляется следующим образом. Перебираются (итерируются) различные модельные структуры, которые потом отображаются (меппируются) в соответствующие программы на входном языке компилятора (см. Рис. 2).

Рис. 2. Общая схема работы генератора тестов
Такой генератор дает возможность получать тесты на исходном языке, в которых присутствуют конструкции, соответствующие выделенным терминам, в различных комбинациях при минимальном содержании других конструкций языка. Таким образом, генератор оказывается «нацеленным» на создание тестов для тестирования именно заданного оптимизатора.
В рамках этого подхода оракул проверяет только сохранение семантики выполнения программы во время оптимизации. Для этого в качестве тестовых воздействий на оптимизатор генерируются такие программы, семантика выполнения которых полностью представляется их трассой. Такое свойство тестов позволяет свести задачу проверки сохранения семантики к сравнению трассы выполнения откомпилированного теста с некоторой эталонной трассой.
Описанный подход успешно применялся для генерации тестов не только для тестирования компиляторов языков программирования, но также для тестирования оптимизаторов графических моделей [], реализации протокола IPv6, подсистемы построения отчетов в биллинговой системе, обработчиков XML-логов [].
A. UML-диаграммы моделей

Рис. 5. Модель структуры БД (без ограничений)

Рис. 6. Модель ссылочных ограничений в SQL
| 1(к тексту) | Этот транслятор разрабатывался в ИСП РАН в рамках проекта по созданию инструментальной поддержки для автоматической генерации тестовых данных сложной структуры []. |
В качестве примера применения предложенного
В качестве примера применения предложенного подхода рассмотрим тестирование генератора кода в трансляторе , который отображает описание схемы БД на языке SQL в описание структуры таблиц на языке RelaxNG [] и в описание ограничений, наложенных на эту структуру, на языке XML. Ниже описаны модели для трех аспектов работы данного генератора кода: Трансляция основных конструкций структуры БД (таблицы, столбцы, типы данных) без каких-либо ограничений; Трансляция ссылочных ограничений; Трансляция ограничений вида «CHECK». Модели структур входных данных задаются в виде формальных описаний на языке TreeDL []. Генераторы тестов разрабатывались на языке программирования Java с использованием инструмента OTK (см. [], []), который предоставляет поддержку описанного метода разработки тестов. В первой модели, описывающей структуру БД без ограничений, моделируются понятия: таблицы, столбцы, типы данных SQL и их параметры. UML-диаграмма для этой модели приведена в приложении (см. ). В качестве эталонной системы показателей для этого аспекта использовалось описание структуры БД на языке RelaxNG в том виде, в котором его должен сгенерировать транслятор. В данном случае одна и та же модель подходит для моделирования как входных, так и выходных данных: транслятор просто «переводит» такие понятия, как «таблица», «столбец» и т.д., в описание элементов с соответствующими тегами на языке RelaxNG. Работа оракула заключается в текстуальном сравнении RelaxNG-файла - результата работы транслятора с эталонным RelaxNG-файлом. Во второй модели, описывающей ссылочные ограничения, моделируются понятия: таблица, ссылка между двумя таблицами. UML-диаграмма для этой модели приведена в приложении (см. ). В качестве эталонной системы показателей для этого аспекта использовалось описание ограничений на языке XML в том виде, в котором его должен сгенерировать транслятор. Для обеспечения корректной генерации входных тестовых данных модель была дополнена информацией о столбцах, а также был введен объемлющий модельный элемент, моделирующий схему БД в целом. При итерации структур зависимостей между таблицами в генераторе тестов применялась вспомогательная абстрактная модель, которая моделирует ациклические графы.
Эти графы использовались в качестве «макета» для построения конкретных модельных структур. Работа оракула заключается в текстуальном сравнении XML-файла - результата работы транслятора с эталонным XML-файлом. Третья модель, описывающая ограничения вида «CHECK», моделирует следующие понятия: логические выражения, SQL-предикаты (такие, как «LIKE», «BETWEEN» и т.д.). UML-диаграмма для этой модели приведена в приложении (см. Приложение А). В качестве эталонной системы показателей для этого аспекта использовалось описание ограничений на языке XML в том виде, в котором его должен сгенерировать транслятор. Для обеспечения корректной генерации входных тестовых данных модель была дополнена информацией о столбцах, таблицах и объемлющей схеме, а также, для обеспечения корректности применения конкретных SQL-предикатов к данным, были добавлены типы данных. Работа оракула заключается в текстуальном сравнении XML-файла - результата работы транслятора с эталонным XML-файлом. Отметим, что та часть третьей модели, которая отвечает за моделирование типов данных, была целиком переиспользована из первой модели. Более того, были переиспользованы и соответствующие компоненты генератора тестов. В Таб. 1 приведены размеры формальных описаний разработанных моделей, а также размер кода разработанных компонентов генераторов тестов. Отметим, что подавляющее большинство компонентов генераторов тестов было сгенерировано автоматически.
Модель Количество элементов модели Размер модели (байт / строк) Количество классов Размер классов (Кбайт/строк) Всего Вручную Всего Вручную
| Структура БД | 36 | 4519 / 314 | 48 | 2 | 95 / 2669 | 8 / 271 |
| Ссылочные ограничения | 6 | 1165 / 65 | 16 | 7 | 25 / 847 | 10 / 378 |
| Ограничения вида «CHECK» | 51 | 6456 / 444 | 73 | 7 | 148 / 4039 | 20 / 679 |
Как видно из этой таблицы, в модели, описывающей ограничения вида «CHECK», около 60% кода описания модели и около 40% кода компонентов генератора тестов переиспользуется из других моделей.
Модель Количество элементов модели Размер модели (байт / строк) Количество классов Размер классов (Кбайт/строк) Всего Вручную Всего Вручную
| Ограничения вида «CHECK» | 33 | 3816 / 276 | 37 | 2 | 60 / 1717 | 8 / 271 |
Модель Количество тестов Общий объем (Кбайт) Средний размер теста (байт / строк)
| Структура БД | 151 | 826 | 5471 / 140 |
| Ссылочные ограничения | 38 | 353 | 9297 / 235 |
| Ограничения вида "CHECK" | 46 | 915 | 19891 / 455 |
Тестирование трансляторов: проблема построения оракула для генератора кода
Гингина В.В., Зеленов С.В., Зеленова С.А.
Труды Института системного программирования РАН
к тому, что во все
Развитие компьютерной индустрии и информационных технологий привело к тому, что во все большем числе областей бизнеса обработка документов производится автоматически с помощью компьютеров. Чтобы быть пригодными для компьютерной обработки, данные оформляются в виде формального текста, т.е. текста на некотором формальном языке. Транслятор - это программа, осуществляющая обработку формального текста и перевод его в некоторое другое представление. Примерами трансляторов являются компиляторы и интерпретаторы языков программирования, XML-процессоры, браузеры HTML-страниц, системы поддержки специфицирования и моделирования, текстовые процессоры и издательские системы, серверы запросов СУБД и проч. Трансляторы используются при разработке ПО, при организации работы сетевых приложений, при создании разного рода распределенных информационных систем и т.д. Широкое распространение трансляторов, их повсеместное как прямое, так и косвенное использование в различных областях компьютерной индустрии, включая критические, обуславливает высокие требования к качеству трансляторов. Существует много разных подходов к достижению качества программного обеспечения (ПО). Одним из подходов является проведение аналитического доказательства корректности ПО. Вопросам теоретического обоснования корректности поведения компиляторов на основе использования различных логических исчислений посвящены, например, работы [], [], []. Однако, при разработке программных систем высокой сложности, какими являются реальные трансляторы, более практичным подходом является тестирование []. При тестировании встают две основные проблемы: Проблема систематического создания тестовых данных для испытания работы тестируемой системы во всех различных ситуациях. Проблема построения оракула для вынесения вердикта о корректности работы тестируемой системы. Ввиду сложности и насыщенности современных формальных языков, для которых разрабатываются трансляторы, очень велики объемы добротных наборов тестов и сложность анализа результатов тестирования.
Поэтому очень актуальна проблема автоматизации как процесса создания тестовых данных, так и процедуры вынесения вердикта. Наиболее многообещающим в плане автоматизации подходом является тестирование на основе формальных спецификаций и моделей []. В трансляторах традиционно выделяют следующие функциональные блоки: front-end, осуществляющий синтаксический разбор и семантический анализ входного текста и построение его внутреннего представления, и back-end, осуществляющий дополнительный анализ входных данных, возможно, некоторые оптимизирующие преобразования, а также собственно генерацию выходного представления (см. Рис. 1).
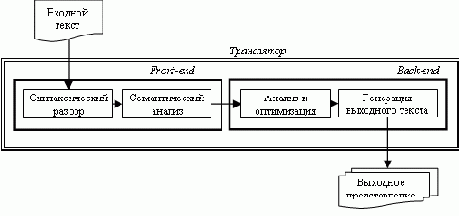
В статье предложен общий подход
В статье предложен общий подход к построению автоматического оракула для тестирования генераторов кода в трансляторах текстов на формальных языках, а также предложена инструментальная поддержка для практического использования этого подхода. Архитектура оракула основана на идее одновременной генерации как тестовых входных данных для транслятора, так и соответствующей эталонной системы показателей, характеризующих ключевые свойства выходных данных транслятора. Несмотря на то, что в ходе разработки необходимых компонентов генератора тестов фактически требуется разработка своего рода «эталонного генератора кода», количество требуемых для этого ресурсов, как правило, существенно меньше того количества ресурсов, которое требуется на разработку реального генератора кода в тестируемом трансляторе. Экономия достигается за счет следующих факторов: модель, для которой требуется разработать «эталонный генератор кода», является абстракцией исходного языка выходных данных транслятора, для которого разрабатывается реальный генератор кода, и поэтому, как правило, модель существенно меньше и проще реального языка; разрабатываемый «эталонный генератор кода» должен, на самом деле, генерировать не все выходные данные, а лишь абстрактную систему показателей, объем данных которой, как правило, гораздо меньше; при разработке генераторов тестов для нескольких аспектов тестирования одного транслятора одни и те же термины часто присутствуют в моделях для нескольких аспектов тестирования, что обуславливает высокий процент переиспользования кода компонентами генераторов тестов. Направлениями дальнейшего развития предложенного подхода являются: проработка методов построения модели на основе анализа входных и выходных данных транслятора; разработка методов выделения эталонных систем показателей выходных данных; разработка методов сравнения реального результата работы транслятора на соответствие эталонной системе показателей выходных данных для различных практически используемых частных видов языков выходных данных трансляторов.
Алгоритм построения тестового набора
Разработанный алгоритм сначала проверяет полученный на вход граф состояний документа согласно следующим ограничениям целостности: Граф должен содержать ровно одно начальное состояние и как минимум одно конечное состояние, достижимое из начального. При нарушении этого условия выдаётся сообщение об ошибке, и алгоритм прекращает работу. Граф не должен содержать состояний, недостижимых из начального или из которых не достижимо ни одно конечное состояние. При обнаружении таких состояний выдаётся предупреждение, и они удаляются из графа вместе со всеми инцидентными им переходами.
После проверки входного графа состояний документа генерируются все возможные на нём тесты. Каждый тест моделируется маршрутом по графу, ведущим из начального состояния в одно из конечных. Тесты генерируются без ограничения длины, но со следующим ограничением: рассматриваются только такие маршруты, которые проходят через каждое состояние не более 2 раз. Такое ограничение позволяет разумно ограничить количество тестов, из которых будет в дальнейшем конструироваться тестовый набор, гарантируя притом покрытие любого элементарного события (включая петлевые дуги, а также такие дуги и вершины, которые недостижимы на путях без циклов), но не гарантирует покрытие всех возможных упорядоченных пар событий. Применение данного алгоритма на графах реально используемых документов, даже с очень сложными критериями покрытия, показало, что такое ограничение оставляет непокрытыми только тестовые ситуации настолько нетривиальные, что ими в большинстве случаев можно пренебречь. При завершении работы инструмент выдаёт вместе с построенных тестовым набором список непокрытых тестовых ситуаций для дальнейшего анализа и, при необходимости, ручной доработки тестового набора.
Далее строится полный набор тестовых ситуаций, которые необходимо покрыть, согласно правилам, описанным в главе «Критерии тестового покрытия», и из него удаляются тестовые ситуации некоторых особых видов, в частности: Ситуации вида «Начальное состояние после любого события», как заведомо недостижимые. Ситуации вида «Операция создания документа после любого события, кроме начального состояния», как заведомо недостижимые. Ситуации вида «Любое событие не после начального состояния», как заведомо недостижимые. Ситуации вида «Переход после своего начального состояния», как заведомо дублирующие ситуации «Переход после начального состояния документа», так как одна ситуация не может быть достигнута при не достигнутой другой. Ситуации вида «Переход не после своего начального состояния», как заведомо недостижимые.
Для каждого построенного на предыдущем шаге теста вычисляется множество тестовых ситуаций, покрываемых им.
Все построенные тестовые ситуации считаются при дальнейшей оптимизации тестового набора равноценными. Далее из построенного множества путей строится тестовый набор минимальной сложности, покрывающий все возможные тестовые ситуации, с помощью нижеописанного эвристического алгоритма. В записи алгоритма используются следующие условные обозначения:
|S| - мощность множества S Len(t) ? длина теста t, измеряемая в количестве тестовых воздействий {} ? пустое множество <> - пустой упорядоченный список
Фиксируем ограничение длины тестов M, которое является параметром данного алгоритма. Полагаем множество непокрытых тестовых ситуаций C:= полный набор построенных ранее тестовых ситуаций, множество доступных тестов T:= полный набор ранее построенных тестов, а тестовый набор R:=<>. Тестовый набор строится в две итерации: на первой рассматриваются только тесты с длиной, не превышающей M, а на второй рассматриваются все оставшиеся тесты. На каждой итерации применяется следующий «жадный» алгоритм:
Для каждого теста t из T вычисляем Cov(t):= множество тестовых ситуаций из C, покрываемых им. Если Cov(t)={}, то удаляем t из T. Перебираем в произвольном порядке все тесты t из всего множества T на второй итерации, и только те тесты, длина которых не превышает M, на первой. Если перебираемое множество пусто, то завершаем текущую итерацию. Ищем среди перебираемых тестов лучший следующим образом:
Первый встреченный в ходе перебора тест объявляем лучшим. Каждый следующий тест в ходе перебора сравниваем с текущим лучшим по следующим критериям сравнения, по порядку:
если Len(t1) ≤ M и Len(t2) > M, то t1 лучше; если тесты t1 и t2 оба укладываются в ограничения по длине и при этом |Cov(t1)| > |Cov(t2)|, то t1 лучше; если |Cov(t1)| ≥ |Cov(t2)| и Len(t1) < Len(t2), то t1 лучше; если |Cov(t1)| > |Cov(t2)| и Len(t1) ≤ Len(t2), то t1 лучше; если оба теста t1 и t2 не укладываются в ограничения по длине и (Len(t1 - Len(t2))*P < (|Cov(t1)|-|Cov(t2)|), где P ? параметр алгоритма, то t1 лучше.
Если проверки 2.2.1?2.2.5 показывают, что проверяемый тест лучше предыдущего лучшего, то объявляем лучшим его, и далее сравниваем другие перебираемые тесты уже с ним.
Если проверяемый тест признан хуже или ни одна проверка не выносит вердикт, что один тест лучше другого, то продолжаем считать лучшим тот же тест, что и раньше.
Добавляем найденный лучший тест t в конец списка R и удаляем из множества непокрытых тестовых ситуаций C все элементы множества Cov(t). Переходим к шагу 1.
Правило сравнения 2.2.1 гарантирует, что в первую очередь все возможные тестовые ситуации будут покрываться тестами с длиной, не превышающей максимальную. Правило 2.2.2 выбирает тесты с максимально возможным (в пределах ограничения длины) тестовым покрытием ? в большинстве случаев эта эвристика позволяет уменьшить суммарную длину тестов в наборе за счёт уменьшения их количества. Правила 2.2.3 и 3.2.4 отдают предпочтение тестам, улучшающим покрытие или длину и не ухудшающим притом другую из этих двух характеристик. Согласно правилу 2.2.5 из двух тестов, превышающих максимальную длину, один предпочтительнее другого, если увеличение длины компенсируется (с учётом весового параметра P) увеличением покрытия. Поскольку алгоритм эвристический, и в нём используется перебор по неупорядоченному множеству, в общем случае результаты его работы не детерминированы: при разных запусках на одних и тех же данных возможна генерация различных тестовых наборов; однако в большинстве случаев сгенерированные таким образом наборы имеют одинаковые метрики. Для настройки алгоритма используются параметры M и P. M: задаёт максимальную длину тестов генерируемого набора, превышение которой допускается только для покрытия недостижимых иными способами тестовых ситуаций. Допустимые значения: целое положительное число или +∞. P: задаёт вес превышения максимальной длины тестов по отношению к повышению покрытия. При больших значениях параметра алгоритм в первую очередь выбирает из тестов, превышающих максимальную длину и добавляющих хотя бы какое-то тестовое покрытие, самые короткие, что позволяет уменьшить максимальную длину тестов, но может приводить к существенному увеличению суммарной сложности тестового набора; при малых значениях алгоритм в первую очередь выбирает тесты, покрывающие большее количество тестовых ситуаций, что позволяет минимизировать суммарную сложность тестового набора за счёт добавления в него очень длинных тестов.Допустимые значения: неотрицательные числа (можно нецелые). Оптимальные значения обоих параметров зависят от размера и структуры графа состояний документа, от требований к тестовому покрытию и от возможностей тестировщиков исполнять длинные тесты. В ходе апробации алгоритма установлено, что в большинстве случаев оптимальное значение для параметра M немного превосходит длину самого длинного возможного в графе маршрута без циклов, ведущего из начального состояния в конечное, а для параметра P лежит в диапазоне [0; 2].
Генерация готового к исполнению тестового набора
Основным результатом работы инструмента является набор тестов, в котором каждый тест представляет собой пошаговую инструкцию для тестировщика. Каждая такая инструкция представляет собой последовательный список, состоящий из воздействий на документ и проверок, которые надо выполнить.
Инструмент генерирует проверки следующих видов: Проверка успешности выполнения воздействия. Проверка состояния документа. Проверка считается успешной, если состояние документа соответствует ожидаемому. Проверка списка воздействий, доступных для определённой роли. Проверка считается успешной, если список доступных для данной роли воздействий совпадает с указанным списком. Список воздействий может быть пустым. Проверка списка воздействий, доступных для всех остальных ролей, включая не описанные в используемой для генерации тестов модели документа.
Если в ходе исполнения теста какая-то из проверок не прошла успешно, то мы считаем, что тест обнаружил ошибку.
Для генерации инструкции тестировщику в построенном, отфильтрованном и отсортированном тестовом наборе для каждого теста строится последовательность происходящих в нём элементарных событий: воздействий и состояний. Далее для каждого события определяются тестовые ситуации, добавляемые им к множеству тестовых ситуаций, покрытых в рамках тестового набора ранее, то есть, предыдущими тестами из набора, а также предыдущими элементарными событиями данного теста.
Для каждого выполняемого в ходе теста воздействия генерируется указание тестировщику выполнить его (с указанием ролей, которыми можно его выполнять, или указанием, что роль может быть любой) и проверить успешность выполнения.
Для достигнутых в ходе теста состояний проверки генерируются в зависимости от того, добавляет ли достижение данного состояния покрытие новых тестовых ситуаций: если попадание в состояние (с учётом предыстории элементарных событий данного теста) не даёт нового покрытия, то генерируется только указание проверить полученное состояние документа; если тестовое покрытие увеличилось (то есть, мы впервые попали в данное состояние или впервые попали в него с такими существенными элементами предыстории), то дополнительно генерируются проверки воздействий, доступных различным ролям.
Для каждой роли «правильное» множество доступных воздействий состоит из:
Всех доступных согласно спецификации в текущем состоянии воздействий, не помеченных списком допустимых ролей.
В частности, сюда относятся воздействия, которые выполняются не пользователями системы: например, тайм-аут можно выполнить, войдя в систему под любой ролью или даже вообще не входя в неё. Всех доступных воздействий, помеченных списком допустимых ролей, таких что в их список входит данная роль.
Проверки генерируются для каждой роли, встречающейся в пункте 2. Также генерируется проверка воздействий, доступных всем остальным ролям ? в соответствующий список входят все доступные в текущем состоянии воздействия, не помеченные списком допустимых ролей.
Поскольку проверки возможных воздействий генерируются только при достижении новых в рамках тестового набора элементов покрытия, сортировка тестов по длине позволяет сбалансировать сложность их исполнения: первые тесты набора коротки, но на каждом шаге дают новые элементы покрытия, а следовательно, и проверки; последние тесты набора длинны, но новые элементы покрытия в них возникают лишь иногда. Разумеется, после того, как тестовый набор сгенерирован и сбалансирован, составляющие его тесты можно без изменений исполнять в произвольном порядке, не теряя при этом тестового покрытия.
Генерация оптимизированных для
, ,
Труды Института системного программирования РАН
Критерии тестового покрытия
Элементарными событиями будем называть события следующих видов: Попадание документа в заданное состояние. Применение к документу в заданном состоянии заданного тестового воздействия.
Поскольку нам необходимо протестировать все состояния и воздействия, возможные в ЖЦ документа, то естественным образом возникает первый критерий тестового покрытия:достижение всех элементарных событий.
Каждое элементарное событие принадлежит некоторому тесту, моделирующему ЖЦ одного документа. События внутри теста линейно упорядочены.
Событие B будем считается наступившим после события A, если оба эти события произошли внутри одного теста, и событие B произошло в нём позже события A. Событие B будем считать наступившим не после события A, если в рамках теста, которому оно принадлежит, ему не предшествовало событие A.
В состоянии документа возможны скрытые составляющие, которые влияют на поведение системы. Они могут изменяться при попадании документа в некоторые критичные состояния или при применении к нему некоторых критичных воздействий. Например, если документ был удалён, а потом восстановлен, это может отразиться на его дальнейшем поведении. Элементарные события, которые предположительно могут влиять таким образом на поведение, будем называть существенными в истории событиями.
Для тестирования таких возможных аномалий поведения введем второй критерий тестового покрытия: достижение каждого элементарного события отдельно после и не после каждого события, существенного в истории. В общем случае все существенные в истории события могут соответствовать различным взаимно независимым скрытым элементам состояния документа, и различные возможные комбинации наличия/отсутствия в истории документа таких событий соответствуют потенциально различным состояниям. Однако, чтобы избежать комбинаторного взрыва состояний и излишней сложности тестирования, существенные в истории события рассматриваются независимо друг от друга, и покрытие возможных их комбинаций не учитывается.
Для особых случаев введем третий критерий тестового покрытия: разработчик тестов имеет возможность на основании дополнительных знаний о системе дополнительно отмечать интересующие его пары элементарных событий и требовать покрытия одного события в паре после и/или не после другого.
Элементы всех трёх критериев покрытия могут быть представлены как достижение некоторого элементарного события B после или не после некоторого элементарного события А.
События такого вида мы будем называть тестовыми ситуациями. При этом первый критерий покрытия порождает все возможные тестовые ситуации вида «B после A», где в качестве элементарного события A выступает начальное состояние графа, а в качестве элементарного события B ? все определённые в графе состояний документа элементарные события. Второй критерий покрытия порождает все возможные тестовые ситуации видов «B после A» и «B не после A», где в качестве A выступают существенные в истории элементарные события, а в качестве B ? определённые в графе состояний документа элементарные события. Элементы третьего критерия покрытия переводятся в тестовые ситуации очевидным образом. При разработке тестов документооборота для оценки полноты тестового покрытия используется составной критерий достижения всех тестовых ситуаций, построенных для модели ЖЦ документа по вышеописанным правилам из трех вышеописанных критериев. В дальнейшем под критерием покрытия имеется ввиду только этот критерий покрытия.
Литература
Cost Benefits Analysis of Test Automation, Douglas Hoffman, Software Quality Methods, LLC, 1999 Автоматическая генерация тестов для графического пользовательского интерфейса по UML диаграммам действий, Калинов А.Я., Косачёв А.С., Посыпкин М.А., Соколов А.А., Труды Института Системного Программирования РАН, 2005
Модель приложения
Документ в системе документооборота может находиться в различных состояниях. Переход между состояниями осуществляется при помощи воздействий на документ через ГИП. В системе документооборота определены роли пользователей, при этом воздействия делятся на 3 класса в зависимости от того, кем они могут осуществляться: определённым набором ролей; любым пользователем системы, независимо от его роли: не пользователями системы (например, тайм-аут).
Предполагается, что при тестировании мы имеем возможность входить в систему документооборота в любой определённой в её спецификации роли, проверять возможность или невозможность осуществления воздействий данной ролью, а также осуществлять над документом любое описанное в спецификации воздействие. В противном случае соответствующие роли и воздействия исключаются из используемой для тестирования модели документа.
Входными данными задачи тестирования документооборота являются список ролей пользователей системы и описание жизненного цикла (ЖЦ) документа. Описание ЖЦ представляется в виде графа состояний Конечного Автомата (КА), начальное состояние которого соответствует началу ЖЦ, переходы из начального состояния ? различным способам создания документа данного типа, конечное состояние (их может быть несколько) ? завершению ЖЦ, прочие состояния ? промежуточным состояниям документа, а переходы ? воздействиям на документ. Если воздействие относится к первому классу, то соответствующий переход КА помечен списком ролей, которым разрешено выполнять соответствующее воздействие.
В используемой нами модели также предусмотрена возможность пометить некоторые воздействия (желательно, но не обязательно оставляющие документ в том же состоянии), которые мы считаем надёжными или по каким-то другим причинам не хотим тестировать. Например, редактирование текста документа, которое доступно (возможно, не всем ролям) практически в любом состоянии документа и не переводит притом его в другое состояние. Для таких воздействий мы проверяем возможность их осуществления, но не выполняем их в ходе теста.
Используя такую модель, мы получаем возможность использовать для тестирования систем документооборота методы тестирования КА, адаптированные к особенностям предметной области. В выбранном нами методе тестирования каждый тест описывает ЖЦ некоторого документа от создания до уничтожения и, соответственно, моделируется некоторым маршрутом по графу состояний модельного КА, ведущим из начального его состояния в конечное.
Оптимизация и балансировка тестового набора
Далее производится фильтрация и сортировка построенного набора тестов R; при этом используется упорядоченность тестового набора по времени добавления в него тестов.
Для фильтрации вычисляется полный набор тестовых ситуаций, покрываемых каждым тестом из построенного тестового набора, и для каждого теста проверяется, добавляет ли он какое-либо тестовое покрытие к суммарному покрытию тестов, добавленных в набор после него (напоминаем, что при добавлении «поздних» тестов в набор учитывалось только то покрытие, которое они добавляли к уже имеющемуся на момент добавления); если все тестовые ситуации, покрываемые тестом, покрываются объединением более поздних тестов, то он удаляется из построенного набора.
Отфильтрованный таким образом набор тестов сортируется по длине: самые короткие (по количеству тестовых воздействий) тесты ставятся в начало набора, а самые длинные ? в его конец; это позволяет в дальнейшем сбалансировать количество проверок, выполняемых в различных тестах набора.
Оптимизация тестового набора
Нами выделены следующие критерии оптимизации, которые необходимо учитывать при создании тестов для ручного тестирования, в порядке понижения их приоритета: Максимизация тестового покрытия. Минимизация суммарной трудоёмкости тестового набора. Ограничение трудоёмкости отдельных тестов: поскольку тесты исполняются не машиной, а человеком, то при превышении тестом некоторого порога сложности сильно возрастает вероятность ошибки тестировщика, в результате которой этот тест придётся исполнять заново.
Эти критерии оптимизации противоречат друг другу: так, увеличение полноты тестового покрытия вызывает увеличение трудоёмкости отдельных тестов и тестового набора в целом, а ограничение длины отдельных тестов обычно приводит к увеличению количества таких тестов и, как следствие, суммарной сложности тестового набора, так как зачастую в различных тестах одного набора приходится заново выполнять одни и те же действия.
Исходя из приоритетов поставленной задачи тестирования, была поставлена задача многокритериальной оптимизации набора тестов, для которой выбрана следующая стратегия решения:
Фиксируем некое разумное (с учётом размера и структуры графа состояний документа) ограничение на длину отдельных тестов. Длиной теста здесь и далее считается количество применяемых в нём тестовых воздействий. Строим тестовый набор с минимальной суммарной длиной тестов, удовлетворяющий следующим ограничениям:
Каждый тест в составе тестового набора имеет длину не выше заданной. Тестовый набор должен обеспечивать покрытие всех возможных при ограничении 2.1 тестовых ситуаций.
Если некоторые тестовые ситуации могут быть покрыты только тестами длины большей, чем заданное в п.1 ограничение, то строим тесты минимальной суммарной длины, покрывающие все такие тестовые ситуации, и добавляем их к построенному тестовому набору.
В этом случае проверяем, не покрывают ли добавленные на шаге 3 длинные тесты сразу все тестовые ситуации, покрываемые какими-то из ранее построенных коротких тестов, и при обнаружении таких «лишних» коротких тестов удаляем их из тестового набора.
Пример применения
Инструмент реализован на языке Java версии 1.5 и предоставляет программный интерфейс, позволяющий сконструировать граф состояний документа, разметить в нём переходы списками ролей, пометить некоторые переходы как не тестируемые, задать критерии покрытия и параметры работы главного алгоритма, после чего запустить генерацию тестов. Ввод данных может осуществляться специально написанной для данного графа программой на языке Java (которую можно считать текстовой формой представления графа) или специально разработанными конвертерами, которые будут обходить граф в некотором другом представлении и вызывать соответствующие методы данного интерфейса.
Граф представленный на Рис. 1 был создан на основе анализа требований к реально существующему приложению системы документооборота, после чего дополнительно усложнён для получения нетривиальных путей (например, добавлено состояние «Отложен», недостижимое на путях без циклов). Почти в каждом состоянии документа возможны также его редактирование и комментирование, причём оба этих воздействия не меняют состояние документа с точки зрения данной автоматной модели. Для сокращения трудоёмкости тестирования в большинстве состояний их решено не тестировать, а учесть в списке не тестируемых воздействий, для которых при тестировании только проверяется возможность их выполнения; в результате на рисунке фигурируют только те петлевые дуги этих двух видов, которые решено тестировать дополнительно. Чтобы не загромождать излишне приведённый рисунок, на нём также не отображены списки ролей, которыми помечены переходы графа.
В результате применения генератора тестов к приведённому на Рис. 1 графу с параметром M=12 (параметр P в данном случае несущественен, так как все сгенерированные тесты укладываются в ограничение по длине) и без дополнительных требований к покрытию он выдаёт тестовый набор следующего вида (приводится с сокращениями): Test #0: [+] <Начать тест> [+] Действие: Создать 2; роль: [Автор] [ ] Проверка: действие завершено успешно [ ] Проверка: состояние документа = Черновик [ ] Проверка: доступные действия: [ ] Действия, доступные для роли Автор: [ ] Отправить в секретариат [ ] Редактировать [ ] Удалить [ ] <Других нет> [ ] Действия, доступные для всех остальных: <пусто> [+] Действие: Удалить; роль: [Автор] [ ] Проверка: действие завершено успешно [ ] Проверка: состояние документа = Удаленный 1 [ ] Проверка: доступные действия: [ ] Действия, доступные для роли Автор: [ ] Восстановить [ ] <Завершить тест> [ ] <Других нет> [ ] Действия, доступные для всех остальных: [ ] <Завершить тест> [ ] <Других нет> [+] Действие: <Завершить тест>; роль: <любая> [ ] Проверка: действие завершено успешно [ ] Проверка: жизненный цикл документа завершен ------------------------ Test #1: [+] <Начать тест> [+] Действие: Создать 2; роль: [Автор] [ ] Проверка: действие завершено успешно [ ] Проверка: состояние документа = Черновик [+] Действие: Отправить в секретариат; роль: [Автор] [ ] Проверка: действие завершено успешно [ ] Проверка: состояние документа = Согласование [ ] Проверка: доступные действия: [ ] Действия, доступные для роли Автор: [ ] Редактировать [ ] Комментировать [ ] <Других нет> [ ] Действия, доступные для роли Визирующий: [ ] Комментировать [ ] Согласовать [ ] <Других нет> [ ] Действия, доступные для роли Подписывающий: ... [ ] Действия, доступные для роли Секретарь: [ ] Редактировать [ ] Отправить на доработку [ ] Комментировать ... [ ] Действия, доступные для всех остальных: <пусто> [+] Действие: Согласовать; роль: [Визирующий, Подписывающий, Секретарь] [ ] Проверка: действие завершено успешно [ ] Проверка: состояние документа = Визирование [ ] Проверка: доступные действия: ... [+] Действие: Отправить на доработку; роль: [Визирующий, Секретарь] [ ] Проверка: действие завершено успешно [ ] Проверка: состояние документа = Доработка [ ] Проверка: доступные действия: ... [+] Действие: Удалить; роль: [Автор] [ ] Проверка: действие завершено успешно [ ] Проверка: состояние документа = Удаленный 2 [ ] Проверка: доступные действия: ... [+] Действие: Восстановить; роль: [Автор] [ ] Проверка: действие завершено успешно [ ] Проверка: состояние документа = Доработка [+] Действие: Удалить; роль: [Автор] [ ] Проверка: действие завершено успешно [ ] Проверка: состояние документа = Удаленный 2 [+] Действие: <Завершить тест>; роль: <любая> [ ] Проверка: действие завершено успешно [ ] Проверка: жизненный цикл документа завершен ------------------------ Test #2: ...
Также выдаются метрики построенного тестового набора и список непокрытых тестовых ситуаций: Total: 5 pathes, sum length = 45 transitions Maximal path length = 12 Uncovered elements: <empty>
Ручной анализ приведённого графа ЖЦ документа и сгенерированного для него тестового набора показывает, что тестовый набор меньшей длины, покрывающий все переходы, невозможен.
Тестовый набор может быть распечатан в таком виде и передан тестировщику. Значок «[ ]» служит местом, куда тестировщик может ставить отметки об успешном выполнении проверок.
Тестирование софта - статьи
Аннотация. В статье описывается решение задачи построения последовательностей действий пользователя, оптимизированных для ручного выполнения, на основе модели в виде диаграммы состояний и переходов. Сценарии для ручного выполнения необходимы, во-первых, когда графический интерфейс является единственной возможностью взаимодействия с приложением, а его реализация не предусматривает или делает экономически невыгодным программную эмуляцию воздействий через него. Во-вторых, тестовые наборы для ручного выполнения могут быть необходимы для оценки практичности графического интерфейса пользователя, для проверки его соответствия выбранным стандартам и для приемочного пользовательского тестирования.
Тестовые проверки
В первую очередь тестируется живучесть системы документооборота и её способность выполнять заявленные воздействия. Проверяется, что система не завершает аварийно работу при выполнении осуществляемых над документом воздействий.
Поскольку спецификация ЖЦ документа представлена в виде графа состояний, при тестировании мы проверяем изоморфизм наблюдаемого графа состояний документа модельному графу. Для этого в каждом состоянии мы проверяем список доступных в нём воздействий (соответствующих переходам из состояния), а после выполнения каждого тестового воздействия проверяем, соответствует ли полученное состояние документа ожидаемому. Расхождение между ожидаемым и полученным состоянием считается ошибкой и требует исправления тестируемой системы или пересмотра спецификации.
Согласно используемой модели некоторые воздействия могут быть выполнены только определёнными ролями; для тестирования этого требования мы проверяем соответствие между ролями и доступными им воздействиями. Обнаруженная в ходе тестирования невозможность осуществить некоторой ролью воздействие, которое описано в спецификации как возможное для неё, равно как и наоборот, считается ошибкой.
Другие проверки в данную модель не входят, но могут быть добавлены при ручной доработке сгенерированного по ней тестового набора.
и прочно занял доминирующее положение
Графический интерфейс пользователя (ГИП) давно и прочно занял доминирующее положение среди способов взаимодействия с прикладными программами (приложениями) общего назначения. Взаимодействие пользователей с офисными и корпоративными приложениями в подавляющем большинстве случаев заключается в совершении некоторых последовательностей действий с графическим интерфейсом. Поэтому для обеспечения качества современных программных продуктов важной задачей является проверка корректности внешнего поведения приложений при взаимодействии пользователя с ГИП. Такая проверка предполагает выполнение различных сценариев, состоящих из последовательностей воздействий на приложение через ГИП, с проверкой промежуточных и конечного результатов. Выполнение таких последовательностей вручную представляет из себя рутинную ресурсоемкую деятельность, особенно при необходимости неоднократного воспроизведения одних и тех же сценариев, например, при регрессионном тестировании. Поэтому существующие инструменты автоматизации тестирования приложений с ГИП прежде всего нацелены на автоматизацию выполнения тестов: воспроизведение заранее заданных (как правило, вручную) сценариев взаимодействия с приложением через ГИП. Для автоматизации выполнения тестов необходимо иметь возможность через какой-то интерфейс подавать стимулы, то есть воздействовать на тестируемую программу, и принимать реакции, то есть наблюдать за тем, что делает программа в ответ на эти воздействия. Для программ с ГИП подача стимулов на логическом уровне означает эмуляцию действий пользователя, таких как нажатие кнопок, ввод данных в поля ввода, выбор элементов из списков и так далее. На физическом уровне ввод данных требует от инструмента возможности эмулировать нажатие кнопок на клавиатуре, а нажатие кнопок и выбор элементов из списка могут быть выполнены как с клавиатуры, так и эмуляцией действий с мышью ? перемещение и нажатие кнопок манипулятора. Для наблюдения реакций необходимо распознавать элементы ГИП, то есть определять наличие тех или иных элементов и получать значения их атрибутов.
Эмуляция действий с мышью также требует умения распознавать элементы ГИП, поскольку координаты объекта на экране являются частным случаем этих атрибутов. Во многих случаях для распознавания элементов ГИП и получения их атрибутов есть возможность использовать специальные программные интерфейсы такие, как, например, интерфейсы графических библиотек Swing/AWT или SWT/RCP/Eclipse на платформе Java , Windows Presentation Framework для приложений на платформе .NET , COM-интерфейсы для программ в Microsoft Word или Microsoft Excel . Однако имеется ряд программ, для которых распознавание элементов ГИП невозможно в силу технологических причин, так как используемая для создания ГИП библиотека не реализует ни один из механизмов доступа к атрибутам объектов. Такие программы позволяют пользователям разработать собственные формы, но используемые при этом элементы ГИП не позволяют получить доступ к их атрибутам. В результате вся созданная пользователем форма распознаётся как один большой элемент (например, типа RichTextBox для IBM Lotus Notes), а находящиеся внутри него элементы распознать не удаётся. Иногда в таких случаях возможно решить проблему автоматизации подачи стимулов с помощью с помощью внедрения внутрь тестируемой программы агентов, которые обеспечивают доступ к требуемой информации об элементах ГИП (например, перекомпиляция Delphi-приложений как Open Application для тестирования с помощью инструмента AutomatedQA TestComplete ). В остальных случаях единственным способом автоматизации подачи стимулов через ГИП является запись и последующее воспроизведение взаимодействий пользователя с интерфейсом в терминах экранных координат и нажатия кнопок мыши и клавиатуры. Основные недостатки такого способа в том, что он позволяет создавать набор регрессионных тестов только для практически законченного и уже функционирующего приложения, и любые изменения не только в функциональности, но и в дизайне ГИП, как правило, требуют переработки тестов. Иногда при такой записи можно использовать определение координат элементов ГИП методом поиска и сравнения фрагментов снимков экрана или поиска распознанного со снимков экрана текста , что несколько снижает зависимость тестов от внешнего расположения элементов, но не позволяет сделать тесты независимыми даже от незначительных изменений дизайна графического интерфейса, при которых инструмент не сможет сопоставить функционально одинаковые элементы в новой и старой версиях интерфейса.
Также снизить зависимость тестов от обновления внешнего вида ГИП иногда позволяет полный отказ от использования мыши и управление тестируемой программой только с помощью клавиатуры, но не во всех приложениях есть возможность доступа ко всем элементам ГИП при помощи клавиатуры. В таких условиях автоматизация тестирования становится экономически невыгодна. Если в обычных условиях, когда распознавание элементов ГИП не вызывает затруднений, расходы на автоматизацию превышают расходы на один цикл ручного тестирования в 3 раза , то усложнение создания и особенно сопровождения тестов, связанное с трудностями распознавания элементов ГИП, по нашим оценкам может увеличить эту цифру ещё в 2-3 раза. Кроме того, в случае приложений с ГИП к значимому для пользователя поведению кроме собственно функциональности приложения относится так же внешний вид интерфейса с точки зрения практичности, соответствия некоторому заданному стандарту, эстетичности и т. д. Автоматизированные тесты, как правило, не предназначены для оценки такого рода характеристик качества. В них обычно программируется только небольшая часть наиболее важных с точки зрения функциональности проверок. Большая часть дефектов, связанных с визуальным представлением ГИП и практичностью, не обнаруживается автоматизированными тестами, например, «выползание» текста за границы, «наползание» элементов ГИП друг на друга, неудобное расположение элементов интерфейса, приводящее к частым ошибкам пользователей и т. п. Поэтому, независимо от наличия или отсутствия автоматизированных тестов, необходимо также иметь тестовый набор для ручного выполнения. При этом он должен обеспечивать заданный уровень полноты тестирования и быть достаточно прост в сопровождении. Отдельный тест из такого ручного набора представляет собой сценарий, состоящий из последовательности действий и проверок, которые должен выполнить тестировщик. В целом тестовый набор должен обеспечивать некоторую полноту тестирования. Поскольку человек более подвержен ошибкам, чем компьютер, сценарии не должны быть слишком длинными, так как в результате ошибки тест придётся выполнять сначала.
В свою очередь, «измельчение» тестов приводит к тому, что некоторые действия приходится выполнять неоднократно, в каждом тесте заново, что также увеличивает общую трудоёмкость. В то же время, нужно стремиться сократить общую трудоёмкость всех тестов, то есть не количество тестов, а суммарную длину последовательностей действий, из которых состоят отдельные тесты, сохраняя при этом приемлемую полноту тестирования. Поэтому при поиске решения необходимо найти способ сохранить баланс между этими противоречивыми требованиями. В статье рассматривается подход, при котором тесты для ручного выполнения генерируются автоматически из некоторой модели, описывающей поведение приложения при взаимодействии с ним пользователя. Такой подход гарантирует полноту покрытия по построению (способ генерации зависит от выбранного критерия полноты) и дает возможность быстро перегенерировать тесты в случае изменения модели (в связи с изменением функциональности приложения или дизайна ГИП). В целях проверки предложенного подхода создана прототипная реализация инструмента генерации тестовых последовательностей для проверки интерфейса приложений, реализованных в системе документооборота на основе Lotus Notes. Платформа Lotus Notes включает в себя интегрированную среду разработки, предоставляющую разработчикам средства для разработки приложений с ГИП, поддерживающих управление документами и данными, а так же рабочими потоками внутри организации. В среде Lotus Notes отсутствуют возможности программного доступа к элементам ГИП. Типичным сценарием взаимодействия с приложением Lotus Notes является последовательность воздействий на некоторый документ, который в результате этих воздействий может переходить в новые состояния. В качестве формализованной модели поведения таких приложений удобно использовать диаграммы состояний и переходов, так как, с одной стороны, при помощи таких диаграмм достаточно естественно описываются состояния документа и переходы между ними при воздействиях пользователя, а с другой стороны, эти диаграммы достаточно формальны для автоматической обработки с целью генерации на их основе тестовых сценариев с заданными свойствами.
в данной работе подход не
Предложенный в данной работе подход не уменьшает и не увеличивает количество работы на этапе создания тестов по сравнению с ручным проектированием тестов, поскольку ручное проектирование в любом случае предполагает создание некоторой модели, может быть чуть менее формализованной, для обеспечения полноты тестирования. В то же время этот подход имеет ряд дополнительных достоинств: гарантированная по построению полнота тестового набора относительно выбранного критерия; минимизация размера тестового набора; простота сопровождения (перегенерации) тестового набора при внесении изменений в функциональность тестируемого приложения или дизайн его ГИП. Сгенерированные сценарии могут использоваться как для ручного выполнения тестов (функционального тестирования, пользовательского приемочного тестирования, тестирования практичности), так и для создания набора регрессионных автоматизированных тестов. Но здесь есть серьёзная проблема. Когда в модель вносятся изменения, вызванные изменениями в реализации, новые сгенерированные тестовые сценарии могут существенно отличаться от тех, которые были сгенерированы по предыдущей модели. Это означает, что автоматизированные тесты придётся создавать заново. Для преодоления этого ограничения планируется разработать механизм генерации непосредственно исполнимого кода тестовых сценариев. Подобный подход генерации исполнимых тестовых сценариев для ГИП по диаграмме состояний и переходов используется, например, в . Но все известные нам решения предполагают интеграцию с уже существующими инструментами автоматизации, то есть неявно накладывают требование на то, чтобы элементы ГИП были распознаваемы и была возможность получения их атрибутов. К сожалению, как мы уже отмечали в начале статьи, требование доступности элементов ГИП выполняется не всегда. Чтобы работать с такими интерфейсами, необходимо помимо логической модели поведения в виде диаграммы состояний и переходов построить также физическую модель ГИП. Используя сочетание этих двух моделей можно достичь следующего уровня автоматизации создания и выполнения тестов. Это является предметом дальнейших исследований и развития описанного в данной статье подхода к разработке тестов.
