Аннотация.
В работе обсуждаются вопросы применимости технологии автоматизированного тестирования UniTesK к разработке функциональных тестов для моделей аппаратного обеспечения. Предлагаются способы расширения базовой архитектуры тестовой системы UniTesK для функционального тестирования моделей на языках Verilog HDL и SystemC. Для каждого из указанных классов моделей описывается процесс разработки теста с помощью инструмента CTesK и приводятся оценки возможности автоматизации шагов этого процесса.
Архитектура тестовой системы
При расширении базовой архитектуры тестовой системы CTesK мы учитывали то обстоятельство, что используемый симулятор Icarus Verilog не позволяет напрямую управлять симуляцией через интерфейс VPI [], используемый нами для интеграции тестовой системой с симулятором. Предлагаемая архитектура тестовой системы показана на Рис. 5.
Тестовая система состоит из двух потоков: потока симулятора Verilog - основного потока; потока тестовой системы CTesK - подчиненного потока.
В начале симуляции при помощи вызова специальной функции из симулятора Verilog в отдельном потоке запускается тестовая система CTesK, которая в цикле предоставляет тестовые воздействия на тестируемую Verilog-модель, принимает реакции на них и оценивает правильность этих реакций.
Verilog-окружение содержит экземпляр тестируемой Verilog-модели. Оно осуществляет инициализацию экземпляра тестируемой модели, запускает через VPI-модуль в отдельном потоке тестовую систему CTesK, от которой в цикле принимает тестовые воздействия и которой передает реакции тестируемой модели на них. Прием тестовых воздействий и передача реакций осуществляются через VPI-медиатор.
VPI-модуль связывает Verilog-окружение с тестовой системой CTesK. Он реализует функцию запуска тестовой системы CTesK и содержит в качестве составной части VPI-медиатор.
VPI-медиатор связывает экземпляр тестируемой Verilog-модели с медиатором тестовой системы CTesK. Он реализует прием тестовых воздействий от тестовой системы CTesK и посылку реакций тестируемой модели на них, а также осуществляет синхронизацию состояний экземпляра тестируемой модели и спецификационной модели данных тестовой системы CTesK.
Тестовая система CTesK выполняется в симуляторе SystemC, она подает на тестируемую SystemC-модель тестовые воздействия, принимает реакции на них и оценивает правильность этих реакций. Взаимодействие тестовой системы CTesK и тестируемой SystemC-модели осуществляется через C-медиатор.
C-медиатор представляет собой реализацию программного интерфейса на языке программирования C, предназначенного для доступа к экземпляру тестируемой SystemC-модели. C-медиатор используется медиатором тестовой системы CTesK для подачи тестовых воздействий и приема реакций.
Модуль запуска тестовой системы предназначен для запуска тестовой системы CTesK в симуляторе SystemC.
Архитектура тестовой системы UniTesK
Архитектура тестовой системы UniTesK [] была разработана на основе многолетнего опыта тестирования промышленного программного обеспечения из разных предметных областей и разной степени сложности. Учет этого опыта позволил создать гибкую архитектуру, основанную на следующем разделении задачи тестирования на подзадачи []: Построение последовательности тестовых воздействий, нацеленной на достижение нужного покрытия. Создание единичного тестового воздействия в рамках последовательности. Установление связи между тестовой системой и реализацией целевой системы. Проверка правильности поведения целевой системы в ответ на единичное тестовое воздействие.
Для решения каждой из этих подзадач предусмотрены специальные компоненты тестовой системы: для построения последовательности тестовых воздействий и создания единичных воздействий - обходчик и итератор тестовых воздействий, для проверки правильности поведения целевой системы - оракул, для установления связи между тестовой системой и реализацией целевой системы - медиатор. Рассмотрим подробнее каждый из указанных компонентов.
Обходчик является библиотечным компонентом тестовой системы UniTesK и предназначен вместе с итератором тестовых воздействий для построения последовательности тестовых воздействий. В основе обходчика лежит алгоритм обхода графа состояний конечного автомата, моделирующего целевую систему на некотором уровне абстракции.
Итератор тестовых воздействий работает под управлением обходчика и предназначен для перебора в каждом достижимом состоянии конечного автомата допустимых тестовых воздействий. Итератор тестовых воздействий автоматически генерируется из тестового сценария, представляющего собой описание конечно-автоматной модели целевой системы.
Оракул оценивает правильность поведения целевой системы в ответ на единичное тестовое воздействие. Он автоматически генерируется на основе формальных спецификаций, описывающих требования к целевой системе в виде пред- и постусловий интерфейсных операций и инвариантов типов данных.
Медиатор связывает абстрактные формальные спецификации, описывающие требования к целевой системе, с конкретной реализацией целевой системы.
Трасса теста отражает события, происходящие в процессе тестирования. На основе трассы можно автоматически генерировать различные отчеты, помогающие в анализе результатов тестирования.
Инструмент разработки тестов CTesK
Инструмент CTesK [], используемый в данной работе, является реализацией концепции UniTesK для языка программирования C. Для разработки компонентов тестовой системы в нем используется язык SeC (specification extension of C), являющийся расширением ANSI C. Инструмент CTesK включает в себя транслятор из языка SeC в C, библиотеку поддержки тестовой системы, библиотеку спецификационных типов и генераторы отчетов. Для пользователей Windows имеется модуль интеграции в среду разработки Microsoft Visual Studio 6.0.
Компоненты тестовой системы UniTesK реализуются в инструменте CTesK с помощью специальных функций языка SeC, к которым относятся: спецификационные функции - содержат спецификацию поведения целевой системы в ответ на единичное тестовое воздействие, а также определение структуры тестового покрытия; медиаторные функции - связывают спецификационные функции с тестовыми воздействиями на целевую систему; функция вычисления состояния теста - вычисляет состояние конечного автомата, моделирующего целевую систему. сценарные функции - описывают набор тестовых воздействий для каждого достижимого состояния теста;
Обходчик из библиотеки инструмента CTesK требует, чтобы конечный автомат, способ построения которого описан в тестовом сценарии (с помощью функций двух последних видов), являлся детерминированным, а также имел сильно связный граф состояний.
Краткий обзор технологии UniTesK
Технология UniTesK была разработана в ИСП РАН на основе опыта, полученного при разработке и применении технологии KVEST (kernel verification and specification technology) []. Общими чертами этих технологий являются использование формальных спецификаций в форме пред- и постусловий интерфейсных операций и инвариантов типов данных для автоматической генерации оракулов (компонентов тестовой системы, осуществляющих проверку правильности поведения целевой системы), а также применение конечно-автоматных моделей для построения последовательностей тестовых воздействий.
В отличие от технологии KVEST, в которой для спецификации требований использовался язык RSL (RAISE specification language) [], технология UniTesK использует расширения широко известных языков программирования. На данный момент в ИСП РАН разработаны инструменты, поддерживающие работу с расширениями языков C, Java и C#: CTesK [], J@T [] и Ch@se [] соответственно.
Литература
| 1. | - сайт, посвященный технологии тестирования UniTesK и реализующим ее инструментам. |
| 2. | А.В. Баранцев, И.Б. Бурдонов, А.В. Демаков, С.В. Зеленов, А.С. Косачев, В.В. Кулямин, В.А. Омельченко, Н.В. Пакулин, А.К. Петренко, А.В. Хорошилов. Подход UniTesK к разработке тестов: достижения и перспективы. Опубликовано на http://www.citforum.ru/SE/testing/unitesk/. |
| 3. | В.В. Кулямин, А.К. Петренко, А.С. Косачев, И.Б. Бурдонов. Подход UniTesK к разработке тестов. Программирование, 29(6): 25-43, 2003. |
| 4. | - сайт Института системного программирования РАН; |
| 5. | А.К. Поляков. Языки VHDL и VERILOG в проектировании цифровой аппаратуры. - М.: СОЛОН-Пресс, 2003. |
| 6. | - сайт, посвященный языку SystemC. |
| 7. | - сайт, посвященный языку System Verilog. |
| 8. | Bergeron, Janick. Writing testbenches: functional verification of HDL models. Kluwer Academic Publishers, 2000. |
| 9. | - страница инструмента CTesK. |
| 10. | В. Немудров, Г. Мартин. Системы-на-кристалле. Проектирование и развитие. Москва: Техносфера, 2004. |
| 11. | I. Bourdonov, A. Kossatchev, A. Petrenko, and D. Galter. KVEST: Automated Generation of Test Suites from Formal Specifications. FM'99: Formal Methods. LNCS 1708, Springer-Verlag, 1999, pp. 608-621. |
| 12. | The RAISE Language Group. The RAISE Specification Language. Prentice-Hall BCS Practitioner Series. Prentice-Hall, Inc., 1993. |
| 13. | - страница инструмента J@T. |
| 14. | - страница инструмента Ch@se. |
| 15. | - страница симулятора Icarus Verilog. |
| 16. | - сайт, посвященный набору инструментов MinGW. |
| 17. | Sutherland, Stuart. The Verilog PLI handbook: A User's Guide and Comprehensive Reference on the Verilog Programming Language Interface. Springer, 2002. |
| 1(обратно к тексту) | Мы не рассматриваем здесь разного рода неопределенные значения, часто используемые в моделировании аппаратного обеспечения. |
| 2(обратно к тексту) | В дальнейшем будем называть такие процессы модельными процессами, чтобы отличать их от процессов операционной системы. |
| 3(обратно к тексту) | В начале симуляции активными процессами являются процессы, осуществляющие инициализацию. |
| 4(обратно к тексту) | VCD (Value Change Dump) - формат для описания изменений значений сигналов во времени. |
| 5(обратно к тексту) | В случае если одно тестовое воздействие может активизировать несколько модельных процессов, схема тестирования немного усложняется: для проверки правильности поведения модели нужно использовать возможные сериализации реакций активизированных процессов. |
| 6(обратно к тексту) | Если в тесте есть тестовое воздействие, включающее фронт (срез) некоторого сигнала, то в нем должно присутствовать тестовое воздействие, включающее срез (фронт) этого сигнала. |
| 7(обратно к тексту) | VPI (Verilog Procedural Interface) или PLI (Programming Language Interface) 2.0 - стандартный интерфейс, предназначенный для вызова из Verilog-модулей функций, написанных на языке программирования C и других языках программирования. |
Модели аппаратного обеспечения и технология UniTesK
Теперь, после того как мы сделали краткий обзор технологии UniTesK и рассмотрели особенности моделей аппаратного обеспечения на языках высокого уровня, обсудим вопрос о применимости технологии UniTesK к функциональному тестированию таких моделей. Традиционная архитектура тестовой системы для тестирования моделей аппаратного обеспечения выглядит следующим образом:
Тестовый модуль (testbench) последовательно подает на тестируемую модель тестовые воздействия и осуществляет проверку правильности реакций на них. Результатом теста является VCD-файл, создаваемый симулятором и содержащий изменения значений сигналов на входах и выходах тестируемой модели во времени. Полученный файл обычно используется для визуализации волновой диаграммы теста - традиционного средства анализа результатов тестирования.
Наша цель - расширить тестовый модуль так, чтобы он включал в себя полномасштабную тестовую систему CTesK.
Для начала рассмотрим следующие общие вопросы: Как специфицировать модели аппаратного обеспечения на языке SeC. Как использовать понятие времени в рамках технологии UniTesK. Как адаптировать тестовую систему CTesK к выполнению в симуляторе.
Сначала рассмотрим вопрос о спецификации моделей аппаратного обеспечения. Для каждого процесса, определенного в модели, классифицируем используемые им входы на управляющие, информационные и несущественные. Будем называть вход управляющим, если процесс реагирует на возникающие на данном входе события, информационным, если значение сигнала на данном входе влияет на поведение процесса, все остальные входы будем называть несущественными.
Под единичным тестовым воздействием будем понимать непустое непротиворечивое множество событий из списка чувствительности одного из процессов, реализованных одновременно, а также набор значений сигналов на информационных входах этого процесса. Предположим, что списки чувствительности процессов, определенных в модели, попарно не пересекаются, а управляющие входы одного процесса не являются информационными входами другого.
При таких ограничениях, тестовое воздействие может активизировать только один модельный процесс. Для спецификации модели на языке SeC, множество всех тестовых воздействий должно быть разбито на группы, каждая из которых описывается одной спецификационной функцией. Один из возможных подходов разбиения состоит в следующем. Каждому процессу, определенному в модели, ставится в соответствие отдельная спецификационная функция, параметры которой отражают множество событий из списка чувствительности, реализуемые на управляющих входах, а также значения подаваемых на информационные входы сигналов. В предусловии спецификационной функции, помимо разного рода смысловых проверок, должна осуществляться проверка того, что значения сигналов на управляющих входах процесса позволяют реализовать указанные в параметрах события, а в постусловии - то, что указанные события действительно были реализованы. Проиллюстрируем этот подход на примере. Рассмотрим модуль на языке Verilog HDL.
module Module(x, y, z, r); input x, y, z; output r; reg r;
always @(posedge(x), negedge(y)) begin: Process r = z; end
endmodule
Интерфейс модуля состоит из трех входов: x, y, z и одного выхода r. Для процесса, определенного в модуле, входы x и y являются управляющими, а вход z - информационным. При возникновении фронта сигнала на входе x или среза сигнала на входе y процесс присваивает r значение сигнала на входе z. Для спецификации возможности наступления событий из списка чувствительности процесса, состояние спецификационной модели данных должно включать текущие значения сигналов на входах x и у.
// спецификационная модель данных модуля
typedef struct
{ // текущие значения сигналов на входах x и y bool x, y;
} Module;
Спецификационная функция, описывающая поведение процесса, будет иметь в качестве параметров указатель на состояние спецификационной модели данных, индикаторы событий из списка чувствительности и значение информационного входа z.
// спецификационная функция процесса specification bool Process(Module *module, bool posedge_x, bool negedge_y, bool z)
// процесс читает какие события произошли,
// а также значение информационного входа z
reads posedge x, negedge _y, z // тестовое воздействие изменяет значения
// сигналов на управляющих входах
updates x = module->x, y = module->y { pre
{ // проверка возможности реализации событий return ((posedge x negedge _y) &&
(posedge х => !x) && (negedge у => y)); }
post
{ // проверка реализации событий
return ((posedge x => x) && (negedge у => !y)) && Process == z; } }
Заметим, что данный подход к выделению спецификационных функций является достаточно общим, а потому не всегда оптимальным.
При его использовании можно автоматически генерировать шаблон спецификации по исходному коду модели. В приведенном примере проверки, допускающие автоматическую генерацию, подчеркнуты. После того как определены спецификационные функции, тестовый сценарий разрабатывается обычным для инструмента CTesK образом: с помощью функции вычисления состояния и сценарных функций описывается конечный автомат теста, используемый для построения последовательности тестовых воздействий. Отметим следующие моменты. Для того, чтобы выполнимость предусловий спецификационных функций определялась только состоянием теста, без использования более детальной информации об истории тестовых воздействий, состояния теста должны включать текущие значения сигналов на управляющих входах. Для того, чтобы граф состояний конечного автомата был сильно связен, необходимо чтобы для каждого события, используемого в тестовых воздействиях, существовало тестовое воздействие с обратным событием, так как в противном случае образуются тупиковые состояния теста. В общем случае, поведение моделей аппаратного обеспечения определяется не только последовательностью тестовых воздействий, но и длительностью временных интервалов между ними. Это характерно, например, для моделей устройств с таймерами. Для качественного тестирования таких моделей нужно уметь подбирать и комбинировать длительности временных интервалов между тестовыми воздействиями. Поскольку в технологии UniTesK для построения последовательностей тестовых воздействий используются конечно-автоматные модели, естественно моделировать изменение времени с помощью специальных переходов. Это могут быть как просто переходы по времени, в которых изменяется только модельное время, а значения входных сигналов остаются неизменными, так и совмещенные переходы, в которых изменяются и модельное время, и значения входных сигналов. С точки зрения спецификации, изменение модельного времени является параметром соответствующей переходу спецификационной функции. Интересные для тестирования изменения модельного времени перебираются в тестовом сценарии. Теперь несколько слов об адаптации тестовой системы к выполнению в симуляторе.
Чтобы тестовая система могла быть выполнена в симуляторе, она должна быть оформлена как отдельный модельный процесс. При этом возможны две различные ситуации: когда тестовая система может напрямую управлять выполнением этого модельного процесса (см. раздел ) и когда не может (см. раздел ). В первом случае, для адаптации тестовой системы практически не требуется разработки дополнительных модулей. Главное, чтобы после подачи очередного тестового воздействия, модельный процесс, в котором выполняется тестовая система, приостанавливался, чтобы симулятор мог активизировать процесс тестируемой модели, занимающийся обработкой поданного воздействия. Приостановка процесса тестовой системы реализуется в медиаторных функциях. Во втором случае, требуется разработать специальный модуль симулятора, называемый окружением тестируемой модели, который взаимодействует с тестовой системой, запущенной в виде отдельного потока. К функциям этого модуля относятся прием тестовых воздействий от тестовой системы, их подача на тестируемую модель, а также передача реакций тестируемой модели тестовой системе.
Особенности моделей аппаратного обеспечения
Модели аппаратного обеспечения на таких языках как Verilog HDL [] и SystemC [] представляют собой системы из нескольких взаимодействующих модулей. Как и в языках программирования, модули используются для декомпозиции сложной системы на множество независимых или слабо связанных подсистем. Каждый модуль имеет интерфейс - набор входов и выходов, через которые осуществляется соединение модуля с окружением, и реализацию, определяющую способ обработки модулем входных сигналов: вычисление значений выходных сигналов и изменение внутреннего состояния.
Обработка модулем входных сигналов инициируется событиями со стороны окружения. Под событиями в моделях аппаратного обеспечения понимают любые изменения уровней сигналов. Поскольку обычно рассматривают двоичные сигналы, выделяют два основных вида событий: фронт сигнала (posedge, positive edge) - изменение уровня сигнала с низкого на высокий и срез сигнала (negedge, negative edge) - изменение уровня сигнала с высокого на низкий.
Как правило, каждый модуль состоит из нескольких статически заданных параллельных процессов, каждый из которых реализует следующий цикл: сначала осуществляется ожидание одного или нескольких событий из заданного набора событий, затем их обработка, после чего цикл повторяется. Набор событий, ожидаемых процессом для обработки, называется списком чувствительности (sensitive list) процесса. Будем называть процесс пассивным, если он находится в состоянии ожидания событий, и активным в противном случае.
Важной особенностью моделей аппаратного обеспечения является наличие в них понятия времени: поведение таких моделей определяется не только последовательностью событий, но и длительностью временных интервалов между ними. Время моделируется дискретной целочисленной величиной, физический смысл единицы времени можно задавать. Для описания причинно-следственных отношений между событиями, происходящими в одну единицу модельного времени используется понятие дельта-задержки (delta delay). События, между которыми есть дельта-задержка, выполняются последовательно одно за другим, но в одну и ту же единицу модельного времени.
Для выполнения моделей с целью анализа их поведения обычно используют симуляцию по событиям (event-driven simulation).
В отличие от симуляции по интервалам времени (time-driven simulation), в которой значения сигналов и внутренние состояния модулей вычисляются через регулярные интервалы времени, в этом способе модель рассматривается только в те моменты времени, когда наступают некоторые события. Работа событийного симулятора (event-driven simulator) осуществляется следующим образом. В начале симуляции модельное время устанавливается в ноль. Далее в цикле, пока есть активные процессы, выбирается один из них и выполняется до тех пор, пока этот процесс не станет пассивным. После того, как выполнены все активные процессы, симулятор проверяет, есть ли события, запланированные через дельта-задержку на текущий момент времени. Если такие события есть, симулятор реализует эти события и перевычисляет множество активных процессов, после чего цикл повторяется. Если, после очередного выполнения цикла, событий запланированных на текущий момент времени нет, симулятор проверяет, есть ли события, запланированные на будущие моменты времени. Если таких событий нет, симуляция заканчивается, в противном случае, симулятор изменяет модельное время на время ближайшего события, реализует события, запланированные на этот момент времени и перевычисляет множество активных процессов, после чего цикл повторяется.
Применение технологии UniTesK для функционального тестирования моделей аппаратного обеспечения
, , ,
Препринт Института системного программирования РАН (ИСП РАН)
Пример счетчика
Рассмотрим пример небольшого устройства - счетчика, на Verilog- и SystemC-моделях которого мы будем иллюстрировать основные шаги разработки тестов. Интерфейс счетчика состоит из двух двоичных входов inc и rst и одного целочисленного выходного регистра cnt.
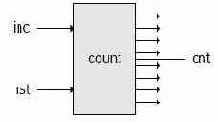
Рис. 4.Схема входов и выходов счетчика.
В ответ на фронт сигнала inc, устройство увеличивает содержимое регистра cnt на единицу, на фронт rst - обнуляет регистр cnt. Срезы сигналов не обрабатываются. Для упрощения спецификации и тестирования будем считать, что поведение устройства при одновременном возникновении фронтов сигналов на обоих входах не определено.
Рассмотрим спецификацию счетчика на языке SeC. Спецификационная модель данных включает в себя текущие значения входных сигналов inc и rst, а также выходного регистра cnt:
Если в тесте есть тестовое воздействие, включающее фронт (срез) некоторого сигнала, то в нем должно присутствовать тестовое воздействие, включающее срез (фронт) этого сигнала. // спецификационная модель данных счетчика typedef struct { bool inc; // текущее значение сигнала // на входе inc bool rst; // текущее значение сигнала // на входе rst int cnt; // текущее значение регистра cnt } Model;
Спецификационные функции описывают поведение устройства в ответ на фронты и срезы сигналов inc и rst. Ниже приводится спецификационная функция inc_posedge_spec, описывающая реакцию на фронт сигнала на входе inc. Остальные функции определяются аналогичным образом. // спецификация реакции на фронт сигнала на входе inc specification void inc_posedge_spec(Model *model) updates cnt = model->cnt, inc = model->inc { pre { return model != NULL && inc == false && cnt < INT_MAX; } coverage C { return {single, "Single branch"}; } post { return inc == true && cnt == @cnt + 1; } }
Рассмотрим сценарий тестирования счетчика. В качестве состояния конечного автомата для нашего примера будем просто использовать состояние спецификационной модели, то есть текущие значения входных сигналов inc и rst, а также выходного регистра cnt.
В этом случае функция вычисления состояния конечного автомата будет выглядеть как показано ниже.
static List* scenario_state() { List* list = create_List(&type_Integer);
append_List(list, create_Integer(model.inc)); append List(list, create Integer(model.rst)); append List(list, create Integer(model.cnt));
return list; }
Чтобы ограничить число состояний конечного автомата, запретим подачу фронта inc в состояниях, в которых значение регистра cnt больше или равно десяти. Остальные стимулы (фронт rst, срезы inc и rst) сделаем допустимыми во всех достижимых состояниях. В начальном состоянии теста устанавливаем низкие уровни сигналов inc и rst, а значению регистра cnt присваиваем ноль. Ниже приводится сценарная функция для фронта inc. Остальные функции определяются аналогичным образом.
scenario bool inc_posedge_scen() { if(model.cnt < 10) { if(pre_inc_posedge_spec(&model)) inc posedge spec(&model); }
return true; }
Разработка C-медиатора
Поскольку инструмент CTesK предназначен для разработки тестов для программных интерфейсов на языке программирования С, то из компонентов тестовой системы CTesK нельзя напрямую обращаться к SystemC-модели. Все обращения к тестируемой модели должны осуществляться через специально разработанный С-медиатор, который предоставляет интерфейс для подачи тестовых воздействий и получения реакций тестируемой модели на них.
Ниже приводится интерфейс С-медиатора для SystemC-модели счетчика. #ifdef __cplusplus extern "C" { #endif // #ifdef __cplusplus // интерфейсные функции, осуществляющие // тестовые воздействия // на экземпляр SystemC-модели счетчика void count_inc_posedge(void); void count_rst_posedge(void); void count_inc_negedge(void); void count_rst_negedge(void); // интерфейсные функции, получающие информацию // о состоянии экземпляра SystemC-модели счетчика int count_inc(void); int count_rst(void); int count_cnt(void); #ifdef __cplusplus } #endif // #ifdef __cplusplus
Заметим, что в функциях, реализующих тестовые воздействия, должна осуществляться приостановка модельного процесса тестовой системы для того, чтобы симулятор SystemC мог активизировать процесс тестируемой модели, занимающийся обработкой поданного воздействия.
В инструменте CTesK медиатор реализуется c помощью медиаторных функций, каждая из которых связывает спецификационную функцию с группой тестовых воздействий на целевую систему. Код медиаторной функции состоит из блока воздействия (блока call), в котором осуществляется тестовое воздействие, и блока синхронизации (блока state), в котором осуществляется синхронизация состояния спецификационной модели данных с состоянием целевой системы. Разработку медиатора для Verilog-модели можно осуществить автоматически по следующей схеме:
для каждой спецификационной функции пишется медиаторная функция следующего вида:
блок call≡ {apply_<воздействие>(<параметры>) ;}; блок state ≡ {wait_for_check();}.
Медиаторная функция для спецификационной функции inc posedge spec будет выглядеть следующим образом:
// медиаторная функция для inc_posedge_spec mediator inc_posedge_media for
specification void inc_posedge_spec(Model *model) updates cnt = model->cnt, inc = model->inc { // посылаем тестовое воздействие
call { apply_inc_posedge(model); }
// ожидаем реакции state { wait_for_check(); } }
После того, как создан C-медиатор, разработка медиатора осуществляется по следующей схеме:
разрабатывается функция синхронизации состояний map_state_up, осуществляющая синхронизацию состояния спецификационной модели данных тестовой системы CTesK с состоянием экземпляра тестируемой SystemC-модели; для каждой спецификационной функции пишется медиаторная функция следующего вида:
в блоке call осуществляется вызов соответствующей интерфейсной функции C-медиатора; в блоке state осуществляется вызов функции map_state_up.
Ниже приводится медиаторная функция для спецификационной функции inc_posedge_spec. // медиаторная функция для inc_posedge_spec mediator inc_posedge_media for specification void inc_posedge_spec(Model *model) updates cnt = model->cnt, inc = model->inc { // вызываем соответствующую функцию C-медиатора call { count_inc_posedge(); } // вызываем функцию синхронизации состояний state { map_state_up(model); } }
Видно, что при совпадении интерфейсов C-медиатора и спецификации разработку медиатора можно автоматизировать.
Разработка модуля взаимодействия потоков
Модуль взаимодействия потоков реализует функции синхронизации потока симулятора Verilog и потока тестовой системы CTesK. Эти функции используются медиатором и VPI-модулем, поэтому модуль взаимодействия потоков рекомендуется разрабатывать перед разработкой медиатора или VPI-модуля.
Модуль взаимодействия потоков должен реализовывать следующие функции: wait_for_check - функция ожидания реакции на тестовое воздействие. Вызывается в медиаторе; wait_for_apply - функция ожидания тестового воздействия. Вызывается в VPI-медиаторе, возвращает идентификатор тестового воздействия; apply_check - функция передачи реакции на тестовое воздействие. Вызывается в VPI-медиаторе; apply_finish - функция посылки сообщения о завершения теста. Вызывается тестовой системой CTesK; apply_<воздействие> - функции посылки тестовых воздействий. Вызываются в медиаторе.
Также в модуле взаимодействия потоков можно определить функции: start_scenario - функция запуска тестовой системы CTesK. Вызывается в VPI-медиаторе, создает необходимые для взаимодействия потоков ресурсы, устанавливает имя UniTesK-трассы, запускает в отдельном потоке тестовую систему CTesK; end_scenario - функция завершения работы тестовой системы CTesK. Вызывается в VPI- медиаторе при получении сообщения о завершении теста, освобождает созданные ресурсы.
Так как модуль использует средства создания и взаимодействия потоков, он является платформенно-зависимым. Мы вели разработку на платформе Windows 2000 и использовали механизм событий Win32. Очевидно, что разработку модуля взаимодействия потоков для каждой конкретной платформы можно автоматизировать.
Разработка модуля запуска тестовой системы
Разработка модуля запуска тестовой системы осуществляется по следующей схеме: разрабатывается функцию запуска тестовой системы CTesK; разрабатывается SystemC-модуль для вызова тестовой системы CTesK в отдельном модельном процессе.
Ниже приводится функция count_start, запускающая тестовый сценарий count_scenario. // функция запуска тестового сценария void count_start(const char *trace) { addTraceToFile(trace); count_scenario(0, NULL); }
Ниже приводится SystemC-модуль для вызова тестовой системы CTesK в отдельном модельном процессе. // модуль запуска тестовой системы SC_MODULE(count_testbench) { public: // определяем отдельный модельный процесс SC_CTOR(count_testbench) { SC_THREAD(main); } // метод запуска теста void start(void) { sc_start(); } // процесс тестовой системы CTesK void main(void) { count_start("simulation.unitrace"); } };
Видно, что разработку модуля запуска тестовой системы можно полностью автоматизировать.
Разработка теста
В этом разделе подробно рассматривается процесс разработки теста для Verilog-моделей аппаратного обеспечения с помощью инструмента CTesK. Для иллюстрации процесса будем использовать пример счетчика (см. раздел ), Verilog-модель которого приводится ниже. module count(inc, rst); // входы inc и rst input inc, rst; // выходной регистр cnt integer cnt; // увеличивает счетчик task increment; begin cnt = cnt + 1; end endtask // сбрасывает счетчик task reset; begin cnt = 0; end endtask // в начальном состоянии счетчик сброшен initial begin reset; end // обработчик фронта сигнала на входе inc always @(posedge inc) begin increment; end // обработчик фронта сигнала на входе rst always @(posedge rst) begin reset; end endmodule
Процесс разработки теста состоит из следующих шагов: Разработка спецификации устройства. Разработка модуля взаимодействия потоков. Разработка медиатора. Разработка тестового сценария. Разработка Verilog-окружения. Разработка VPI-модуля.
Рассмотрим подробно каждый из этих шагов за исключением шага разработки спецификации и шага разработки тестового сценария, которые были описаны выше (см. раздел ).
В этом разделе подробно рассматривается процесс разработки теста для SystemC-моделей аппаратного обеспечения с помощью инструмента CTesK. Для иллюстрации процесса будем использовать пример счетчика (см. раздел ), SystemC-модель которого приводится ниже.
SC_MODULE(count) { // входы сигналы inc и rst
sc_in<bool> inc; sc_in<bool> rst;
// выходной регистр cnt int cnt;
// обработчик изменения значения сигнала inc
void increment(void) { if(inc.posedge()) cnt++; }
// обработчик изменения значения сигнала inc void reset(void) { if(rst.posedge()) cnt = 0; }
SC_CTOR(count): cnt(0), inc(false), rst(false) { SC_METHOD(increment); sensitive(inc);
SC_METHOD(reset); sensitive(rst); } };
Процесс разработки теста состоит из следующих шагов: Разработка C-медиатора. Разработка спецификации системы. Разработка медиатора. Разработка тестового сценария. Разработка модуля запуска тестовой системы.
Рассмотрим подробно каждый из этих шагов за исключением шага разработки спецификации и шага разработки тестового сценария, которые были описаны выше (см. раздел ).
Разработка Verilog-окружения
Verilog-окружение представляет собой модуль верхнего уровня на языке Verilog HDL и разрабатывается по следующей схеме: для каждого входа тестируемой Verilog-модели внутри Verilog-окружения определяется однотипный регистр; определяется экземпляр тестируемой Verilog-модели target, в качестве аргументов которого выступают определенные ранее регистрами; определяется блок initial, внутри которого: устанавливается имя VCD-файла и трассируемые в него сигналы; вызывается системная задача $startScenario, запускающая тестовую систему CTesK; в цикле с помощью системной функции $applyAction принимаются тестовые воздействия от тестовой системы CTesK и с помощью системной задачи $checkAction посылаются реакции на них.
Ниже приводится Verilog-окружение для Verilog-модели счетчика: module testbench(); parameter delay = 10; // входы экземпляра тестируемой Verilog-модели reg inc, rst; // экземпляр тестируемой Verilog-модели count target(inc, rst); initial begin // устанавливаем имя VCD-файла и // трассируемые сигналы $dumpfile("simulation.vcd"); $dumpvars(1, testbench); // запускаем тестовую систему CTesK $startScenario(); #(delay); // в цикле получаем тестовые воздействия и // передаем реакции на них while($applyAction() == 0) begin #(delay); $checkAction(); #(delay); end end endmodule
Verilog-окружение использует системные задачи $startScenario, $checkAction и системную функцию $applyAction, которые должны быть реализованы в VPI-модуле. Видно, что разработку Verilog-окружения можно полностью автоматизировать.
Разработка VPI-модуля
VPI-модуль разрабатывается на языке программирования C с использованием интерфейса VPI. Он должен реализовывать следующие системные функции и задачи: $startScenario - вызывает функцию start_scenario модуля взаимодействия потоков; $applyAction - вызывает функцию wait_for_action модуля взаимодействия потоков и в зависимости от возвращаемого значения производит необходимые изменения входных сигналов тестируемой Verilog-модели; $checkAction - осуществляет синхронизацию состояний экземпляра Verilog-модели и спецификации тестовой системы CTesK, после этого вызывает функцию apply_check модуля взаимодействия потоков;
Системная функция $applyAction и системная задача $checkAction образуют VPI-медиатор. Видно, что разработку части VPI-модуля, связанную с запуском тестовой системы CTesK, можно полностью автоматизировать.
Тестирование SystemC-моделей
В этом разделе предлагается способ расширения базовой архитектуры тестовой системы UniTesK для функционального тестирования SystemC-моделей аппаратного обеспечения. Описывается процесс разработки теста с помощью инструмента CTesK и приводятся оценки возможности автоматизации шагов этого процесса.
Помимо инструмента CTesK и свободно распространяемой библиотеки SystemC, нами использовалась среда разработки Microsoft Visual Studio 6.0.
Тестирование Verilog-моделей
В этом разделе предлагается способ расширения базовой архитектуры тестовой системы UniTesK для функционального тестирования Verilog-моделей аппаратного обеспечения. Описывается процесс разработки теста с помощью инструмента CTesK и приводятся оценки возможности автоматизации шагов этого процесса.
Помимо инструмента CTesK, нами использовались свободно распространяемый симулятор Icarus Verilog [] и компилятор GCC из набора инструментов MinGW [].
Возможность автоматизации шагов разработки
Ниже приводится сводная таблица разрабатываемых модулей, в которой указаны поток выполнения модуля, язык разработки и возможность автоматизации разработки.

В таблице показано, что разработку модуля взаимодействия потоков, медиатора и Verilog-окружения можно автоматизировать полностью, разработку VPI-модуля - частично.
Ниже приводится сводная таблица разрабатываемых модулей, в которой указаны язык разработки модуля и возможность автоматизации его разработки.
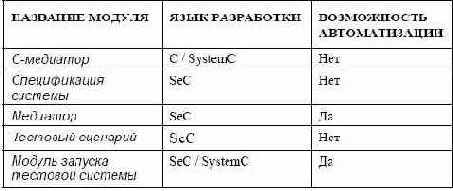
В таблице показано, что разработку медиатора и модуля запуска тестовой системы можно автоматизировать полностью.
в Институте системного программирования РАН
Технология тестирования UniTesK [] была разработана в Институте системного программирования РАН (ИСП РАН) []. Первоначальное и основное назначение технологии - разработка качественных функциональных тестов для программного обеспечения. В работе рассматривается новая и достаточно перспективная область применения технологии UniTesK - функциональное тестирование моделей аппаратного обеспечения. Под моделями аппаратного обеспечения в данной работе понимаются, прежде всего, HDL-модели (HDL models), то есть модели, написанные на каком-нибудь языке описания аппаратуры (HDL, hardware description language), например, на VHDL или Verilog HDL [], а также модели системного уровня, разрабатываемые на таких языках, как SystemC [] или SystemVerilog []. Заметим, что в работе рассматриваются только модели цифрового аппаратного обеспечения. Известно, что слабым звеном в технологической цепочке проектирования сложного аппаратного обеспечения является функциональная верификация. Согласно Бергерону (Janiсk Bergeron) [] функциональная верификация занимает около 70% общего объема трудозатрат, число инженеров, занимающихся верификацией, примерно вдвое превосходит число проектировщиков, а размер исходного кода тестов (testbenches) достигает 80% общего размера кода проекта. Технология UniTesK и реализующие ее инструменты были успешно применены для тестирования различных классов программных систем: ядер операционных систем, телекоммуникационных протоколов, систем реального времени и т.д. Ключевым моментом в успешности применения технологии UniTesK является гибкая архитектура тестовой системы, которая позволяет легко адаптировать технологию к различным классам целевых систем []. В работе предлагаются способы расширения базовой архитектуры тестовой системы UniTesK для функционального тестирования моделей аппаратного обеспечения на языках Verilog HDL и SystemC. Для каждого из указанных классов моделей описывается процесс разработки теста с помощью инструмента CTesK [] и приводятся оценки возможности автоматизации шагов этого процесса.
При расширении архитектуры тестовой системы мы руководствовались тем соображением, что трудоемкость разработки дополнительных компонентов теста должна быть минимальной. Языки Verilog HDL и SystemC были выбраны для исследования по следующим причинам. Язык Verilog HDL, на ряду с VHDL, является классическим языком описания аппаратуры, но, в отличие от последнего, он имеет близкий к языку программирования C синтаксис и стандартный интерфейс для вызова функций, написанных на С [], что облегчает интеграцию с инструментом CTesK, кроме того, он гораздо чаще используется на практике для проектирования сложного аппаратного обеспечения. Что касается SystemC, он является современным и многообещающим языком системного уровня, позволяющим моделировать системы со смешанными аппаратными и программными частями (HW/SW) []. Таким образом, были выбраны два достаточно разных языка: один - классический язык описания аппаратуры, другой - современный язык системного уровня. Структура статьи такова. Во втором, следующем за введением, разделе делается краткий обзор технологии UniTesK и инструмента CTesK. В третьем разделе рассматриваются особенности моделей аппаратного обеспечения и то, как эти особенности соотносятся с технологией UniTesK. Там же описывается пример небольшого устройства, для которого с помощью инструмента CTesK разрабатываются спецификация и сценарий тестирования. В четвертом и пятом разделах описывается процесс разработки теста для Verilog- и SystemC-моделей соответственно. В заключении рассматриваются направления дальнейшего развития предлагаемого подхода.
Взаимодействие компонентов
Ниже показана последовательность взаимодействия основных компонентов тестовой системы. Чтобы не вдаваться в детали внутренних взаимодействий, такие компоненты, как обходчик и итератор тестовых воздействий, объединены на диаграмме в один компонент - генератор.
При вызове $startScenario из Verilog-окружения VPI-модуль запускает в отдельном потоке тестовую систему CTesK (генератор, оракул, медиатор). Далее в цикле осуществляются вызовы $applyAction, для приема очередного тестового воздействия, и $checkAction, для передачи реакции на него.
Генератор через оракул передает медиатору очередное тестовое воздействие Action, который преобразует его в посылку сообщения ApplyAction VPI-модулю и переходит в состояние ожидания реакции на него WaitForCheck.
VPI-модуль при вызове $applyAction переходит в состояние ожидания очередного тестового воздействия WaitForAction и выходит из него при получении сообщения ApplyAction от медиатора тестовой системы CTesK. После этого он вызовом SetSignals изменяет нужным образом входные сигналы экземпляра тестируемой Verilog-модели и передает управление Verilog-окружению, возвращая статус OK.
При вызове $checkAction VPI-модуль, используя GetSignals, получает значения выходных сигналов и синхронизирует состояния экземпляра тестируемой Verilog-модели и спецификации тестовой системы CTesK. После этого он посылает сообщение ApplyCheck медиатору.
При приеме сообщения ApplyCheck медиатор выходит из состояния WaitForCheck и передает управление оракулу, который проверяет правильность реакции экземпляра тестируемой Verilog-модели на тестовое воздействие.
Цикл завершается при получении VPI-модулем в состоянии ожидания тестового воздействия WaitForAction сообщения Finish о завершении теста от тестовой системы CTesK.
Verilog-модель Verilog-о кружение
В работе была рассмотрена новая и, на наш взгляд, достаточно перспективная область применения технологии UniTesK - функциональное тестирование моделей аппаратного обеспечения. Главным образом, в статье описывались подходы к организации взаимодействия между тестовой системой CTesK и симуляторами моделей на языках Verilog HDL и SystemC. Для каждого из указанных классов моделей был предложен способ расширения базовой архитектуры тестовой системы, показано, что разработку некоторых дополнительных компонентов удается полностью или частично автоматизировать. На настоящий момент опыт применения технологии UniTesK и инструмента CTesK для тестирования моделей аппаратного обеспечения ограничивается небольшими примерами. Многие сложные вопросы такие, как декомпозиция спецификаций для упрощения описания сложных систем, тестирование систем с таймерами, а также тестирование систем со смешанными аппаратными и программными частями остались в работе нерассмотренными. То же относится к вопросам о возможности более тесной интеграция технологии UniTesK и инструмента CTesK с конкретными симуляторами и библиотеками. Данные вопросы являются темами будущих исследований.
Два потока управления, работающих строго поочередно.
Пример: тестовая конфигурация такого рода была построена для тестирования Verilog-моделей [].
В данном случае, как и в случае 3, целевая система обладает собственным активным потоком управления, на который можно влиять извне; отличается только реализация теста. При этом и целевая, и тестовая система ведут себя каждая как единственный активный поток, что позволяет запускать целевую систему в обычном для нее режиме, пользуясь при этом классической для UniTesK архитектурой тестового сценария, рассчитанной на единственный поток с немедленными реакциями. Выполнение в каждый момент времени в точности одного из этих потоков достигается средствами межпоточной синхронизации. Такая реализация удобна тем, что оба потока управления (и целевой системы, и теста) обладают собственными стеками.
Модель целевой системы в данном случае аналогична используемой в случае 1, различие только в реализации тестовой среды. Схема взаимодействия компонентов при этом выглядит следующим образом: целевая система инициализируется и вызывает встроенный в нее медиаторный код, который запускает в отдельном потоке тестовый сценарий UniTesK; тестовый сценарий инициализируется и переходит в режим ожидания сигнала; целевая система вызывает медиаторный код, который посылает потоку тестового сценария сигнал, описывающий текущее состояние целевой системы, и переходит в режим ожидания сигнала; тестовый сценарий получает сигнал от медиатора и анализирует его корректность в соответствии со спецификацией; тестовый сценарий выбирает очередное тестовое воздействие по правилам, описанным для случая 1; если такое воздействие не найдено, то он завершает работу: иначе сценарий передает медиатору сигнал, описывающий воздействие, и переходит в режим ожидания. получив сигнал, медиатор выполняет описанное в нем тестовое воздействие и получает ответную реакцию целевой системы; медиатор посылает тестовому сценарию сигнал, описывающий реакцию целевой системы и ее состояние, и переходит в режим ожидания; переходим к шагу 4.
Более подробно об архитектуре тестовой системы, применяемой в рассматриваемой конфигурации, можно прочитать в [].
Классификация тестируемых систем в соответствии с конфигурацией потоков управления
В технологии UniTesK целевая система рассматривается как "черный ящик". На входы ей подаются стимулы, а на выходах наблюдаются реакции. Для целей тестирования "черного ящика" важны только возможные соотношения между подаваемыми стимулами и получаемыми реакциями, и неважно, что именно происходит внутри целевой системы. Именно на основе этого принципа определяются границы целевой системы, и строится предлагаемая классификация.
Например, пусть имеются три различных системы. Система А обладает одним собственным потоком управления и может в ответ на полученный стимул начать некую собственную активность ограниченной продолжительности; в ходе этой активности она может как принимать новые стимулы, так и выдавать реакции на старые. Система Б аналогична по внешнему поведению, но внутри нее имеется несколько собственных потоков управления. Система В никакой собственной активности не ведет, но также может сразу выдать в ответ на стимул несколько реакций, причем между системой В и тестовой системой находится сеть, которая вносит недетерминированные задержки в передачу как стимулов, так и реакций (случай тестирования через сложную среду). С точки зрения тестирования все эти три системы эквивалентны: про них известно только то, что после подачи стимула в течение некоторого времени возможен как приём реакций от них, так и подача новых стимулов. Поэтому с точки зрения тестирования все они относятся к классу систем с отложенными реакциями []. В случае систем А и Б это определяется наличием их собственных активных потоков, а в случае системы В - функционированием сетевого оборудования и системного ПО. В последнем случае у теста может отсутствовать возможность определить, по чьей вине реакция была искажена, потеряна или задержана - системы В или промежуточной сети. Поэтому разумно включить в рамки целевой системы также и сеть и тестировать именно совместное поведение системы В и сети - вместе они составляют некую систему с отложенными реакциями В', правильность работы которой и проверяется.
Если же среда допускает возможность сделать такую проверку (например, взаимодействие тестовой и целевой систем происходит по протоколу TCP, который маскирует все эти искажения), то система В может быть отнесена к более простому классу, позволяющему применять более простые модели и инструменты тестирования.
В ходе исследований выделены следующие различающиеся с точки зрения тестирования "черного ящика" конфигурации потоков управления.
Целевая система может быть представлена в виде API, предполагающего однопоточное выполнение и не обладающего собственным потоком управления. Существует только один активный поток, принадлежащий тестовой системе. Целевая система не выполняет никаких действий и не меняет свое состояние вне вызовов из тестовой системы. Аналогично п.1, но целевой API предполагает работу в многопоточной среде. Собственным потоком управления целевая система не обладает. Необходимо протестировать корректность работы при параллельном вызове методов целевого интерфейса. Существует несколько активных потоков, все они принадлежат тестовой системе. Целевая система не выполняет никаких действий и не меняет свое состояние вне вызовов из тестовой системы. Существует единственный поток управления, не контролируемый тестом. Активный поток иногда передает управление тесту, но тот обязан быстро вернуть управление, и при этом он не может выполнить свою работу за доступное ему за один раз время. Реакции на все или некоторые стимулы поступают только при следующих вызовах теста. Никакие внешние сообщения в целевую систему не поступают. Аналогично п. 3, но возможны внешние воздействия на целевую систему или ее собственная длительная активность. Существуют два потока управления, один из которых принадлежит целевой системе, другой - тесту; при этом в любой момент времени активен ровно один из них. Тест - активный поток, целевая система - один или несколько полуактивных потоков: при получении стимула она может выдавать на него реакции в течение ограниченного времени, после чего стабилизируется и уже не может менять состояние или выдавать реакции до получения следующего стимула.Во время активности целевая система продолжает принимать новые стимулы, причем реакции на них могут выдаваться в произвольном порядке, и получение новых стимулов может влиять на реакции, выдаваемые системой в ответ на старый стимул. Кроме теста, существуют и другие активные потоки. Целевая система может менять состояние и выдавать сколь угодно много реакций в течение неограниченного времени в ответ на полученный стимул и даже при отсутствии стимулов.
Других конфигураций активных потоков, существенно отличающихся с точки зрения тестирования, обнаружить не удалось. Прежде чем приступить к подробному рассмотрению перечисленных видов конфигураций активных потоков, введем несколько определений.
Литература
| 1. | - сайт, посвященный технологии тестирования UniTesK и поддерживающим ее инструментам. |
| 2. | В. В. Кулямин, А. К. Петренко, А. С. Косачев, И. Б. Бурдонов. Подход UniTesK к разработке тестов. Программирование, 29(6), стр. 25-43, 2003. |
| 3. | В. П. Иванников, А. С. Камкин, В. В. Кулямин, А. К. Петренко. Применение технологии UniTesK для функционального тестирования моделей аппаратного обеспечения. Препринт 8. Институт системного программирования РАН. Москва, 2005. |
| 4. | I. Bourdonov, A. Kossatchev, A. Petrenko, and D. Galter. KVEST: Automated Generation of Test Suites from Formal Specifications. FM'99: Formal Methods. LNCS 1708, pp. 608-621, Springer-Verlag, 1999. |
| 5. | V. Kuliamin, A. Petrenko, I. Bourdonov, and A. Kossatchev. UniTesK Test Suite Architecture. Proc. of FME 2002, LNCS 2391, pp. 77-88, Springer-Verlag, 2002. |
| 6. | V. Kuliamin, A. Petrenko, N. Pakoulin, I. Bourdonov, and A. Kossatchev. Integration of Functional and Timed Testing of Real-time and Concurrent Systems. Proc. of PSI 2003, LNCS 2890, pp. 450-461, Springer-Verlag, 2003. |
| 7. | И. Б. Бурдонов, А. С. Косачев, В. В. Кулямин. Неизбыточные алгоритмы обхода графов: недетерминированный случай. Программирование, 30(1), стр. 2-17, 2004. |
Определение
Реакция на некоторый стимул называется отложенной, если на временной линии используемой модели целевой системы событие применения данного стимула и событие получения данной реакции на него происходят в существенно различные моменты времени. Моменты времени считаются существенно различными, если в промежутке между ними возможны другие события, существенные с точки зрения используемой модели (в том числе, применение других стимулов и получение других реакций).
Как уже было показано выше, любой блокирующий вызов (локальный или удаленный) без пост-эффектов не является стимулом с отложенной реакцией.
Целевая система называется системой с отложенными реакциями, если на некоторые стимулы она производит отложенные реакции, причем в любой момент можно определить промежуток времени, за которое при отсутствии новых тестовых стимулов система гарантированно придет в стационарное состояние. Состояние целевой системы называется стационарным, если при дальнейшем отсутствии стимулов она гарантированно сколь угодно долго не будет менять свое состояние и выдавать новых реакций. Поскольку внутреннее состояние целевой системы нам в общем случае неизвестно, имеется в виду стационарность модельного состояния системы.
Целевая система называется системой с немедленными реакциями, если с точки зрения используемой модели она производит только немедленные реакции на все стимулы.
Реакция на некоторый стимул называется немедленной, если с точки зрения тестовой системы она поступает непосредственно после подачи стимула. Это означает, что между моментом подачи стимула и моментом получения реакции на него на временной линии модели целевой системы не могут происходить никакие события, существенные с точки зрения модели.
Если несколько реакций на один стимул приходят непосредственно после подачи этого стимула, и с точки зрения модели несущественно, какой из них пришел раньше, то они объединяются в одну сложную немедленную реакцию. Например, возврат из метода нескольких выходных параметров можно рассматривать как одну немедленную реакцию. Простой возврат управления также считается немедленной реакцией.
Вообще, к данному классу можно отнести гораздо более широкий спектр реакций, чем может показаться на первый взгляд. Например, вызываемый метод может реально выполняться где угодно (даже на группе удаленных машин) и работать сколь угодно долго, но если вызывающий его поток блокируется на все это время, то возврат управления и выходных значений в вызывающем потоке считается реакцией, происходящей непосредственно после подачи стимула вызова метода. Кроме того, реакция на стимул может приходить не в тот поток управления, из которого был подан этот стимул, но если в используемой модели реакция и стимул проецируются на единую временную линию, и на этой линии между ними не может произойти никаких других событий, то такая реакция также считается немедленной. Иногда реакцию можно считать немедленной и в тех случаях, когда целевая система блокируется на время обработки стимула (даже если при этом не блокируется вызывающий ее поток) и задерживает новые стимулы до полной обработки текущего стимула и выдачи всех реакций на него. В этом случае события в модели можно переупорядочить таким образом, чтобы стимулы следовали в порядке поступления их в целевую систему, а все реакции на каждый стимул следовали непосредственно после него.
Пассивные параллельные системы
Примеры: Реализация любой подсистемы стандартной библиотеки libC, заявленная как устойчивая к многопоточности ("thread-safe"). Библиотека управления многопоточностью libThreads.
В технологии UniTesK задача тестирования систем данного класса решается с помощью специальных сценариев, определяющих наборы параллельных воздействий [] Кроме проверок поведения целевой системы, выполняемых после применения каждого тестового стимула, проверяется следующий постулат сериализации: "Результат любого параллельного применения стимулов к целевой системе аналогичен некоторому последовательному их применению". Именно необходимость проверки данного постулата не позволяет отнести такие системы к классу 1. Для проверки постулата модель целевой системы включает в себя сериализацию событий (примененных стимулов и полученных реакций), которая строится следующим образом. Все события (применение стимулов и получение связанных с ними реакций), произошедшие в ходе выполнения тестового сценария, протоколируются. На множестве событий строится частичный порядок: линейный порядок определен для всех событий, произошедших в пределах одного потока управления; на основании дополнительных знаний о целевой и тестовой системах может быть определен частичный порядок событий, произошедших в разных потоках. Строятся все возможные линейные порядки событий, удовлетворяющие построенному частичному порядку. Работа целевой системы признается корректной, если найден хотя бы один такой линейный порядок событий, который удовлетворяет спецификации целевой системы.
Замечание: В процессе выполнения теста существует несколько потоков управления, принадлежащих тестовой системе, и, соответственно, в используемой в это время модели целевой системы может иметься несколько временных линий. Однако после построения сериализации все события выстраиваются на единой временной линии, так что к моделируемой системе становится полностью применимым данное выше определение системы с непосредственными реакциями. Именно на этом основании системы данного класса отнесены к классу систем с немедленными реакциями.
Пассивные последовательные системы
Примеры: большинство подсистем стандартной библиотеки libC.
Целевая система считается относящейся к данному классу, если она удовлетворяет следующим требованиям: в ответ на каждый подаваемый стимул она выдает пустую или немедленную реакцию; вне вызовов из тестовой системы целевая система не выполняет никаких действий и не меняет свое состояние; поставленная задача тестирования не включает проверку работы целевой системы в многопоточном окружении, или такая работа невозможна.
Исходно технология UniTesK разрабатывалась для тестирования именно данного класса систем. Рассмотрим вкратце способ тестирования, применяемый в данном случае.
При создании тестового сценария используется абстракция обобщенных состояний, где каждое обобщенное состояние соответствует некоторому классу эквивалентности реализационных состояний целевой системы. Обычно в модели обобщенных состояний используется значительно более высокий уровень абстракции, чем в модели, используемой для проверки корректности работы целевой системы. В любой момент времени целевая система находится в некотором однозначно определенном обобщенном состоянии и может изменить его только в результате применения тестового стимула. После применения некоторого стимула в некотором обобщенном состоянии целевой системы анализируется полученная реакция и вычисляется новое обобщенное состояние.
Задача тестового сценария состоит в обходе ребер ориентированного графа, вершины которого соответствуют обобщенным состояниям целевой системы, а ребра - применяемым к ней обобщенным стимулам, где каждый обобщенный стимул соответствует некоторому классу эквивалентности возможных стимулов, применяемых к целевой системе. Граф строится интерактивно, по мере выполнения теста, на основе правил вычисления текущего обобщенного состояния целевой системы и правил перебора стимулов, применяемых в зависимости от обобщенного состояния.
Модель обобщенного состояния и обобщенных стимулов строится так, чтобы при повторном применении обобщенного стимула в некотором обобщенном состоянии целевая система всегда переводилась в то же самое обобщенное состояние, в которое она ранее переходила при применениях этого стимула в том же состоянии. Также накладывается дополнительное требование сильной связности графа обобщенных состояний. Практика тестирования реальных систем показывает, что для систем, удовлетворяющих минимальным требованиям к детерминизму поведения, построение модели, удовлетворяющей изложенным требованиям, возможно.
Способы тестирования, применяемые в технологии UniTesK для данной конфигурации активных потоков, более подробно описаны в [, ]. Случай недетерминированного поведения целевой системы частично рассматривается ниже, но в целом выходит за рамки данной работы []
Полуконтролируемое тестирование
Пример: Аналогично случаю 3, но целевая система регулярно выполняет по расписанию какую-то работу, влияющую на ее состояние. В качестве такого дополнительного источника воздействий на целевую систему при этом выступает таймер, неподконтрольный тестовой среде. Если в данном примере тестовая среда имеет возможность изолировать таймер и создавать стимулы от него целевой системе тогда и только тогда, когда это необходимо для целей тестирования, то такую целевую систему следует отнести к классу 3.
Из-за наличия неконтролируемых источников воздействий на целевую систему данный случай не может быть сведен к случаям 3, а тем более случаям 1 и 2, поскольку в рассмотренных выше случаях предполагается полная подконтрольность всех стимулов, получаемых целевой системой.
При этом для целей тестирования неважно, сколько активных потоков реально существует и откуда поступают воздействия на целевую систему: от внешних активных потоков или от других объектов, существующих на аналогичных условиях под управлением единого потока управления. В любом случае, когда возможна неконтролируемая тестом активность целевой системы, сложность модели целевой системы времени тестирования будет аналогична сложности модели, используемой в случае 7, который обсуждается ниже.
С точки зрения особенностей реализации тестовой системы, она аналогична случаю 3.
Именно из доступных ограничений такого рода и нужно исходить при моделировании. Мы можем предложить только некоторые общие рекомендации по уменьшению степени недетерминизма модели, позволяющие свести систему такого рода к одному из более простых случаев.
По возможности изолировать целевую систему, помещая ее в "песочницу" ("sandbox"), в которой все связи с внешним миром заменены связями с соответствующими заглушками - компонентами тестовой системы. Это классическая техника, однако в ряде случаев она не может быть применена, например, если целевая система - большой монолитный компонент, обладающий собственными активными потоками управления, и отсутствует доступ к исходному коду. Моделировать только ту часть целевой системы, поведение которой не зависит от неконтролируемых активных потоков. Корректность реакций целевой системы на воздействия, неподконтрольные тесту (и, возможно, непосредственно им не наблюдаемые), при этом не проверяется. Конструировать модель целевой системы так, чтобы она отражала только те свойства целевой системы, которыми она должна обладать при любых сценариях ее работы, независимо от возможных последствий взаимодействия с неконтролируемыми потоками управления. При этом моделируемые аспекты являются инвариантами модели относительно неподконтрольных воздействий. Технология UniTesK изначально приспособлена для такого способа решения проблемы, потому что основана на вычислении предикатов над поведением целевой системы: спецификация описывает не точное поведение системы, а только условия, которым это поведение должно удовлетворять. Такой подход позволяет описывать и тестировать системы с достаточно высоким уровнем недетерминизма [, , ]
С помощью приведенных методов в большинстве случаев задача тестирования может быть сведена к задаче тестирования системы более простого класса: 1, 2 или 6. Однако общей методики решения этой задачи не существует, как не существует и общего для любых систем способа автоматического построения их моделей для целей тестирования.Задача построения моделей целевой системы и преобразования моделей в более "удобный" для тестирования вид требует творческого подхода, и не существует единого метода, решающего эти задачи для любых целевых систем
Система с отложенными реакциями
Пример: FTP-сервер при одновременной работе нескольких клиентов. После получения запроса на сканирование каталога в течение какого-то времени выполняется сканирование, и клиент получает сетевые пакеты с результатами запроса. При этом параллельно другие клиенты могут модифицировать содержимое того же каталога. Поскольку стандарт не гарантирует однозначность результата сканирования при одновременных модификациях сканируемого каталога, результаты запроса могут различаться в зависимости от действий других клиентов, выполняемых в процессе обработки запроса.
В данном случае для задачи тестирования неважно, сколько реально существует активных потоков. В любом случае, в течение некоторого времени после применения тестового стимула возможны как получение от целевой системы реакций на этот стимул, так и подача новых стимулов. Именно эти критерии заставляют относить целевую систему к данному классу систем.
Поскольку в случаях 1, 2 и 5 предполагаются только немедленные реакции, к ним не могут быть сведены системы данного класса. Для систем с отложенными реакциями в технологии UniTesK разработана специальная архитектура теста []:
В тестовом сценарии имеется один основной активный поток. Этот поток регулярно опрашивает входные каналы для анализа реакций, полученных от целевой системы. При необходимости создаются вспомогательные потоки управления, в которых выполняются так называемые "кэтчеры" (catcher). Задача кэтчера - регистрация реакций, полученных от целевой системы, и передача их во входные каналы основного потока управления тестового сценария. Кэтчеры могут также встраиваться в существующие потоки управления целевой системы.
Модель целевой системы времени тестирования включает в себя информацию о тех ранее примененных стимулах, в ответ на которые еще возможно получение реакций (стационарным считается такое модельное состояние целевой системы, в котором это множество пусто). При получении реакции проверяется, допускает ли спецификация получение реакции такого рода в данный момент.
Получение неожиданной реакции ( в том числе получение любой реакции в стационарном модельном состоянии системы), а также неполучение ожидаемой реакции в течение допустимого времени рассматриваются как ошибки. Тестовый сценарий перебирает серии тестовых стимулов и применяет их к целевой системе. После подачи такой серии сценарий ждет перехода целевой системы в стационарное состояние, анализируя при этом все полученные от нее реакции. Задача тестирования определяется как обход ребер ориентированного графа, вершины которого соответствуют обобщенным состояниям целевой системы, а ребра - применяемым к ней обобщенным стимулам, где каждый обобщенный стимул соответствует некоторому классу эквивалентности серий применяемых к целевой системе стимулов. Граф состояний строится интерактивно, по мере работы теста. Все события протоколируются, а после завершения теста строится их сериализация. Правила построения частичного порядка событий описываются спецификацией целевой системы и в общем случае могут быть более сложными, чем в случае 2. Работа целевой системы признается корректной, если найдена хотя бы одна сериализация событий, удовлетворяющая спецификации.
Следствия из определений:
В ответ на получение стимула целевая система может выдать не более одной немедленной реакции, а количество отложенных реакций может при этом быть любым. Реакция является отложенной или немедленной не сама по себе, а с точки зрения модели, используемой для тестирования. Для одной и той же системы могут быть построены разные модели, и если в одной модели допускаются какие-либо события между подачей стимула и получением на него реакции, а в другой - нет, то в первой модели реакция будет отложенной, а во второй - немедленной. Соответственно, целевая система в целом может являться или не являться системой с отложенными реакциями в зависимости от используемой модели.
Разработчики спецификаций и тестов могут выбирать ту или иную модель в зависимости от свойств целевой системы и поставленной задачи тестирования. Модели с отложенными реакциями включают в себя всю выразительную мощь моделей без отложенных реакций, но более сложны. Рекомендуется всегда выбирать для тестирования из множества моделей, отражающих все проверяемые свойства системы, модель наименьшей возможной сложности.
Тестирование с отложенными реакциями
Пример: Object Request Broker (ORB) RACE, разработанный для однопроцессорных встроенных систем. И тест, и целевая система - объекты, существующие под управлением этого ORB. Стимулы и реакции - сообщения ORB, причем сообщения передаются между объектами только в промежутке между получением ими управления.
В данном случае для задачи тестирования неважно, сколько реально существует активных потоков (см. ниже обсуждение случая 6). В любом случае тест не обладает собственным потоком управления и может в течение некоторого времени после применения тестового стимула получать реакции на него от целевой системы и выдавать новые стимулы. Именно эти критерии заставляют относить целевую систему к данному классу систем.
Если активный поток не является единственным, то требуется построение модели, аналогичной той, которая используется в случае 6 (см. ниже). Если такой поток - единственный, то данный случай проще случая 6, поскольку не требуется специальное построение сериализации событий. Однако случай 3 не может быть сведен к случаям 1 или 2, потому что возможны отложенные реакции целевой системы.
Задача построения модели для систем данного класса решается аналогично случаю 6. Однако для системы с конфигурацией такого рода потребовалась особая реализация обходчика: обычный тест UniTesK выполняется в собственном потоке управления с собственным стеком, в котором хранятся вызовы методов и их локальные переменные; в данном же случае тест не обладает собственным стеком вызовов и не имеет возможности выполнять какие-либо длительные действия.
Упрощенный алгоритм работы тестовой системы в случае 3 выглядит следующим образом:
| 1. | обеспечить регулярное получение управления в активном потоке (например, подписаться на получение сигналов от таймера); | |
| 2. | при очередном получении управления: | |
| 2.1 | проверить реакции от целевой системы, полученные за время ее самостоятельной работы, и состояние, в котором она находится; при необходимости сообщить об ошибках; | |
| 2.2 | если тест находится в состоянии ожидания реакций от целевой системы: | |
| 2.2.1 | если получены не все ожидаемые реакции и время ожидания еще не вышло, вернуть управление; | |
| 2.2.2 | если все ожидаемые реакции получены, перейти к шагу 2.4; | |
| 2.2.3 | иначе сообщить об ошибке; | |
| 2.3 | если тест находится в состоянии ожидания некоторого состояния целевой системы: | |
| 2.3.1 | если не все ожидаемые реакции получены и время ожидания еще не вышло, вернуть управление; | |
| 2.3.2 | если нужное состояние достигнуто, перейти к шагу 2.4; | |
| 2.3.3 | иначе сообщить об ошибке; | |
| 2.4 | вычислить очередной стимул, который следует применить к целевой системе в текущем состоянии; | |
| 2.5 | если такой стимул найден, применить его, проанализировать немедленные реакции, при необходимости перейти в состояние ожидания реакций и вернуть управление; | |
| 2.6 | если существует состояние целевой системы N, которое уже существовало в процессе выполнения теста, но в котором были применены не все возможные стимулы, то попытаться перейти в него; найти в уже обойденной части графа состояний путь из текущего состояния в искомое, вычислить и подать нужные стимулы, перейти в режим ожидания состояния N и возвратить управление; | |
| 2.7 | если такое состояние не найдено, значит во всех обнаруженных состояниях применены все возможные стимулы; тест завершает работу. |
которое требуется для удовлетворения потребностей
В связи с возрастанием размера и сложности программного обеспечения (ПО), которое требуется для удовлетворения потребностей пользователей и поддержки стабильного развития современного общества, задача автоматизации тестирования становится одной из ключевых в разработке качественного ПО. Одним из перспективных подходов к решению этой задачи является UniTesK - технология автоматизированного функционального тестирования на основе формальных методов, разработанная в Институте системного программирования РАН [, , , ]. Данная технология позволяет автоматизировать разработку и выполнение тестов, которые с высокой степенью надежности проверяют корректность поведения тестируемой системы. В дальнейшем в статье вместо термина "тестируемая система" используются термины "целевая система" или просто "система" - во избежание путаницы с похожим термином "тестовая система", который также будет использоваться. Большинство реальных систем обладает некоторым внутренним состоянием, которое может влиять на выдаваемые системой реакции и изменяться как при получении воздействий извне, так и в процессе собственной работы системы. Поскольку внутреннее состояние системы в общем случае неизвестно, и, кроме того, оно может содержать много несущественных с точки зрения поставленной задачи тестирования деталей, в технологии UniTesK строится модель целевой системы времени тестирования (в дальнейшем - просто "модель"), отражающая ее проверяемые свойства в удобном для тестирования компактном виде и скрывающая несущественные реализационно-зависимые детали. Повышение уровня абстракции позволяет использовать один и тот же комплект тестов для тестирования различных реализаций одного набора функций. Компонент, называемый медиатором, отображает реализацию и модель друг в друга: реализационное состояние целевой системы - в модельное состояние, модельные тестовые стимулы - в реализационно-зависимые воздействия на целевую систему, а реализационно-зависимые реакции целевой системы - в модельные реакции.
В дальнейшем везде, где не оговорено специально, речь будет идти именно о модельных состояниях, стимулах и реакциях. Тестовый сценарий UniTesK перебирает состояния целевой системы и в каждом из них перебирает подаваемые ей на вход тестовые стимулы вплоть до достижения заданной степени тестового покрытия. Специальный компонент, получаемый на основе спецификаций и называемый оракулом, автоматически анализирует выходные реакции и выдает вердикт об их корректности. Корректность поведения целевой системы определяется его соответствием спецификации. Также автоматически оценивается степень достигнутого тестового покрытия [, ]. В технологии UniTesK последовательность тестовых воздействий строится интерактивно, по мере выполнения теста. Для этого используются специальные компоненты, называемые обходчиками. Задача обходчика - обход графа состояний системы, причем этот граф не задается заранее, а строится прямо в процессе взаимодействия тестовой и целевой систем. Очередное тестовое воздействие определяется на основе предыдущей истории взаимодействия. Такой подход обеспечивает простоту написания тестовых сценариев и гибкость тестирования. Интерактивная природа тестирования порождает ряд проблем, связанных с взаимной активностью тестовой и целевой систем: целевая система может иметь несколько взаимодействующих между собой потоков управления, взаимодействовать непредсказуемым образом с внешними системами, неподконтрольными тестовой среде, выдавать реакции на определенные воздействия по прошествии значительного времени и выполнять какую-то собственную деятельность. Все это может влиять на состояние целевой системы и, в результате, на наблюдаемые тестовой системой реакции. Кроме того, даже при полной пассивности целевой системы может возникнуть необходимость тестирования ее работы в окружении множества параллельно работающих активных потоков, создающих запросы к ней. Во всех случаях тест должен определять корректность поведения целевой системы и добиваться заданной степени тестового покрытия. Опыт использования технологии UniTesK для тестирования реальных систем показывает, что она подходит для тестирования практически любой конфигурации активных потоков теста, целевой системы и внешних систем, однако различные конфигурации требуют построения различных моделей целевой системы и использования различных инженерных решений в построении тестовой системы.Данная работа посвящена особенностям тестирования различных конфигураций активных потоков с помощью технологии тестирования UniTesK. Целями работы являются исследование возможности использования технологии тестирования UniTesK для построения тестов с различной конфигурацией потоков управления, принадлежащих тестовой системе и существующих независимо от нее;самостоятельных. систематизация опыта тестирования различных конфигураций активных потоков; разработка подходы для случаев, на которые технология UniTesK в существующем на данный момент виде не рассчитана.
В данной статье проведена классификация
В данной статье проведена классификация тестируемых систем в соответствии с видом конфигурации активных потоков и рассмотрены особенности тестирования систем из каждого класса с помощью технологии UniTesK. Рассмотрены способы применения технологии UniTesK для тестирования без собственных активных потоков теста, которые ранее не рассматривались. Приведены некоторые способы уменьшения при моделировании недетерминизма поведения, которые позволяют привести тестируемую систему к виду, допускающему тестирование с помощью UniTesK. К сожалению, не существует единого способа моделирования, пригодного для тестирования систем со сколь угодно высокой степенью недетерминизма поведения, однако постоянно ведется работа по расширению класса систем, допускающих тестирование с помощью технологии UniTesK.
Генерируемый SeC-код
В первую очередь необходимо чётко определить, как должен выглядеть генерируемый код, что именно и как именно он будет проверять. За основу, разумеется, были взяты созданные к этому времени наработки, написанные вручную. Весь однотипный код удобно заменить набором макросов (они поддерживаются в языке SeC, т. к. он включает в себя все возможности языка C). Это сделало бы исходный текст более наглядным и более простым для написания и отладки.
В стандарте LSB присутствуют несколько разных типов требований на поведение функций при возникновении ошибочной ситуации. Возможные варианты поведения функции в случае ошибки могут быть описаны следующим образом: SHALL: в стандарте присутствует фраза «The function shall fail if …», т. е. стандарт требует, чтобы функция всегда обнаруживала описанную ошибочную ситуацию и возвращала в этом случае определённый код ошибки. MAY: в стандарте присутствует фраза «The function may fail if …», т. е. стандарт не требует непременного обнаружения данной ошибочной ситуации, но в случае, если функция всё же реагирует на данную ошибку, её поведение должно быть таким, как описано в стандарте. NEVER: в стандарте присутствует фраза «The function shall not return an error code …», т. е. данный код ошибки не может быть возвращён ни при каких условиях.
Эти три типа требований и были взяты за основу.
Проверка кодов ошибок должна производиться до начала проверки остальных требований (за исключением, быть может, самых базовых аспектов, обеспечивающих непосредственное функционирование самой тестовой системы - таких как проверки на NULL). Это связано с тем, что если произошла ошибка, то функция не выполнила требуемое от неё действие, и, следовательно, проверки функциональных требований сообщат, что функция работает некорректно, т. е. не удовлетворяет стандарту. Однако ошибка могла быть вызвана тестовым сценарием намеренно (например, специально для того, чтобы проверить, как поведёт себя функция в этом случае), и тогда сообщение о некорректности поведения функции окажется ложной тревогой.
Именно поэтому в первую очередь должен отработать блок проверки ошибочных ситуаций, и только если ошибка не была возвращена (и не ожидалась!), управление передаётся дальше, на код проверки основных требований. Для удобства проверка кодов ошибок оформлена в виде блока, ограниченного операторными скобками ERROR_BEGIN и ERROR_END, которые являются макросами. ERROR_BEGIN при этом содержит параметры, глобальные для всего блока (например, в какой переменной хранится собственно код ошибки). Внутри блока располагаются индивидуальные проверки для каждого пункта, упомянутого в стандарте, которые также являются вызовами макросов с определённым набором параметров. Упомянутым выше трём основным типам требований соответствуют макросы ERROR_SHALL, ERROR_MAY и ERROR_NEVER. Помимо них, есть ещё некоторые дополнительные макросы, но о них мы расскажем ниже. Приведём небольшой пример, демонстрирующий, как выглядит блок проверки кодов ошибок в одной из подсистем: Текст стандарта: The pthread_setspecific() function shall fail if:
[ENOMEM] Insufficient memory exists to associate the non-NULL value with the key.
The pthread_setspecific() function may fail if:
[EINVAL] The key value is invalid.
These functions shall not return an error code of [EINTR].
Текст спецификации: ERROR_BEGIN(POSIX_PTHREAD_SETSPECIFIC, "pthread_setspecific.04.02", pthread_setspecific_spec != 0, pthread_setspecific_spec) /* * The pthread_setspecific() function shall fail if: * [ENOMEM] * Insufficient memory exists to associate the non-NULL value with * the key. */ ERROR_SHALL(POSIX_PTHREAD_SETSPECIFIC, ENOMEM, "!pthread_setspecific.05.01", /* условие */)
/* * The pthread_setspecific() function may fail if: * [EINVAL] * The key value is invalid. */ ERROR_MAY(POSIX_PTHREAD_SETSPECIFIC, EINVAL, "pthread_setspecific.06.01", !containsKey_Map(thread->key_specific, key))
/* * These functions shall not return an error code of [EINTR]. */ ERROR_NEVER(POSIX_PTHREAD_SETSPECIFIC, EINTR, "pthread_setspecific.07")
ERROR_END()
Параметры макросов имеют следующий смысл: ERROR_BEGIN(ERR_FUNC, REQID, HAS_ERROR, ERROR_VAL):
ERR_FUNC - идентификатор функции, используемый в качестве префикса для конфигурационных констант.
Например, с префикса POSIX_PTHREAD_SETSPECIFIC начинаются соответствующие конфигурационные константы, такие как:
POSIX_PTHREAD_SETSPECIFIC_HAS_EXTRA_ERROR_CODES POSIX_PTHREAD_SETSPECIFIC_FAILS_WITH_EINVAL и др.
REQID - идентификатор проверяемого требования (строковая константа). HAS_ERROR - предикат, определяющий условие возникновения ошибки (булевское выражение). ERROR_VAL - код ошибки (обычно это переменная errno или возвращаемое значение функции).
ERROR_MAY(ERR_FUNC, ERRNAME, REQID, ERROR_PREDICATE), ERROR_SHALL(ERR_FUNC, ERRNAME, REQID, ERROR_PREDICATE), ERROR_NEVER(ERR_FUNC, ERRNAME, REQID):
ERR_FUNC - то же, что и выше. ERRNAME - имя константы, соответствующей ожидаемому коду ошибки. Например, ENOMEM, EINVAL. REQID - идентификатор проверяемого требования. ERROR_PREDICATE - предикат, определяющий условие возникновения ошибки.
ERROR_END: параметров не требует.
Конфигурационные константы.
Стандарт LSB не всегда достаточно чётко определяет ситуации ошибочного завершения функции. В нем допускается, что функции могут возвращать коды ошибок, не описанные в стандарте, а также возвращать описанные коды ошибок в каких-то иных, определяемых реализацией случаях (см. [LSB, System Interfaces, Chapter 2, 2.3 Error Numbers]). На практике же такие случаи достаточно редки. К тому же вполне возможна ситуация, когда ошибочное завершение функции с кодом, не указанным в стандарте, является не предусмотренным разработчиком случаем, а ошибкой реализации. Поэтому была добавлена возможность выбрать в каждом конкретном случае желаемый уровень тестирования - в соответствии со стандартом, или более жёстко. Соответствующие константы именуются XX_HAS_EXTRA_ERROR_CODES и XX_HAS_EXTRA_CONDITION_ON_YY, где XX - идентификатор функции, обычно передаваемый в макросы как параметр ERR_FUNC, а YY - имя константы ошибки.
Ситуация с требованиями типа MAY аналогична. В соответствии со стандартом, функция может не возвращать код ошибки, даже если условие выполняется. Однако в большинстве случаев разработчики «предпочитают ясность» и возвращают указанный код, хотя стандарт и не обязывает их к этому. Поэтому была введена специальная конфигурационная константа XX_FAILS_WITH_YY, определяющая, следует ли считать требование нарушенным, если функция не возвращает код ошибки при выполнении условия типа MAY. Как можно заметить, при включённой константе XX_FAILS_WITH_YY требования SHALL и MAY по сути перестают отличаться друг от друга. Фактически, сами макросы ERROR_SHALL и ERROR_MAY реализованы как один макрос ERROR_MAY_SHALL, принимающий на вход ещё один дополнительный аргумент с именем SHALL, который и определяет, должна ли функция возвращать код ошибки, если предикат ERROR_PREDICATE истинен. Соответственно, макрос ERROR_SHALL реализован как вызов ERROR_MAY_SHALL с параметром SHALL, равным true, а ERROR_MAY - как вызов ERROR_MAY_SHALL с параметром SHALL, зависящим от значения константы XX_FAILS_WITH_YY.
Литература
| 1.обратно | http://linuxtesting.ru/ |
| 2.обратно | CTesK 2.2 Community Edition: Руководство пользователя. |
| 3.обратно | CTesK 2.2 Community Edition: Описание языка SeC. |
Методика автоматизированной проверки
К. А. Власов, А. С. Смачёв, Труды Института системного программирования РАН
Оформление непроверяемых требований
В силу различных причин проверка некоторых требований может быть затруднена или даже невозможна. Для таких ситуаций были введены два дополнительных макроса.
ERROR_UNCHECKABLE. Этот макрос используется в том случае, когда проверка требования не может быть выполнена по каким-либо причинам. Сам макрос просто сигнализирует о том, что данный код ошибки не противоречит стандарту. TODO_ERR(errname). Этот макрос-заглушка используется вместо предиката, определяющего условия возникновения ошибки, в тех случаях, когда проверка в принципе возможна, но либо она чрезмерно сложна, либо её реализация по каким-то причинам на время отложена. Макрос TODO_ERR возвращает истину тогда и только тогда, когда возвращаемый код ошибки совпадает с проверяемым. Таким образом, вместо реальной проверки в данном случае мы имеем тавтологию. Этот макрос подставляется по умолчанию вместо конкретных условий в коде, который генерируется непосредственно из разметки. Это позволяет достаточно быстро и с минимальными усилиями создать компилирующийся и работающий проект для тестирования новой подсистемы.
Пересечение требований
Может оказаться, что один и тот же код ошибки встречается в нескольких требованиях. Хорошо, если эти требования лишь дополняют друг друга. Но может сложиться ситуация, когда эти требования противоречат друг другу, а именно, когда одно из них требует, чтобы функция вернула код ошибочного завершения, а другое - утверждает, что в этой ситуации данный код ошибки не может быть возвращён. Такая ситуация может и не встретиться в ходе выполнения тестов, но подобное противоречие условий в любом случае является ошибкой в стандарте.
Другая ситуация: под одно и то же условие попадают разные коды ошибок, при этом стандарт для обоих кодов требует обязательного возврата этого кода. В этом случае при выполнении условий появления ошибки тесты зафиксируют некорректность в работе тестируемой системы, независимо от того, какой из этих кодов ошибки был возвращён функцией, так как проверка другого кода зафиксирует некорректность поведения. В такой ситуации обычно из текста стандарта понятно, какой код ошибки должен возвращаться в каждом конкретном случае, и, следовательно, условия возникновения ошибок должны быть дополнены так, чтобы не выполняться одновременно ни в каких ситуациях. Если же из контекста неясно, какой код ошибки должен быть возвращён, налицо явное противоречие в стандарте.
Таким образом, пересечение требований является серьёзной проблемой, и разработчик тестов должен обращать на них особое внимание.
Постановка задачи
При написании тестов для пакета OLVER используется система CTesK []. Она включает в себя язык SeC [] - спецификационное расширение языка C, а также библиотеки для работы с различными типами данных, такими как массив, список, строка и т. д.
Добавление новых тестируемых функций в тестовый набор обычно выглядит следующим образом. Сначала программист читает текст стандарта и размечает его, выделяя атомарные требования при помощи конструкций языка HTML и присваивая им уникальные идентификаторы. Затем при открытии в браузере веб-страницы с текстом стандарта автоматически запускается скрипт, написанный на языке JavaScript, который анализирует список отмеченных требований, строит по нему шаблонный код на языке SeC и отображает его на странице. Теперь программисту достаточно просто скопировать этот код в SEC-файлы проекта, и большая часть рутинной работы оказывается выполненной. Дальнейшая работа - это, в основном, создание тестовых сценариев и написание непосредственно кода проверки для всех атомарных требований, т. е. творческая работа, которая практически не поддаётся автоматизации.
В процессе работы над тестовым набором выяснилось, что проверки кодов ошибок, возвращаемых различными тестируемыми функциями, имеют много общего, в результате чего существенная часть времени тратится на одну и ту же работу по организации взаимодействия проверок для разных кодов ошибок друг с другом и с проверками других требований. Поэтому было решено, насколько это возможно, попытаться автоматизировать и эту задачу.
Наиболее удобный путь для такого рода автоматизации - это модификация существующего скрипта, чтобы он генерировал шаблонный код ещё и для проверки ошибок. Тем самым будет сохранена общая методика работы по разметке стандарта.
Проверка
В макросе ERROR_BEGIN в первую очередь проверяется, что если функция завершилась с ошибкой, то код ошибки не равен EOK (коду, обозначающему отсутствие ошибки). Обычно признаком ошибки является сам факт отличия кода от EOK, и эта проверка превращается в тавтологию. Но бывают и другие случаи, когда, например, признаком ошибки является возвращаемое значение функции, равное -1, и тогда эта проверка необходима.
Проверка кодов ошибок не ограничивается случаем, когда функция завершилась с ошибкой. Условие типа SHALL должно обеспечивать также проверку в обратную сторону: если условия вызова функции ошибочны, то функция обязана вернуть ошибку, и если этого не произошло, поведение считается некорректным.
Заметим, что независимо от того, успешно ли отработала функция, необходимо проверять все требования к кодам возврата, поскольку выполнение одного требования ещё не означает, что другие требования не нарушены. Таким образом, решение о правильной работе функции должно приниматься только в макросе ERROR_END, не раньше. На первый взгляд, это соображение очевидно, но именно поэтому его так легко упустить из виду.
Для каждого требования имеется четыре базовых случая: Ошибка ожидалась и произошла. Ошибка не ожидалась, но произошла. Ошибка ожидалась, но не произошла. Ошибка не ожидалась, и её не было.
В каждом из этих случаев есть свои тонкости, которые легко упустить из виду. Возьмём, например, первый случай, когда ошибка ожидалась и произошла. Первым побуждением будет выдать вердикт, что проверка завершилась успешно, и выйти из блока проверки ошибок. Однако этого делать ни в коем случае нельзя, т. к. должны быть проверены абсолютно все требования - то самое «очевидное» соображение, высказанное выше! Ведь даже в случае возврата ожидаемого кода ошибки есть вероятность, что другое требование окажется нарушенным. То же самое относится к последнему случаю, когда ошибка не ожидалась и не произошла.
Случай второй, когда ошибка не ожидалась, но произошла. Если это требование типа NEVER, или если это MAY/SHALL, и соответствующая константа XX_HAS_EXTRA_CONDITION_ON_YY равна нулю, то можно констатировать неправильную работу функции.
При ненулевом значении этой константы поведение функции не противоречит стандарту. Случай третий, когда ошибка ожидалась, но не произошла. Если это условие типа SHALL или если это MAY, и соответствующая константа XX_FAILS_WITH_YY не равна нулю, то можно констатировать неправильную работу функции. Если же функция вернула другой код ошибки, то поведение также является некорректным. Однако в этом случае дополнительно стоит обратить внимание на причины возникновения этой проблемы. Не исключено, что возвращённый код взялся не «с потолка», а явился следствием того, что оказались выполнены условия возникновения и этой второй ошибки наряду с первой. Если оба требования являются требованиями типа SHALL (или MAY с ненулевой константой XX_FAILS_WITH_YY), то можно утверждать, что в стандарте имеет место противоречие: для одних и тех же условий требуется вернуть одновременно два различных кода. На таких ситуациях мы сейчас остановимся несколько подробнее.
Трёхзначная логика
Иногда случается, что мы не во всех ситуациях можем определить, выполняется данное условие или нет. В этом случае логика становится трёхзначной: «да» - «нет» - «не знаю». Конечно, можно было бы поместить проверку внутрь условного ветвления, в котором условие всегда было бы проверяемым, но это значительно усложнило бы читаемость и понятность кода. К тому же для человека такая трёхзначная логика в достаточной мере «естественна».
Поэтому к существующим макросам были добавлены ERROR_SHALL3 и ERROR_MAY3, в которых предикат может принимать одно из трёх значений: False_Bool3, True_Bool3, Unknown_Bool3.
Наиболее используемы эти макросы в случаях, когда значение проверяемого параметра подсистемы может быть неизвестно в силу закрытости тестовой модели. Пример: /* * [EINVAL] * Invalid speed argument. */ ERROR_MAY3(LSB_CFSETSPEED, EINVAL, "cfsetspeed.04.01", (isKnown_Speed(speed) ? False_Bool3 : not_Bool3(isValid_Speed(speed))) )
Другими частыми случаями употребления этих макросов являются проверки на корректность параметров или на наличие определённых ресурсов. Зачастую стандарт не указывает, как определить некорректность нужного значения, а проверить наличие ресурсов (например, оперативной памяти) не представляется возможным, так как почти никогда не известно точно, какое их количество будет «достаточным». С другой стороны, про отдельные значения может быть известно, что они заведомо корректные или заведомо некорректные. Пример: /* * The confstr() function shall fail if: * [EINVAL] * The value of the name argument is invalid. */ /* [LSB: 18.1.1. Special Requirements] * A value of -1 shall be an invalid "_CS_..." value for confstr(). */ ERROR_SHALL3(POSIX_CONFSTR, EINVAL, "confstr.12", ((name == -1) ? True_Bool3 : Unknown_Bool3) )
В подобных случаях макросы с трёхзначной логикой позволяют естественным образом формализовать условие с помощью одной проверки, что обеспечивает читабельность и наглядность программного кода.
В современном мире компьютеры играют
В современном мире компьютеры играют всё большую роль, а с ними - и программное обеспечение. В настоящее время наблюдается тенденция ко всё возрастающему усложнению и увеличению программных комплексов, состоящих из различных модулей и подсистем. Но чем больше программа, тем сложнее её отлаживать и проверять на соответствие спецификационным требованиям. Есть области, где ошибки совершенно недопустимы, например, медицина, атомная энергетика. Легко представить, что может натворить небольшая ошибка в программе, управляющей атомным реактором. Поэтому важность задачи верификации программного обеспечения трудно переоценить. Данное исследование было проведено в рамках проекта OLVER (Open Linux VERification) [], задачей которого была разработка тестового набора, позволяющего выполнять автоматическую проверку дистрибутивов операционной системы Linux на соответствие стандарту LSB (Linux Standard Base). Тестовый сценарий заключается в вызове всех функций из тестируемой подсистемы с заданным набором параметров и проверке возвращаемых значений. Одним из важных пунктов в этом тестировании является проверка кодов ошибок, возвращаемых функциями, а именно: проверка, что функция не возвращает код ошибки, когда она не должна этого делать; проверка, что функция возвращает код ошибки, если это требуется по спецификации; проверка, что в случае ошибки возвращается именно тот код ошибки, который функция должна вернуть согласно требованиям. В процессе работы над тестовым набором задача проверки кодов ошибок возникает для большинства функций, причём обычно эта задача решается однотипно. Поэтому было решено автоматизировать написание исходного кода проверок, насколько это возможно. В данной статье мы расскажем, как была решена эта задача. Во втором разделе будет дана исходная постановка задачи: какие конкретно действия должны быть автоматизированы, и как должна измениться работа по написанию тестов после внедрения этой автоматизации. В третьем разделе описаны технические подробности реализации, возникшие проблемы и их решение. И в заключении рассмотрены возможные пути развития системы в будущем.
Несмотря на то, что работа
Несмотря на то, что работа над пакетом OLVER в настоящее время завершается, описанная в данной статье методика будет применяться при написании тестовых наборов, расширяющих и дополняющих существующие сертификационные тесты на соответствие стандарту LSB, поскольку она очень проста в применении, и при этом генерируемый ей код достаточно универсален. Конечно, нужно понимать, что заранее учесть и продумать все мыслимые комбинации различных ошибочных ситуаций невозможно. Всегда может найтись какая-то очень специфичная функция, требующая нестандартного подхода. И именно эта возможность задаёт направление для дальнейшего развития системы. С одной стороны, в подобных случаях можно попросту подходить к каждой функции индивидуально и писать код, не опираясь на сгенерированные шаблоны. Однако если обнаруженная зависимость не единична, а встречается в нескольких функциях, то стоит сначала оценить трудозатраты: возможно, в такой ситуации имеет смысл доработать систему генерации кода так, чтобы она теперь учитывала и эти новые ситуации. Учитывая, что стандарт LSB активно развивается и включает в себя всё больше и больше функций, можно с уверенностью сказать, что описанная в данной статье система будет развиваться и дальше.
