Документальная поддержка.
В комплект приобретённого инструмента должен входить пакет сопроводительной документации, который включает описание технических возможностей и требований к окружению системы (system requirements), руководство пользователя (user guide), системного администратора (installation guide) и в некоторых случаях руководство администратора системы (process manager guide). Комплект документации должен быть предоставлен в печатном и электронном виде, кроме того, стоит обратить внимание на локализацию документации, так как документация, предоставленная на родном для покупателей / разработчиков языке, будет гораздо быстрее обработана. Самым удобным и эффективным в работе, можно считать электронный вид документации, выполненный по типу MSDN или TechNet. Конечно, такой вариант оформления сопроводительной документации применим при достаточно большом объёме. Такая система требует отдельной инсталляции, является по сути своей отдельным программным продуктом и подходит под классификацию не как документация, а скорее как база знаний. Такого типа система документации позволяет строить более сложные запросы и базируется не только на описании программного продукта или технологии, но включает в себя также и статьи схожей тематики, описания наиболее часто встречаемых проблем, информацию о тематических ресурсах в сети internet.
Интеграция с системами разработки.
Наравне с интеграцией процесса тестирования в процессы проектирования и разработки ПО, современные средства автоматизации процессов тестирования должны предоставлять механизмы интеграции с системами разработки.
Под системами разработки ПО будем понимать не только саму среду разработки (development environment) уровня Visual Studio и Delphi, но и инструменты планирования и управления процессом разработки (к примеру Microsoft Project Manager, DevPartner, Rational Unified Process), документооборота и управления ошибками, конфигурациями (Borland StarTeam, Rational ClearQuest ) и средства централизованного хранения и изменения данных (Visual Source Safe, CVS).
Виды интеграции. Какие сервисы может предоставить современная система автоматизации тестирования в разрезе взаимодействия с системой разработки? Генерация тестовых сценариев на основе модели проектируемой системы (многие системы позволяют проводить анализ моделей Rational Rose и на их основе создавать сценарии использования и прототипы интерфейсов приложения). Генерация наборов тестовых данных на основе систем разработки структур баз данных. Доступ и выполнение unit-тестов или других тестовых процедур в коде приложения. Передача тестовых данных и анализ получаемых результатов. Автоматическая генерация данных для создания запросов на изменение в системах управления ошибками. Генерация отчётов в системах документооборота или офисных приложениях..
Таким образом, система автоматизации тестирования в идеальном случае должна иметь возможность интеграции со всеми типами систем разработки ПО и иметь достаточную гибкость конфигурирования, которая позволит использовать её с используемыми средствами хранения и обработки данных.
Что даёт тесная интеграция с технической точки зрения? Преимущества использования среды автоматизации тестирования выдержанной в рамках общих требований к системе разработки и использующей схожие технологии хранения данных: процесс тестирования можно будет рассматривать как полноценный этап разработки с точки зрения решения проблем технического обеспечения (создание тестовых сред на базе инфраструктуры отдела разработки с последующим выделением в отдельную информационную единицу, обеспечение вычислительными и производственными мощностями, такими как дисковое пространство серверов общего использования, базы данных, распределённая память и т.д.), процесс тестирования получает возможность технического и технологического обеспечения надёжности в рамках обеспечения надёжности всего процесса разработки (механизмы резервного копирования / восстановления данных, сервисные обновления операционных систем и т.д.), к данным и документации процесса тестирования можно применять аналогичные механизмы защиты от сбоев и распространять на них политику безопасности и разграничения доступа, которая выработана для всего процесса разработки в целом (возможность применения доменной политики безопасности и разграничения прав доступа к ресурсам).
Выбор системы автоматизации должен происходить на этапе выбора технологии разработки и инструментария процесса разработки. Построение системы автоматизации тестирования происходит параллельно с построением среды и инфраструктуры разработки. Система, выбранная из нескольких аналогичных по функционалу, но более органично интегрируемая с инструментарием и обеспечением системы разработки, даёт более широкие возможности использования и как следствие повышает окупаемость вложений.
Обучение и сертификация персонала, работающего с набором инструментов и/или методологией.
Время, затраченное персоналом на обучение работе с инструментом, является на этапе внедрения инструмента или технологии тестирования одним из ключевых моментов, на который стоит обращать внимание при разработке планов использования приобретаемого инструмента.
Компания производитель, поставляющая средства автоматизированного тестирования, кроме самой продажи средств должна обеспечивать и сервис для обучения персонала (непосредственных тестировщиков, системных администраторов, администраторов самих систем автоматизации) и менеджеров (руководителей отделов и проектных менеджеров) принципам работы и функциональности, предлагаемой в инструменте. С развитием методик тестирования, также становится всё более необходимым обучение новым методам и подходам в тестировании. Зачастую производитель выходит на рынок не только с инструментом или линейкой интегрированных средств, но и выводит новую методику, воплощая её в оригинальном программном решении. Кроме того, так как сложные системы автоматизации тестирования на данном этапе развития представляют собой не только среду для проведения тестирования, но и инструмент разработки тестовых скриптов, управления тестовыми сценариями и оценки качества программных продуктов, стоит говорить об обучении нескольких рангов пользователей: Разработчиков-программистов в среде автоматизации, как тестировщиков, которые разрабатывают тестовые скрипты, моделируют на основе известных бизнес-процессов тестовые сценарии использования системы, создают скрипты для испытания нагрузок, анализа покрытия кода и т.д. Пользователей, как тестировщиков-испытателей, в обязанности которых входит выполнение разработанных ранее скриптов и сценариев, документирование ошибок и отслеживание дальнейших этапов жизни ошибок. Менеджеров, как руководителей служб тестирования и инженеров качества, которые пользуются результатами работы подразделения тестирования, для анализа процессов разработки, общего качества продукта и уровня его соответствия требованиям заказчика.
Для того, что бы обучение работе с инструментом или методикой могло служить критерием оценки инструмента, нужно определиться с понятием перечнем предоставляемых производителями инструментария услуг, которые могут быть отнесены к разряду обучения: Презентации, как средство ознакомления к технологией, инструментом, решением. Курсы профессиональной подготовки и переподготовки пользователей и разработчиков системы. Курсы профессиональной подготовки и переподготовки менеджеров системы. Сертификация всех категорий пользователей системы.
Курсы и обучение специалистов оказывают прямое влияние на эффективность использования приобретённого и внедрённого инструмента, то есть являются фактором, который влияет на возврат инвестиций в проект автоматизации в целом.
Сертификация же является отличным стимулирующим средством в процессе обучения специалиста технологии или работе с инструментом.
Поддерживаемые процессы тестирования.
Так как система автоматизации тестирования тесно связана с реальными процессами разработки программных систем, а также опирается на определённые процессы тестирования, при анализе необходимо в первую очередь обращать внимание на поддержку инструментом или набором инструментария определённых процессов/технологий тестирования и жизненного цикла разработки ПО. Итак, первый критерий анализа: Поддерживаемые процессы тестирования.
Стоит оговориться, что на данном этапе развития рынка систем автоматизации тестирования, существует два подхода к построению инструментария тестирования. Одним типом можно считать продукты, которые охватывают все технологии тестирования, обработку разноплановой информации, которая описывает этапы разработки и требования к программному продукту, а также осуществляют поддержку процессов генерации проектной документации. Другой тип инструментария можно оценивать как узкопрофильный, то есть не охватывающий все этапы тестирования и жизненного цикла ПО, а осуществляющий полноценную поддержку какого-либо важного функционала. К примеру, в последнее время получили широкое распространение так называемые bug-tracking системы, то есть системы управления ошибками. Для более полного анализа стоит разносить в процессе оценки инструменты разных типов, по разным категориям, одновременно расширяя набор критериев для узкоспециализированных инструментов.
Рассмотрим более подробно технологии и процессы тестирования программного обеспечения, которые могут поддерживаться инструментальными средствами тестирования. Управление жизненным циклом (Lifecycle Management), как процесс тесно связанный с планированием этапов тестирования, как при "водопадной", так и при циклической модели разработки ПО. ресурсов этапов разработки / тестирования. Управление тестированием (Test management), оценка затрат, времени, ресурсов этапов. Организация хранения, использования тестовых сценариев, их организации в тестовые группы, анализ результатов работы. Управление изменениями (Change request management), как процесс специфичный для этапов тестирования, но интегрированный в процесс внесения изменений в программный код. Управление ошибками (Tracking and defect management), процесс отработки обнаруженных ошибок, выявление повторяющихся ошибок, анализа причин их возникновения. Управление требованиями (Requirements management), процесс управления изменяющимися требованиями к разрабатываемой системе. Управление конфигурациями (Configuration management), управление конфигурациями и настройками разрабатываемых систем.
Автоматизирование, как процесс построения автоматизированных окружений, для выполнения однотипных базовых операций (построений билдов, соблюдение версионности, генерация отчетной и проектной документации; создание, хранение, выполнение тестовых процедур, обработка результатов их работы), а также как процесс интеграции систем разработки и тестирования.
Поддержка этих процессов является важным критерием при оценке системы автоматизирования тестирования.
Поддерживаемые технологии.
Под технологиями будем понимать - организованную совокупность процессов, элементов, устройств и методов, используемых для обработки информации. К примеру, технологии .NET, CORBA, OLE, COM, DCOM, COM+ и т.д.
Под поддержкой технологий инструментарием тестирования будем понимать возможность записи и воспроизведения тестовых скриптов, которые будут производить тестовые вызовы элементов программного кода выполненных в стандартах той или иной технологии.
Следует оговориться, что уровень поддержки той или иной технологии существенно различается на уровне реализации тестовых скриптов. К примеру, большинство производителей инструментальных средств тестирования реализуют возможность записи и воспроизведения скриптов имитирующих действия пользователя по отношению к пользовательскому интерфейсу, то есть поддерживаются возможности выбора из набора графического интерфейса программы определённого элемента (контрола) и передачи ему фокуса с последующим выполнением нажатия. Такая поверхностная поддержка, конечно, производит впечатление на потенциального заказчика (довольно эффектно выглядит, к примеру, автоматическое заполнение многостраничных форм регистрации за несколько секунд, даже с генерацией случайных данных из заданного диапазона), но без возможности непосредственной работы с объектной моделью приложения, этот функционал остаётся лишь красивым дополнениям к системе автоматизированного тестирования, чем её основой.
Приведём пример: Есть форма с элементом выпадающий список. Количество элементов списка определяется количество записей в таблице базы данных и есть динамически изменяемая величина. Значения элементов списка представляют, к примеру, числовые данные. Список отсортирован не по величине значений, а по дате последнего изменения этого значения.
Задача: при выполнении тестового скрипта выбрать из выпадающего списка максимальное (или минимальное) значение. Напомним, что список не отсортирован по величине, и выбрать первый или последний элемент, координаты которого можно рассчитать не получится.
Кроме того, количество элементов списка также величина динамическая - выбор последнего элемента затруднён. Нужно получить список всех значений из списка, заполнить ими массив, отсортировать, найти нужное значение. Обратиться к элементу список, споцизионироваться на нужный элемент (задача не просто решаемая перемещением курсора мышки на определённую координату), имитировать нажатие. Без возможности доступа к объектной модели элемента такая задача не решается в приемлемые сроки. Как результат, встречаются скрипты, которые в подобной ситуации просто выбирают какое-то (неуправляемое) значение. Общая картина работы такого тестового скрипта более напоминает тыканье слепого в интерфейс пользователя, чем заполнение формы тестовыми данными.
Суть поддержки той или иной технологии инструментом тестирования состоит в возможности работать через средства инструмента с объектной моделью приложения, вызовами процедур и методов из тестовых скриптов, генерации вводимых данных на основе анализа диапазона передаваемых параметров. Говоря неформальным языком, поддерживаемой можно считать такую технологию, при работе с которой инструмент как минимум "видит" объектную модель приложения, выполненного согласно стандартов технологии.
Если в описании инструмента заявлено, что с его помощью можно проводить тестирование приложений выполненных с поддержкой практически всех технологий, следует внимательно уточнять уровень этой самой поддержки, потому что в большинстве случаев компания разработчик имеет в виду именно запись/воспроизведение имитационных сценариев. Такая поддержка никоим образом не охватывает непосредственно тестирование серверных компонентов или сервисов приложений, выполняющих бизнес-логику приложений. Также практически невозможно оценить в целом уровень производительности приложений, моделируя пользовательскую нагрузку имитацией реальных действий пользователя через пользовательский интерфейс.
Отдельно хотелось бы оговорить специализированные инструменты, которые поддерживают технологии работы с данными, серверные компоненты и сервера баз данных.
В целом картина на рынке таких инструментов отличается от состояния дел на рынке инструментов для тестирования функциональности. Суть таких инструментов, не только создать нагрузку на сервер базы данных (для этого существует отдельный класс так называемых нагрузочных и стрессовых инструментов), с тем, чтобы зафиксировать время отклика и/или выполнения того или иного запроса или вызова. Средства, которые поддерживают технологию какой-то определённой СУБД (Oracle, Informix, DB2, MS SQL) должны обладать не только функционалом вызова, к примеру, хранимых процедур, или подобной функциональностью, которая будет создавать нагрузку и анализировать поведения сервера, но в идеале и проводить анализ конфигурации серверного окружения, структур и схем хранения данных, контроль за следованием стандартам обращений к данным с тем. Результатом работы такого средства может служить сгенерированный набор аналитических данных на основе которых сервер или окружение будет конфигурироваться под конкретную архитектуру базы данных и возможно настраиваться согласно выбранной технологии реализации клиентского приложения.
Указанные требования накладывают существенные ограничения на функциональность подобных средств. Зачастую компания-производитель поддерживает на глубоком уровне только одну конкретную СУБД, разработка инструмента ведётся в тесной интеграции с компанией разработчиком самой СУБД с учётом особенностей архитектуры и технологических решений. Инструментарий получается довольно узкоспециализированный и дорогостоящий, его применения оправдано в случае внедрения долгосрочных промышленных систем автоматизации или систем повышенной отказоустойчивости.
Поддерживаемые типы тестов.
Вторым критерием анализа, логично было бы выделить поддержку различных типов тестов, которые автоматизируются системой. Сообществом тестировщиков и практической работой, выделены основные типы тестов, описание которых поддаётся формализации. Рассмотрим их. Функциональные тесты, которые проводят тестирования пользовательских интерфейсов, моделируя реальную работу пользователя с конечной системой. В этот же раздел входит и так называемое Usability тестирование, которое в последнее время становится неотъемлемой частью процесса тестирования программных систем, а значит должно автоматизироваться наравне с другими типами тестов. Регрессионные тесты, контролирующие сохранение функциональности при переходе к следующей версии (билду) разрабатываемой системы. Нагрузочные тесты, испытание систем на производительность под моделируемой нагрузкой.Тестирование безопасности, как процесс выявление потенциальных уязвимостей системы, определение признаков уязвимости и локализация компонентов или модулей, потенциально ущербных в плане общей безопасности системы. Нагрузочное тестирование и тестирование производительности, как этап тестирования архитектурного решения, конкретной его реализации и конфигураций оборудования. Unit-тесты, как методология разработки, ведомой тестированием. Тестирование модулей, на уровне разработки самого кода.Unit-тесты, как методология разработки, ведомой тестированием. Тестирование модулей, на уровне разработки самого кода. Анализ исходного кода, функционал выявления несоответствий между полученным в результате разработки кодом и принятыми правилами кодирования (code-naming-convention), анализ покрытия и используемости кода. (covering, hit-counting) Анализ утечек памяти, анализ работы системы с операционной средой и ресурсами системы.
Наличие функционала, который позволит автоматизировать выполнение определённого типа тестов, является вторым критерием анализа инструментария средств автоматизации тестирования.
Представительство компании-разработчика в странах ближнего зарубежья.
Почему критерий наличия у компании разработчика представительства в странах ближнего зарубежья (а в идеальном случае и в стране, где находится компания, которая приобретает средство автоматизации) настолько важен?
Одной из причин, по которой компания-разработчик должна иметь представительство или компанию, которая представляет продукты на отечественном рынке, является цена приобретаемого за границей продукта.
В самом деле, на современном этапе развития платёжных систем, сложности при переводе денег, даже для частного лица, в другую страну не может служить поводом для отказа от приобретения инструмента. Одним из моментов, который стоит учитывать, это увеличение стоимости самого инструмента, а стало быть и сроков его окупаемости, в случае переводов за границу и затрат на доставку.
В нашей стране вопросы также возникают вокруг процесса получения самого продукта, если он в целях безопасности не передаётся по каналам связи, а высылается почтой.
"Растаможивание" программного обеспечения также является фактором, увеличивающим его стоимость. А так как серьёзные программные продукты идут в поставке с документацией и дополнительными компонентами, комплект поставки может составлять не один десяток носителей типа компакт-диск. Стоимость услуг "растаможивания" продукта определяется количеством компакт дисков. Прибавим сюда компакт с рекламой и презентацией и вполне реально получаем солидную прибавку к стоимости продукта, цена которого нас устраивала вначале. В пользу важности этого аргумента может послужить тот факт, что многие компании в СНГ и в Украине в частности переводят подписки на продукцию компании Microsoft в план поставки на DVD носителях. Как известно, DVD носители вмещают до 5 Гб полезной информации, а стало быть, могут служить заменой примерно 7-ми компакт-дискам. Зачастую, гораздо выгоднее установить несколько дополнительных приводов для чтения DVD дисков, чем платить за "растаможку" примерно 150 компактов ежеквартального обновления подписки от Microsoft.
Немаловажным моментом также является тот факт, что компания уже работает на рынке, где вы готовы потреблять её продукт, что может служить большим плюсом при оценке уровня зрелости самой компании-производителя и её продуктов в частности. Итак, второй фактор, это уровень зрелости компании, который поддаётся оценке по наличию компании представителя.
По наличию представительства также можно судить о качестве локализации продукта на родной для разработчиков и тестировщиков вашей компании язык. О важности такого атрибута любого программного продукта как локализованная версия программы и сопроводительной документации говорилось в предыдущем разделе.
Идеальным случаем представительства можно читать компанию, которая осуществляет не только продажу и консультации по продукту, но также оказывает услуги поддержки пользователей. Кроме того, что можно рассчитывать на службу поддержки, к которой можно обратиться на родном или родственном языке (имеет смысл для стран СНГ, где русский язык получил широкое распространение), время запросов пользователей будет отличаться не более чем на несколько часов от времени работы службы поддержки, если даже сама служба работает не круглосуточно.
Разработка критериев анализа систем автоматизации тестирования
, автор проекта "Тестер",
Статья была опубликована в Журнале для профессиональных программистов "argc & argv", Выпуск № 6 (51/2003)
Средства автоматизации процессов тестирования представлены на рынке очень широким кругом компаний производителей. Автоматизация тестирования затрагивает всё более глубокие технические процессы разработки ПО и всё глубже интегрируется в процесс его производства. Каким образом начать анализ рынка средств автоматизации тестирования? На что стоит обращать внимание при анализе средств автоматизации тестирования? По каким критериям можно оценивать функциональные возможности инструментов и группировать системы автоматизированного тестирования?
Статья затрагивает вопросы классификации средств тестирования и предлагает систему анализа, основанную на оценке качественных характеристик инструментария и сопутствующих условий внедрения и использования. Рассмотрен широкий спектр критериев: от набора функционала, который реализован в инструменте, до оценки уровня зрелости самой компании производителя и службы поддержки.
Техническая и документальная поддержка компанией разработчиком.
Под критерием технической и документальной поддержки будем понимать уровень организации процесса сопровождения инструментария со стороны компании разработчика.
Техническая поддержка.
Под технической поддержкой будем понимать возможность обратиться в службу технической поддержки, воспользовавшись одним из электронных средств связи или телефон. Особо стоит обратить внимание на круглосуточную поддержку при приобретении средств у западных производителей, так как из-за разницы во времени запросы в службу поддержки могут прийтись на ночное время. Аналогичным критерием при оценке уровня тех поддержки служит поддержка 365 дней в году, так как обращение в службу поддержки должны обрабатываться и в дни религиозных праздников или выходных дней той страны, в которой работает служба поддержки. Уровень доступности поддержки принято оценивать по шкале 365/7/24 - кол-во дней в году / кол-во дней в неделю / кол-во часов в сутки.
Так к факторам оценки уровня технической поддержки стоит отнести скорость реакции службы на запросы клиентов, сопровождение базы вопросов и ответов, которые встречаются наиболее часто, реакция на обнаружение критических ошибок (фиксирование описание критических ошибок в доступном месте на сайте, к примеру), а также работу, как с новыми, так и с постоянными клиентами.
Критическим может оказаться любой из приведённых факторов, так как служба поддержки не может считаться полноценной, если она не доступна круглосуточно и не работает в ожидаемых и заявленных рамках.
Анализ результатов тестирования
На рисунке показана статистическая выкладка, выведенная Coverage по окончании тестирования приложения.

Поле Calls определяет число вызовов функции
Из полученной таблицы видна статистическая информация о том, какие строки и сколько раз исполнялись.
К особенностям работы PureCoverage отнесем тестирование только тех исполняемых файлов, которые уже имеют отладочную информацию от компилятора. Соответственно, тестирование стандартных приложений и библиотек данным продуктом невозможно. Впрочем, и не нужно. Особые преимущества инструмент демонстрирует при совместном тестировании с Robot при функциональном тестировании, подсчитывая строки исходных текстов в момент воспроизведения скрипта. Тем самым на выходе тестировщик (или разработчик) получает информацию о стабильности функциональных компонент, плюс, область покрытия кода (область охвата).

Поле %Lines Hit показывает процентное отношение протестированных строк кода для отдельной функции.

Вид окна перехода на уровень работы с исходным текстом. Из него видно, что PureCoverage ведет нумерацию строки и подсчитывает число исполнений каждой. Не исполнившиеся фрагменты подсвечиваются красным цветом (палитра может регулироваться пользователем)
API
Это дополнительная возможность, предоставляемая Quantify по полному управлению процессом тестирования. API представляет собой набор функций, которые можно вызывать из тестируемого приложения по усмотрению разработчика.
Для получения доступа к API необходимо выполнить ряд действий по подключению «puri.h» файла с определением функций и с включением «pure_api.c» файла в состав проекта. Единственное ограничение, накладываемое API — рекомендации по постановке точек останова после вызовов Quantify при исполнении приложения под отладчиком.
Рассмотрим имеющиеся функции API Quantify: QuantifyAddAnnotation. Позволяет задавать словесное описание, сопровождающее тестирование кода. Информация, заданная разработчиком этой функцией может быть извлечена из пункта «details» меню тестирования и доступна в LOG-файле. На ее основе, тестер может впоследствии использовать особые условия тестирования; QuantifyClearData. Очищает все несохраненные данные; QuantifyDisableRecordingData. Запрещает дальнейшую запись; QuantifyIsRecordingData. Возвращает значение 1 или 0 в зависимости от того производится ли запись свойств или нет; QuantifyIsRunning. Возвращает значение 1 или 0 в зависимости от того проходит тестируемое приложение исполнение в обычном режиме или под Quantify; QuantifySaveData. Данная функция позволяет сохранять текущее состояние — делать снимок (snapshot); QuantifySetThreadName. Функция позволяет разработчикам именовать потоки в произвольном именном поле. По умолчанию Quantify дает имена, наподобие «thread_1», что может не всегда положительно сказываться на читаемости получаемой информации; QuantifyStartRecordingData. Начинает запись свойств. По умолчанию, данная функция автоматически вызывается Quantify при исполнении; QuantifyStopRecordingData. Останавливает запись свойств.
Если модифицировать наше тестовое приложение так, чтобы оно использовало преимущества интерфейса API, то может получиться нечто нижеследующее
int main(int argc, char* argv[])
{
int i; QuantifyAddAnnotation("Тестирование проводится под Quantify с использованием API");
QuantifySetThreadName("Основной поток приложения");
for(i=0;i<12;i++){
QuantifySaveData();
recursive();
}
return 0;
} В листинге показано как можно использовать основные функции API для извлечения максимального статистического набора данных. Рисунки показывают слепки фрагментов экрана Quantify по окончании тестирования.

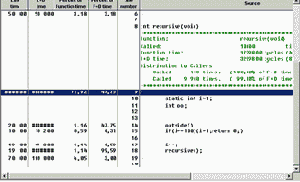
Дерево вызовов «Call Graph»
Следующий интереснейший способ анализа конструкции приложения — это просмотр дерева вызовов. Окно, показанное на 4 рисунке, показывает только фрагмент окна с диаграммой вызовов.

Обратите внимание на количество и последовательность вызова различных модулей потока «main». Жирная линия показывает наиболее длительные ветви (содержащие либо часто вызываемые функции, либо функции, выполнявшиеся дольше остальных). Для демонстрации возможностей Quantify было сконструировано простое приложение, состоящее из функции «main» и двух дополнительных «recursive» и «outside» (см. листинг 1).
Листинг 1. Пример тестируемого приложения, сконструированном в виде консольного приложения из Visual Studio 6.0. Язык реализации «С».
#include "stdafx.h"
//Создаем функцию-заглушку
void outside (void)
{
static int v=0;
v++;
}
//Создаем рекурсивную функцию, исполняющуюся 100 раз
int recursive(void)
{
static int i=0;
int oo;
outside();//Вызываем функцию заглушку
if(i==100){i=1;return 0;}//Обнуляем счетчик и выходим
i++;
recursive();
}
int main(int argc, char* argv[])
{
int i;
for(i=0;i<100;i++)recursive();
//Вызываем 100 раз рекурсивную функцию 100х100
return 0;
}
Приложение простое по сути, но очень содержательное, так как эффективно демонстрирует основные возможности Quantify.
В самом начале статьи мы выдвигали требование, по которому разработчикам не рекомендуется пользоваться рекурсивными функциями.
Тестеры или разработчики, увидев диаграмму вызовов, выделят функцию, находящуюся в полукруге, что является признаком рекурсивного вызова (см. рисунок).

В зависимости от того, на какой из ветвей дерева, находится курсор, выводится дополнительная статистическая информация о временном доступе к выделенной функции и к дочерним, идущим ниже.
Следующий рисунок демонстрирует статистику по функции «recursive».

Более подробно о статистике будет рассказано в следующем материале.
Инструментальные средства поддержки процесса тестирования
Новичков Александр, Костиков Александр
Часть вторая — Инструментальные средства поддержки процесса тестирования
Данный инструмент представляется наиболее простым
Данный инструмент представляется наиболее простым из трех. Основное его отличие невозможность работы с приложениями, в которых отсутствует отладочная информация. Из достоинств отметим возможность одновременного запуска совместно с Purify, что позволяет получить отчеты по утечкам памяти и подсчет числа строк за один проход в тестировании, что существенно экономит время при отладке и тестировании.
Организация тестирования
Как при приемочном тестировании, так и при регрессионном разработчик должен предоставить не только работающий код, удовлетворяющий начальным требованиям, но и делающий это максимально безукоризненно с точки зрения производительности и устойчивости. В дополнение, разработчик должен максимально тщательно проверить исполнение всех строчек написанного им кода, во избежание дальнейших несуразностей, ведь одна из часто встречаемых ошибок — это копирование блоков программного кода в разные части программы, при том, что не все ветви первоначального блока были обработаны и протестированы.
Подобные первоначальные ошибки сводят на «нет» дальнейшее функциональное тестирование, так как низкокачественный код не позволяет тестерам быстро писать скрипт, реализующий тестирование новой формы, так как она полна странностей. Доработка, доработка, доработка...
Интересная деталь: процессоры работают быстро, шины работают быстро, память тоже быстро, а вот программное обеспечение из года в год, от версии к версии работает все медленнее и медленнее, потребляя при этом на порядок больше ресурсов, нежели чем предыдущие версии. Не спасают положение даже оптимизирующие компиляторы! Вторая не менее интересная деталь заключается в скорости разработки. Вы не обращали внимания на то, что аппаратные продукты (процессоры и прочее) обновляются гораздо чаще и выпускаются с меньшим числом ошибок?
Проблема кроется здесь в разных подходах к реализации программного кода в хардверных и софтверных компаниях. В софтверных компаниях, обычно, нет строго организованного процесса тестирования, нет строгой регламентации процесса кодирования, а сам процесс кодирования является особым видом искусства. То есть налицо пренебрежение основополагающими принципами промышленного производства, регламентирующими роли и процессы, входные и выходные значения.
Из нашего опыта работы с партнерами мы знаем не понаслышке о жестких, и даже, жестоких требованиях к программному обеспечению, прошиваемому в аппаратуру, скажем так, у одной компании производителя сотовых телефонов есть требование, в соответствии с которым сотовому телефону «разрешается» зависнуть один раз в год при непрерывной эксплуатации.
И это, не говоря о том, что все пункты меню соответствуют начальным требованиям на 100%. Вот и получается, что при вопросе: «Согласны ли вы, чтобы ваш телефон работал на основе обычной операционной системы (Windows, Unix... или им подобными)?», Традиционно следует — «нет»! Поскольку этап тестирования кода приложения можно отнести к тестированию «прозрачного ящика», когда важен код приложения, то мы попробуем описать основные рекомендации по тестированию для данного этапа, которые почерпаны из личного опыта и основаны на здравом смысле и принципах разумной достаточности. То есть, мы сначала рассмотрим общие требования к качеству кода, а потом проведем ассоциацию с инструментами Rational, которые позволят решить проблемы данного участка. Следующие недостатки (относительные) программного кода могут потенциально привести приложение к состоянию зависания (входа в вечный цикл) или к состоянию нестабильности, проявляемой время от времени (в зависимости от внешних факторов): Использование рекурсии. Всем известна практическая ценность рекурсии для большого числа задач, особенно математических, но рекурсия является и источником проблем, поскольку не все компиляторы и не во всех случаях способны правильно отрабатывать рекурсию. Посему очень часто в требованиях на разработку вводится требование на отсутствие рекурсивных функций. Quantify ведет статистический анализ по вызовам функций и она выдает имена всех рекурсивных функций. Степень вложенности процедур (функций). В программе можно создать любое число функций (классов), вложить их друг в друга, а потом удивляться почему та или иная функция работает с не той производительностью. Если в требованиях на разработку ограничить полет фантазии разработчиков, то получится более быстрое приложение. Статистику по вложенности и скорости даст Quantify. Соглашения о именах. Также оговаривается в требованиях на разработку. Необходимо ввести единый стиль наименования функций, во избежание появления дублей и непонятных имен, что тормозит развитие проекта.
Quantify также реализует поиски рассогласовании в именах. Использование указателей. Язык С и С++ трудно представить без указателей, даже невозможно. Но, являясь гибким и мощным механизмом обращения к памяти, они же являются минами замедленного действия, проявляющими себя в самые неподходящие моменты. Если проект не может существовать без указателей, то все ошибки, связанные с их неправильной работой позволит отловить Purify. Не целевое использование переменных и идентификаторов. Сюда попадают и ошибки связанные с операциями чтения и записи файлов до их открытия или после закрытия. Это и присвоение в переменных до их инициализации. Это и наличие лишних переменных. Эти неточности также могут привести к нестабильности приложения. Purify обрабатывает данную категорию ошибок. Не целевое использование блоков данных. Под эту категорию попадают ошибки связанные с распределением памяти, например, невозвращение блоков памяти после их использования. С точки зрения функциональности подобная ошибка не совсем ошибка, так как целостность приложения не нарушается и к сбоям не ведет. Побочный эффект — это замусоривание системы ненужными данными и быстрое «истекание» системных ресурсов. Данный вид отлавливается Purify. Присутствие участков кода не исполнявшихся в течении определенного времени. Также потенциальная ошибка, так как не выполненный код может содержать ошибки. PureCoverage отлавливает данный вид ошибок.
Основные параметры вывода
Address. IP адрес модуля, в котором обнаружена ошибка или предупреждение; Error Location. Описание модуля с ошибкой. В случае тестирования модуля с исходными текстами, то в данном поле можно просмотреть фрагмент кода, который вызвал появление ошибки; Allocate Location. Разновидность «Error Location», показывает фрагмент кода, в котором был распределен блок памяти, работа с которым, привела к ошибке.
Работа с Purify возможна как при наличии исходных текстов и отладочной информации, так и без нее. В случае отсутствия debug-информации анализ ошибок ведется только по ip-адресам. Так же как и в случае с Quantify, возможен детальный просмотр функций из dll-библиотек. В этом случае наличие отладочной информации не является необходимостью.
Основные свойства средств Purify, Quantify и PureCoverage
Интегрируются со средствами функционального тестирования Robot, TestManager и Visual Test;
Интегрируются с ClearQuest, для документирования и отслеживания возникающих в процессе тестирования ошибок; Выдают точную и детальную информацию о производительности приложения; Используют технологию OCI — Object Code Insertion, что позволяет детально отслеживать и вылавливать ошибки не только в разрабатываемом модуле, но и во внешних библиотека; Представляют комплексный дополнительный обзор данных по производительности, области охвата кода и по стабильности;
Имеют гибкая настройка в соответствии с потребностям разработчиков и тестировщиков; Позволяют многократно тестировать приложение (по ходу разработки), отслеживать изменения для каждой перекомпиляции, формируя тем самым данные для последующего анализа; Интегрируются со средствами разработки (Visual Studio 6.0, Visual Studio .NET, Vis-ual Age For Java); Тестируют компоненты ActiveX, COM/DCOM и ODBC; Имеют интерфейс API, позволяющий дописывать разработчикам собственные для наиболее тщательного и эффективного тестирования.
Особенности запуска
Запуск приложения ведется точно таким же образом, как и в остальных случаях. Здесь нового ничего нет. Из особенностей можно отметить то, что тестировать можно только то приложение, которое содержит отладочную информацию. Данная особенность выделяет PureCoverage из линейки инструментов тестирования для разработчиков, которые могут тестировать как код с отладочной информацией, так и без нее.
При попытке исполнить приложение, не содержащее отладочной информации, на экран, по окончании тестирования, будет выведено сообщение об ошибке.
Параметры тестирования
Перед исполнением тестируемого приложения, возможно, задать дополнительные настройки, которые смогут настроить Purify на эффективное тестирование.
Запуск приложения производится точно также как и в случае с Quantify (по F5 или file->Run). Параметры настройки находятся пункте Settings, появившегося окна.
Первая страница диалога представлена на рисунке

Отметим основные особенности, которые качественно могут сказаться на результирующем отчете: Report at exit. Данная группа позволяет получать более детальную информацию обо всех указателях и блоках памяти, которые не приводили к ошибкам памяти. По умолчанию, Purify выводит отчеты только по тем блокам, которые были распределены, но не были освобождены. В большинстве случаев такой подход оправдан, так как обычно разработчика интересуют именно ошибки. Остальные пункты активизируют по мере необходимости, когда нужно иметь общее представление о использовании памяти тестируемым приложением; Error Suppretion. Группа определяет степенью детальности выводимой информации.
По умолчанию, активирован пункт «Show first message only». В этом случае по окончании тестирования, Purify выводит сокращенный отчет по модулям, то есть, если в одном модуле найдено 10 утечек памяти, то информация об утечках на основном экране будет описывать только имя ошибки, число блоков и имя модуля. То есть мы получаем обобщенную информацию по ошибкам в блоке. В случае необходимости получения отдельного отчета по каждому отдельному блоку, отключаем данный пункт. Call Stack Length. Определяет глубину стека; Red Zone Length. Управляет числом байтов, которое встраивается в код тестируемого приложения при операциях связанных с распределением памяти. Увеличение числа способствует лучшему сбору информации, но существенно тормозит исполнение приложения;
Закладка PowerCheck позволит настроить уровень анализа каждого отдельно взятого модуля. Существует два способа инструментирования тестируемого приложения: Precise и Minimal. В первом случае проводится детальное инструментирование кода, но при этом модуль работает относительно медленно. Во втором случае, проводится краткое инструментирование, при котором Purify вносит в модуль меньше отладочной информации, и, как следствие, способна отловить меньшее число ошибок. Последний подход оправдан, когда приложение вызывает массу внешних библиотек от третьих фирм, которые не будут подвергаться правке.
Quantify, Purify и PureCoverage
Для осуществления всех функций по тестированию программных модулей, все три продукта используют специальную технологию Object Code Insertion, при которой бинарный файл, находящийся под тестированием, насыщается отладочной бинарной информацией, обеспечивающей сбор информации о ходе тестирования.
Отметим общие черты для всех трех программных продуктов. Для сбора и обработки информации программам тестирования нужны два файла: исполняемый модуль и его исходный текст. Исполняемый модуль насыщается отладочным кодом, а наличие исходного текста позволяет разработчику легко переключаться между схематическим отображением и кодом тестируемого приложения.
На код накладываются дополнительные особые ограничения, а именно: тестируемый код должен быть получен при помощи компиляции с опцией «Debug», то есть должен содержать отладочную информацию. В противном случае Quantify, Purify и PureCoverage не смогут правильно отображать (вообще не смогут отображать) имена функций внутренних модулей тестируемого приложения. Исключения могут составлять только вызовы внешних модулей из dll-библиотек, поскольку метод компоновки динамических библиотек позволяет узнавать имена функций.
Отсюда можно сделать простой вывод: тестировать приложения можно даже не имея отладочной информации в модуле и при отсутствии исходных текстов, но в этом случае разработчик получает статистику исключительно по внешним вызовам.
Все три продукта способны проводить особые виды тестирования, такие как тестирование сервисов NT\2000\XP.
Программные продукты могут работать в трех режимах: Независимом графическом. В этом случае каждое средство запускается индивидуально а тестирование осуществляется из него в графическом режиме; Независимом командном. Данный режим характеризуется управлением ходом насыщения тестируемого модуля отладочной информации из командной строки; Интегрированном. Этот режим позволяет разработчикам не выходя из привычной среды разработки (Visual Studio 6.0 или .NET) прозрачно вызывать инструменты Quantify, Purify и PureCoverage.
Из дополнительных возможностей всех инструментов хочется отметить наличие специального набора файлов автоматизации, разрешающих разработчикам еще на этапе разработки внедрять С-образные вызовы функций сбора информации по тестированию в свои приложения, получая при этом максимальный контроль над ними.
Средства анализа, строенные в Quantify, Purify и PureCoverage позволяют удовлетворить детально контролировать все нюансы в исполнении тестируемого приложения. Здесь и сравнение запусков, и создание слепков в ходе тестирования и экспорт в Excel для построения точных графиков множественных запусков.
Особо хочется отметить языковую «всеядность» продуктов.
Поддерживаются следующие языки программирования: Visual C\C++\C# в exe-модулях, dll-библиотеках, ActiveX-компонентах и COM-объектах; Поддерживаются проекты на Visual Basic и Java Applets (с любой виртуальной машиной); Дополнительно можно тестировать дополнительные модули к MS Word и Ms Excel.
Работа с фильтром
Чтобы не загромождать пользовательский интерфейс лишними данными, в Purify предусмотрена система гибких фильтров.
Система фильтров Purify способна регламентировать тип ошибок и предупреждений и ошибок (группировка производится по категориям) к программе, но и число исследуемых внешних модулей (чтобы разработчик мог концентрироваться только на ошибках собственного модуля). Таким образом возможно создание универсальных фильтров с осмысленными именами, которые ограничивают поток информации. Число создаваемых фильтров ничем не ограничено.
Фильтры создаются и назначаются и модифицируются через верхнее меню (View->CreateFilter и View->FilterManager). По умолчанию Purify выводит все сообщения и предупреждения.

Рисунок показывает внешний вид окна создания фильтра (View->CreateFilter). Здесь мы имеем возможность по выбору сообщений, которые нужно отфильтровывать.
Пункт General — управляет именем фильтра и комментарием, его сопровождающим, Source — определяет местоположение исходных файлов, для которых необходимо вывести сообщения. Подход используется в том случае, когда происходит вызов одного модуля из другого, дабы ограничить количество информации в отчете.
Следующий рисунок демонстрирует вид окна настроек фильтров. Здесь имеется возможность по активации\деактвации фильтров и модулей.

Выше упоминалось, что Purify не ограничивает число фильтров. Следует понимать, что не ограничивается не только общее число фильтров, но и их количество на одно протестированное приложение.
Ограничение по модулям, которое также можно выставить в данном диалоге, определяет число внешних модулей, предупреждения от которых появляются в отчете.
Работа с PureCoverage
По принципу работы PureCoverage слегка напоминает Quantify: также подсчитывает количество вызовов функций. Правда, получаемая статистика не столь исчерпывающая как в Quantify (в визуальном отношении), но для проверки области охвата кода вполне и вполне пригодна.
Система отчетности представлена 4-я различными видами отчетов: Coverage Browser. Основное окно просмотра, позволяет просматривать протестированное приложение по модулям или по файлам. Выдает статистику о наличии пропущенных строк; Function List. Выдает отчет по функциям; Annotated Source. Переход к режиму просмотра исходного текста; Run Summary. Общая информация о протестированном приложении;
«Run Summary»
Плавно переходим к следующей стадии тестирования, собственно, к сбору информации. По окончании процесса насыщения отладочным кодом модулей тестируемого приложения, Quantify переходит к его исполнению, производимым, обычным образом, за одним исключением: запись состояний тестируемого приложения продолжает проводиться в фоновом режиме.

Рисунок 3 демонстрирует фрагмент окна «Summary», в котором производится запись состояния тестируемого приложения. Причем, что очень примечательно, тестирование производится не только для простого приложения, но и для много поточного. В последнем случае (см. рисунок 3), тестируется каждый поток отдельно. В любом случае, даже если приложение однопоточное, то имя основного (единственного) потока именуется как «.main_0», что представляется вполне логичным.
Информационный график постепенно наполняется квадратами разного цвета, демонстрирующими текущее состояние тестируемого приложения.
Отметим некоторые из них: Running. Начало исполнения потока; Waiting I\O. Ожидание действий по вводу\выводу; Blocked. Блокирование исполнения потока; Quantify. Ожидание вызова модуля Quantify; Exited. Окончание исполнения потока.
Важный аспект при тестировании — получение статистической информации о количестве внешних библиотек, которые вызывало основное приложение, а также элементарное описание машины, на которой проводилось тестирование. Последнее особенно важно, так как бывает, что ошибка проявляется только на процессорах строго определенной серии или производителя. Все статистические аспекты решаются внутри окна «Summary».
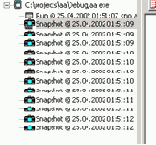
Следующие два примера показывают статистическую информацию:
(1) Общий отчет — «Details»:
Program Name: C:\projects\aa\Debug\aa.exe
Program Arguments:
Working Directory: C:\projects\aa\Debug
User Name: Alex
Product Version: 2002.05.00 4113
Host Name: ALEX-GOLDER
Machine Type: Intel Pentium Pro Model 8 Stepping 10
# Processors: 1
Clock Rate: 847 MHz
O/S Version: Windows NT 5.1.2600
Physical Memory: 382 MBytes
PID: 0xfbc
Start Time: 24.04.2002 14:17:38
Stop Time: 24.04.2002 14:17:52
Elapsed Time: 13330 ms
# Measured Cycles: 191748 (0 ms)
# Timed Cycles: 2489329 (2 ms)
Dataset Size (bytes): 0x4a0001. (2) «Log»
Quantify for Windows,
Copyright (C) 1993- 2001 Rational Software Corporation All rights reserved.
Version 2002.05.00; Build: 4113;
WinNT 5.1 2600 Uniprocessor Free
Instrumenting:
Far.exe 620032 bytes
ADVAPI32.DLL 549888 bytes
ADVAPI32.DLL 549888 bytes
USER32.DLL 561152 bytes
USER32.DLL 561152 bytes
SHELL32.DLL 8322560 bytes
SHELL32.DLL 8322560 bytes
WINSPOOL.DRV 131584 bytes
WINSPOOL.DRV 131584 bytes
MPR.DLL 55808 bytes
MPR.DLL 55808 bytes
RPCRT4.DLL 463872 bytes
RPCRT4.DLL 463872 bytes
GDI32.DLL 250880 bytes
GDI32.DLL 250880 bytes
MSVCRT.DLL 322560 bytes
MSVCRT.DLL 322560 bytes
SHLWAPI.DLL 397824 bytes
SHLWAPI.DLL 397824 bytes Для разработчика или тестера информация (информационный отчет), представленная выше, способна пролить свет на те статистические данные, которые сопровождали, а точнее, формировали среду тестирования.
Сохранение данных и экспорт
Традиционные операции над файлами присущи и программе Quantify. Дополнительные особенности заключаются в том, что сохранять данные можно как во встроенном формате (qfy), для каждого отдельного запуска, так и в текстовом виде, для последующего использования в текстовых редакторах, либо для дальнейшей обработки скриптовыми языками типа perl (более подробно смотрите об этом в разделах по ClearCase и ClearQuest).
Quantify позволит переносить таблицы через буфер обмена в Microsoft Excel, что открывает безграничные возможности по множественному сравнению запусков, по построению графиков и различных форм. Все что необходимо сделать — это только скопировать данные из одной программы и поместить в другую известным способом.
Purify позволяет сохранять результаты тестирования (file->save copy as) в четырех различных представлениях, позволяющих наиболее эффективным образом получить информацию о ходе тестирования.
Рассмотрим варианты сохранения: Purify Error unfiltered. Сохраняет данные о тестировании в виде «как есть» без фильтров; Purify error filtered. Сохраняет данные о тестировании с примененными фильтрами; Text expended. Сохраняет данные в текстовом виде о тестировании в расширенном представлении (с выводом найденных ошибок, с кратким описанием); Text view. Сохраняет только упоминание о найденных ошибках, без дополнительного описания
При установленном MS Outlook, возможно отправление отчета почтой через пункт file->send из верхнего меню Purify.
Данные из инструмента тестирования сохраняются в текстовом файле (как и в двух предыдущих случаях). Текстовый формат выдачи информации делает возможным включать различные обработчики отчетов основанные на скриптовых языках (например, при помощи Perl, можно «выудить» специфичные поля из текстового отчета и поместить их в средство документирования, получив отчет).
Пример фрагмента отчета приведен ниже:
CoverageData WinMain Function D:\xp\Rational\Coverage\Samples\hello.c D:\xp\Rational\Coverage\Samples\hello.exe 0 1 1 100.0 5 5 10 50.00 36 1
SourceLines D:\xp\Rational\Coverage\Samples\hello.c D:\xp\Rational\Coverage\Samples\hello.exe
LineNumber LineCoverage
18.1 0
23.1 0
26.1 0
26.1 0
27.1 0
27.1 0
PureCoverage также как и Quantify может переносить табличные данные в Microsoft Excel.
Сообщения об ошибках и предупреждениях
Для того, чтобы иметь представление о возможностях продукта, опишем то, какие ошибки и потенциальные ошибки могут присутствовать в тестируемом приложение.
Отметим разницу между ошибкой и потенциальной ошибкой и опишем:
Ошибка — свершившийся факт нестабильной или некорректной работы приложения, проводящий к неадекватным действиям приложения или системы. Примером подобной ошибки можно считать выход за пределы массива или попытка записи данных по 0 адресу;
Потенциальная ошибка — в приложении имеется фрагмент кода, который при нормальном исполнении не приводит к ошибкам. Ошибка возникает только в случае стечения обстоятельств, либо не проявляет себя никогда. К данной категории можно отнести такие особенности, как инициализация массива с ненулевого адреса, скажем, имеется массив на 100 байт, но каждый раз обращение к нему производится с 10 элемента. В этом случае Purify считает, что имеется потенциальная утечка памяти размером в 10 байт.
Естественно, что подобное поведение может быть вызвано спецификой приложения, например, так вести себя может текстовый редактор. Поэтому в Purify применятся деление информации на ошибки и потенциальные ошибки (которые можно воспринимать как специфику).
Список ошибок и потенциальных ошибок достаточно объемен и постоянно пополняется. Кратко опишем основные сообщения, выводимые после тестирования: Array Bounds Read Выход за пределы массива при чтении; Array Bounds Write Выход за пределы массива при записи; Late Detect Array Bounds Write Cообщение указывает, что программа записала значение перед началом или после конца распределенного блока памяти; Beyond Stack Read Сообщение указывает, что функция в программе собирается читать вне текущего указателя вершины стека; Freeing Freed Memory Попытка освобождения свободного блока памяти; Freeing Invalid Memory Попытка освобождения некорректного блока памяти; Freeing Mismatched Memory Сообщение указывает, что программа пробует; Free Memory Read Попытка чтения уже освобожденного блока памяти; Free Memory Write Попытка записи уже освобожденного блока памяти; Invalid Handle Операции над неправильным дескриптором;
ptr[1] = ‘r’;
ptr[2] = ‘r’;
ptr[3] = ‘o’;
ptr[4] = ‘r’;
for (int i=0; i <= 5; i++) {
//Ошибка, при i=5 – выход за пределы массива
cerr << "ptr[" << i << "] == " << ptr[i] << '\n';
}
delete[] ptr;
return(0);
} ABW: Array Bounds Write. Выход за пределы массива при записи Вероятность того, что приложение может неадекватно вести себя из-за данной ошибки более высоко, так как запись по адресу, превышающим размер блока, вызывает исключение. Отметим, что память можно определить статически, массовом, как показано в примере. А можно динамически (например, выделив блок памяти по ходу исполнения приложения). По умолчанию, Purify успешно справляется только с динамическим распределением, четко выводя сообщение об ошибке. В случае статического распределения, все зависит от размеров «кучи» и настроек компилятора. #include <iostream.h>
#include <windows.h>
int main(int, char **)
{
char * ptr = new char[5];//Выделяем память под массив из 5символов
for (int i=0; i <= 5; i++) {
//Ошибка, при i=5 - выход за пределы массива
ptr[i] = ‘!’;
cerr << "ptr[" << i << "] == " << ptr[i] << '\n'; //ABW + ABR when i is 5
}
delete[] ptr;
return(0);
} ABWL: Late Detect Array Bounds Write. Cообщение указывает, что программа записала значение перед началом или после конца распределенного блока памяти #include <iostream.h>
#include <windows.h>
int main(int, char **)
{
char * ptr = new char[5];//Выделяем память под массив из 5 символов
for (int i=0; i <= 5; i++) {
//Ошибка – попытка записи после блока выделенной памяти
ptr[i] = ‘!’;
cerr << "ptr[" << i << "] == " << ptr[i] << '\n';
}
delete[] ptr; //ABWL: ОШИБКА
return(0);
} BSR: Beyond Stack Read. Сообщение указывает, что функция в программе собирается читать вне текущего указателя вершины стека Категория: Stack Error
#include <windows.h>
#include <iostream.h>
#define A_NUM 100
char * create_block(void)
{
char block[A_NUM];//Ошибка: массив должен быть статическим
for (int i=0; i < A_NUM; i++) {
block[i] = ‘!’;
}
return(block);//Ошибка: неизвестно, что возвращать
} int main(int, char **)
{
char * block;
block = create_block();
for (int i=0; i < A_NUM; i++) {
//BSR: нет гарантии, что элементы из "create_block" до сих пор находятся в стеке
cerr << "element #" << i << " is " << block[i] << '\n';
}
return(0);
} FFM: Freeing Freed Memory. Попытка освобождения свободного блока памяти. В большом приложении трудно отследить момент распределения блока и момент освобождения. Очень часто методы реализуются разными разработчиками, и, соответственно, возможна ситуация, когда распределенный блок памяти освободается дважды в разных участках приложения. Категория: Allocations and deallocations
#include <iostream.h>
#include <windows.h>
int main(int, char **)
{
char *ptr1 = new char;
char *ptr2 = ptr1;//Ошибка: должен дублировать объект, а не копировать указатель
*ptr1 = ‘a’;
*ptr2 = ‘b’;
cerr << "ptr1" << " is " << *ptr1 << '\n';
cerr << "ptr2" << " is " << *ptr2 << '\n';
delete ptr1;
delete ptr2;//Ошибка – освобождение незанятой памяти
return(0);
} FIM: Freeing Invalid Memory. Попытка освобождения некорректного блока памяти. Разработчики часто путают простые статические значения и указатели, пытаясь освободить то, что не освобождается. Компилятор не всегда способен проанализировать и нейтрализовать данный вид ошибки. Категория: Allocations and deallocations
#include <iostream.h> int main(int, char **)
{
char a;
delete[] &a;//FIM: в динамической памяти нет объектов для уничтожения
return(0);
} FMM: Freeing Mismatched Memory. Сообщение указывает, что программа пробует освобождать память с неправильным ВЫЗОВОМ API для того типа памяти Категория: Allocations and deallocations
#include <windows.h> int main(int, char **)
{
HANDLE heap_first, heap_second;
heap_first = HeapCreate(0, 1000, 0);
heap_second = HeapCreate(0, 1000, 0);
char *pointer = (char *) HeapAlloc(heap_first, 0, sizeof(int));
HeapFree(heap_second, 0, pointer);
//Ошибка – во второй куче не выделялась память
HeapDestroy(heap_first);
HeapDestroy(heap_second);
return(0);
} FMR: Free Memory Read. Попытка чтения уже освобожденного блока памяти Все та же проблема с указателем. Блок распределен, освобожден, а потом, в ответ на событие, по указателю начинают записываться (или читаться) данные. Категория: Invalid pointers
#include <iostream.h>
#include <windows.h>
int main(int, char **)
{
char *ptr = new char[2];
ptr[0] = ‘!’;
ptr[1] = ‘!’;
delete[] ptr;//Ошибка – освобождение выделенной памяти
for (int i=0; i < 2; i++) {
//FMR: Ошибка- попытка чтения освобождённой памяти
cerr << "element #" << i << " is " << ptr[i] << '\n';
}
return(0);
} FMW: Free Memory Write. Попытка записи уже освобожденного блока памяти Категория: Invalid pointers
#include <iostream.h>
#include <windows.h>
int main(int, char **)
{
char *ptr = new char[2];
ptr[0] = ‘!’;
ptr[1] = ‘!’;
delete[] ptr;//специально освобождаем выделенную память
for (int i=0; i < 2; i++) {
ptr[i] *= ‘A’; //FMR + FMW: память для *ptr уже освобождена
cerr << "element #" << i << " is " << ptr[i] << '\n'; //FMR
}
return(0);
} HAN: Invalid Handle. Операции над неправильным дескриптором Категория: Invalid handles
#include <iostream.h>
#include <windows.h>
#include <malloc.h>
int main(int, char **)
{
int i=8;
(void) LocalUnlock((HLOCAL)i);//HAN: i – не является описателем объекта памяти
return(0);
} HIU: Handle In Use. Индикация утечки ресурсов. Неправильная индикация дескриптора. #include <iostream.h>
#include <windows.h>
static long GetAlignment(void)
{
SYSTEM_INFO desc;
GetSystemInfo(&desc);
return(desc.dwAllocationGranularity);
}
int main(int, char **)
{
const long alignment = GetAlignment();
HANDLE handleToFile = CreateFile("file.txt",
GENERIC_READ|GENERIC_WRITE, 0, NULL, CREATE_ALWAYS,
FILE_ATTRIBUTE_NORMAL, NULL);
if (handleToFile == INVALID_HANDLE_VALUE) { cerr << "Ошибка открытия, создания файла\n";
return(1);
}
HANDLE handleToMap = CreateFileMapping(handleToFile, NULL, PAGE_READWRITE, 0, alignment, "mapping_file");
if (handleToMap == INVALID_HANDLE_VALUE) {
cerr << "Unable to create actual mapping\n";
return(1);
}
char * ptr = (char *) MapViewOfFile(handleToMap, FILE_MAP_WRITE, 0, 0, alignment); if (ptr == NULL) {
cerr << " Unable to map into address space\n";
return(1);
}
strcpy(ptr, "hello\n");
//HIU: handleToMap до сих пор доступен и описывает существующий объект
return(0);
} IPR: Invalid Pointer Read. Ошибка обращения к памяти, когда программа пытается произвести чтение из недоступной области Категория: Invalid pointers
#include <iostream.h> #include <windows.h>
int main(int, char **)
{
char * pointer = (char *) 0xFFFFFFFF;
//Ошибка - указатель на зарезервированную область памяти
for (int i=0; i < 2; i++) {
//IPR: обращение к зарезервированной части адресного пространства
cerr << "pointer[" << i << "] == " << pointer[i] << '\n';
}
return(0);
} IPW: Invalid Pointer Write. Ошибка обращения к памяти, когда программа пытается произвести запись из недоступной области Категория: Invalid pointers
#include <iostream.h>
#include <windows.h>
int main(int, char **)
{
char *pointer = (char *) 0xFFFFFFFF;
//Ошибка - указатель на зарезервированную область памяти
for (int i=0; i < 2; i++) {
//IPW + IPR: обращение к зарезервированной части адресного пространства
pointer[i] = ‘!’;
cerr << "ptr[" << i << "] == " << ptr[i] << '\n';
}
return(0);
} MAF: Memory Allocation Failure. Ошибка в запросе на распределение памяти.
Возникает в случаях, когда производится попытка распределить слишком большой блок памяти, например, когда исчерпан файл подкачки. Категория: Allocations and deallocations
#include <iostream.h>
#include <windows.h>
#define BIG_BLOCK 3000000000 //размер блока
int main(int, char **)
{
char *ptr = new char[BIG_BLOCK / sizeof(char)];
//MAF: слишком большой размер для распределения
if (ptr == 0) {
cerr << "Failed to allocating, as expected\n";
return (1);
} else {
cerr << "Got " << BIG_BLOCK << " bytes @" << (unsigned long)ptr << '\n';
delete[] ptr;
return(0);
}
} MLK: Memory Leak. Утечка памяти Распространенный вариант ошибки. Многие современные приложения грешат тем, что не отдают системе распределенные ресурсы по окончании своей работы. Категория: Memory leaks
#include <windows.h>
#include <iostream.h>
int main(int, char **)
{
(void) new int[1000];
(void) new int[1000];
//результат потери памяти
return(0);
} MPK: Potential Memory Leak. Потенциальная утечка памяти
Иногда возникает ситуация, в которой необходимо провести инициализацию массива не с нулевого элемента. Purify считает это ошибкой. Но разработчик, пишущий пресловутый текстовый редактор может инициализировать блок памяти не с нулевого элемента. Категория: Memory leaks
#include <iostream.h>
#include <windows.h>
int main(int, char **)
{
static int *pointer = new int[100000];
pointer += 100;//MPK: потеряли начало массива
return(0);
} NPR: Null Pointer Read. Попытка чтения с нулевого адреса
Бич всех программ на С\С++. Очень часто себя ошибка проявляет при динамическом распределении памяти приложением, так как не все разработчики ставят условие на получение блока памяти, и возникает ситуация, когда система не может выдать блок указанного размера и возвращает ноль. По причине отсутствия условия разработчик как не в чем не бывало начинает проводить операции над блоком, адрес в памяти которого 0. Категория: Invalid pointers
#include <iostream.h>
#include <windows.h>
int
main(int, char **)
{
char * pointer = (char *) 0x0; //указатель на нулевой адрес
for (int i=0; i < 2; i++) {
//NPR: попытка чтения с нулевого адреса
cerr << "pointer[" << i << "] == " << pointer[i] << '\n';
}
return(0);
} NPW: Null Pointer Write. Попытка записи в нулевой адрес Категория: Invalid pointers
#include <iostream.h>
#include <windows.h>
int
main(int, char **)
{
char * pointer = (char *) 0x0; //указатель на нулевой адрес
for (int i=0; i < 2; i++) {
//NPW: ошибка доступа
pointer[i]=’!’;
cerr << "pointer[" << i << "] == " << pointer[i] << '\n';
}
return(0);
} UMC: Uninitialized Memory Copy. Попытка копирования непроинициализированного блока памяти Категория: Unitialized memory
#include <iostream.h>
#include <windows.h>
#include <string.h> int main(int, char **)
{
int * pointer = new int[10];
int block[10];
for (int i=0; i<10;i++)
{
pointer[i]=block[i]; //UMC предупреждение
cerr<<block[i]<<”\n”; }
delete[] pointer;
return(0);
} UMR: Uninitialized Memory Read. Попытка чтения непроинициализированного блока памяти Категория: Unitialized memory
#include <iostream.h>
#include <windows.h>
int main(int, char **)
{
char *pointer = new char;
cerr << "*pointer is " << *pointer << '\n';
//UMR: pointer указывает на непроинициализированный элемент
delete[] pointer;
return(0);
}
Список вызовов функций «Function List»
Одно из наиболее важных статистических окон. Здесь в табличном виде выводится статистическая информация по числу и времени работы каждой функции. Рисунок 6 демонстрирует окно с включенной сортировкой по числу вызовов каждой функции. В качестве дополнительной информации включен список формальных параметров вызовов функций. Подобную информацию можно получить только в том случае, когда тестируется модуль с отладочным кодом, к которому прилагается исходный текст.
Единицы измерения длительности работы функций могут быть следующими: Микросекунды; Миллисекунды; Секунды; Машинные циклы.
На рисунке приведены цифры соответствующие машинным циклам.

Полученная таблица вызовов анализируется тестером или разработчиком для выяснения узких мест в производительности приложения.
К сожалению, для принятия решения о производительности приложения, а точнее, производительности отдельных его функций можно принимать только рассматривая данный вопрос в комплексном разрезе. А именно, принимается во внимание и число вызовов каждой функции, и среднее время доступа к функции и общее время работы функции, и, наконец, то использовались ли при компиляции определенные специфические настройки компилятора.
Это комплексный подход, не предполагающий однозначного совета.
Сначала рассмотрим описание столбцов в появившейся таблице. Хотя многие из пунктов и являются интуитивно понятными, все же попробуем дать им короткое описание: Function. Наименование функции. Можно высвечивать число и тип формальных параметров вызова данной функции. Calls. Число вызовов. Величина абсолютная. Function Time. Общее время исполнения всех вызовов данной функции Max F Time. Максимальное время функции Module. Полный путь до модуля с функцией (бинарного) Min F Time. Минимальное время работы функции Source File. Полный путь до исходных текстов модуля.
По любому из предложенных полей можно провести сортировку в прямом и обратном порядке, а также наложить фильтр на определенные модули, например, для проверки только внутренних модулей или только внешних.
Выделить из списка узкую функцию трудно, поскольку для правильного расчета нужно принимать во внимание и время работы функции и число вызовов.
Причем, число вызовов не всегда может быть показателем медлительности функции (вызывается часто, а работает быстро). Трудно давать какие либо советы по оптимизации кода, тем более, что в этой редакции мы не ставили перед собой подобных целей. По теории оптимизации написаны громадные труды, к которым мы с радостью и отправляем читателей. Можно, конечно, дать общие рекомендации по улучшению производительности кода и его эффективности: Использовать конструкцию «I++» вместо «I=I+1», так как компиляторы транслируют первую конструкцию в более эффективный код. К сожалению, этот эффективность примера ограничена настройками используемого компилятора, и иногда бывает равнозначной по быстродействию; Использовать прием развертывания циклов. Такой же старый прием оптимизации работы относительно простых циклов. Эффект заключается в сокращении числа проверок условия счетчика, так при проверке выполняются очень медленные функции микропроцессора (функции перехода). То есть вместо кода: For(i=0;i<100;i++)sr=sr+1; Лучше писать: For(i=0;i<100;i+=2)
{
sr++;
sr++;
} Использовать тактику отказа от использования вычисляющих конструкций внутри простых циклов. То есть, если иметь подобный фрагмент кода: for (sr = 0; sr < 1000; sr++)
{
a[sr] = x * y;
} то его лучше преобразовать в такой: mn= x * y;
for (sr = 0; sr < 1000; sr++)
{
a[sr] = mn;
} поскольку мы избавляемся от лишней операции умножения в простом цикле; Там где возможно при работе с многомерными массивами, обращаться с ними как с одномерными. То есть, если есть необходимость в копировании или инициализации, например, двумерного массива, то вместо кода: int sr[400][400];
int j, i; for (i = 0; i < 400; i++)
for (j = 0; j < 400; j++)
sr[j][i] = 0; лучше использовать конструкцию, в которой нет вложенного цикла: int sr[400][400];
int *p = &sr[0][0]; for (int i = 0; i < 400*400; i++)
p[sr] = 0; // или *p++=0, что для большинства компиляторов одно и тоже
Также при работе с циклами выгодно использовать слияния, когда несколько коротких однотипных циклов сливаются вместе.
Подобный подход также дает прирост в производительности кода; В математических приложениях, требующих больших вычислений с плавающей точкой, или с большим количеством вызовов тригонометрических функций, удобно не производить все вычисления непосредственно, а использовать подготовленные значения в различных таблицах, обращаясь к ним как к индексам в массиве. Подход очень эффективен, но, к сожалению, как и многие эффективные подходы применим не всегда; Короткие функции в классах лучше оформлять встроенными (inline); В строковых операциях, в операциях копирования массивов лучше пользоваться не собственными функциями, а применять для этого стандартные библиотеки компилятора, так как эти функции, как правило, уже оптимизированы по быстродействию; Использовать команды SSL и MMX, поскольку в достаточно большом круге задач они способны дать ускорение работы приложений в разы. Под такие задачи попадают задачи по работе с матрицами и векторами (арифметические операции над матрицами и векторами); Использовать инструкции сдвига вместо умножений и делений там, где это позволяет делать логика программы. Например, инструкция S=S<<1 всегда эффективнее, чем S=S*2; Конечно, это далеко не полный список приемов оптимизации кода по производительности и качеству. Для этого есть масса других книг. Примеры здесь имеют чисто утилитарный подход: демонстрация возможностей Quantify в плане исследования временных характеристик кода. Используя все средства сбора и отображения, разработчик постепенно сможет использовать только эффективные конструкции, что поднимет производительность на недосягаемую ранее высоту. По любой функции можно вывести более детальный отчет (см. рисунок). Из него можно почерпнуть информацию о числе дочерних функций и то, откуда они были произведены. Следующий рисунок демонстрирует данную возможность.

Способы запуска
Все инструментальные средства могут работать на 3 уровнях исполнения: Исполнение из меню операционной системы. Используется в большинстве случаев, как разработчиками так и тестировщиками. Последними чаще, так как у тестировщиков может не быть среды разработки; Исполнение из среды разработки (если есть интеграция с конкретным средством). Применяется в тех случаях, когда инструмент имеет интеграцию со средством разработки. Представляется наиболее удобным вариантом работы для разработчиков; Исполнение из командной строки. Применяется в специфических ситуациях: при интеграции со средствами автоматизированного тестирования функционального интерфейса, а также при тестировании особых приложений (таких как сервисы Win32).
Сравнивание запусков «Compare Runs»
В большинстве случаев требуется иметь не только сведения об отдельных запусках, но и сравнения разных запусков в различных комбинациях для прогнозирования и анализа. Ведь всегда интересно знать быстро работает исправленная функция или медленно, по сравнению с тем, что было до этого.
Подобная аналитическая информация позволить иметь достаточно четкое представление о том находятся ли функции в прогрессирующем или в регрессирующем состоянии.
Для вызова модуля сравнения необходимо воспользоваться кнопкой (Compare Runs), выделив один из запусков, и указав на любой другой (каждый новый запуск отображается в истории запусков на левой части рабочего поля Quantify).
Для осуществления не пустого сравнения, в пример, рассмотренный выше, намеренно были внесены изменения, увеличившие число вызовов функций. Данные были сохранены и перекомпилированы и снова исполнены в Quantify. Результат представлен на рисунке:

Сравнение запусков позволяет проводить сравнительный анализ между базовым запуском (base – том, с которого все началось) и новым (new).
Результаты сравнения также остаются в проекте Quantify и сохраняются на протяжении жизненного цикла разработки проектов.
Наравне со сравнением запуск можно воспользоваться суммированием, нажав на кнопку

Можно сравнивать и складывать также запуски вместе со слепками (snapshot), которые позволяют оформить текущее количественное состояние в работе приложения в виде отдельного запуска. В дальнейшем над ним можно провести любую логическую операцию.
Ценность слепков проявляется тогда, когда необходимо узнать число вызовов каждой функции до свершения определенного события, например, до входа в определенный пункт меню в тестируемом приложении.
Тестирование сервисов Windows NT//XP
Одно из важных преимуществ перед конкурентами — возможность тестирования специальных приложений, таких как сервисы.
собенность работы заключается в том, что сервис нельзя запускать из среды разработки. Инструменты тестирования понимают это, и предлагают свое решение, по которому необходимо насытить код откомпилированного сервиса (с отладочной информацией) отладочной информацией (не запустив при этом). Полученные в результате файл зарегистрировать в качестве сервиса. Сделать это можно как из GUI так и из командной строки. Мы рассмотрим последовательность шагов для командной строки, демонстрируя ее возможности (в примере, используется ссылка на Purify, но вместо него подставить имя любого средства тестирования): Правильно настроить системные пути таким образом, чтобы из них были видны все директории Purify (особенно кеш: \Program Files\Rational\Purify), иначе процесс не пойдет на исполнение; Откомпилированный сервис нужно запустить Purify из командной строки следующим образом: purify /Run=no /Out=service_pure.exe service.exe. Как видно из параметров, Purify инструментирует файл service.exe, помещая его копию вместе с OCI в service_pure.exe. Все происходит без запуска; В ключе реестра \HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services необходимо поставить ссылку на кешированный файл (service_pure.exe); Во вкладке сервисов активировать пункт Allow Service to Interact with Desktop, выбрать режим запуска "manual".
По окончании действий, в зависимости от типа операционной системы, необходимо перезапустить сервис или перезагрузить компьютер и запустить сервис.
В момент старта сервиса инструмент тестирования запустится автоматически.
Поскольку специальные программные средства могут не иметь графической оболочки, то для их детальной проработки рекомендуется использование функций API из инструментов тестирования для разработчиков.
Приведем список программных продуктов, рекомендованных
Приведем список программных продуктов, рекомендованных к использованию в тестировании на разных этапах. Вот их наименования и краткое описание: Rational Quantify. Профилирование производительности;
Rational Purify. Отслеживание ошибок с распределением памяти;
Rational PureCoverage. Отслеживание области покрытия кода;
Rational TestManager. Планирование тестирования;
Rational Robot. Выполнение функциональных тестов. Программные продукты будут описаны в порядке применения в проектах. Сначала рассмотрим средства тестирования для разработчиков (Quantify, Purify, PureCoverage). Данные средства неразрывно связаны с языком реализации и со средой разработки. Примеры, приведенные в книги ориентированы на язык программирования С++ и частично на С#. В связи с тем, что на момент написания была доступна только бета-версия Visual Stu-dio .NET, то мы в основном ориентировались на версию 6.0, лишь изредка демонстрируя возможности новой среды. Тоже касается и языка реализации C#. Примеры его использования также будут встречаться, но все же основное внимание будет уделено языку реализации С++, имеющем наивысший рейтинг среди языков для реализации крупных программных систем. К сожалению, за бортом остались Java и Basic, но мы надеемся, что разработчики воспримут все написанное здесь как модель реализации, подходы которой совместимы со многими языками программирования. В следующей части перейдем к функциональному и нагрузочному тестированию. Начнем рассмотрение функционального тестирования с его планирования, чьи данные неразрывно связаны с требованиями, полученными на этапе определения требований к системе. Test Manager, в этом разрезе является как средством планирования тестирования, так средством реализации различных видов тестирования, так и средством предоставления финальной, пост — тестовой, отчетности. Далее воспользуемся продуктом Robot, который осуществляет физическую запись скриптов тестирования, с их последующим воспроизведением. Ознакомимся с визуальными и ручными режимами составления тестов посредством Robot. Научимся составлять как функциональные скрипты так и варианты нагрузочных скриптов. Рассмотрим различные режимы работы продукта. Для полного понимания возможностей, опишем основные синтаксические нотации скриптовых языков SQA Basic. В завершении опишем связи средств тестирования с остальными программными продуктами Rational.
Quantify, вставляя отладочный код в бинарный текст тестируемого модуля, замеряет временные интервалы, которые прошли между предыдущим и текущими запусками. Полученная информация отображается в нескольких видах: табличном, графическом, комбинированном. Статистическая информация от Quantify позволит узнать какие dll библиотеки участвовали в работе приложения, узнать список всех вызванных функций с их именами, формальными параметрами вызова и с статистическим анализатором, показывающим сколько каждая функция исполнялась. Гибкая система фильтров Quantify позволяет, не загромождая экран лишними выводами (например, системными вызовами), получать необходимую информацию либо только о внутренних, программных вызовах либо только о внешних, либо комбинируя оба подхода. Вооружившись полученной статистикой, разработчик без труда выявит узкие места в производительности тестируемого приложения и устранит их в кратчайшие сроки.
Начать описание возможностей продукта Rational Purify хочется перефразированием одного очень известного изречения: «с точностью до миллиБАЙТА». Данное сравнение не случайно, ведь именно этот продукт направлен на разрешение всех проблем, связанных с утечками памяти. Ни для кого не секрет, что многие программные продукты ведут себя «не слишком скромно», замыкая на себя во время работы все системные ресурсы без большой на то необходимости. Подобная ситуация может возникнуть вследствие нежелания программистов доводить созданный код «до ума», но чаще подобное происходит не из за лени, а из-за невнимательности. Это понятно — современные темпы разработки ПО в условиях жесточайшего прессинга со стороны конкурентов не позволяют уделять слишком много времени оптимизации кода, ведь для этого необходимы и высокая квалификация, и наличие достаточного количества ресурсов проектного времени. Как мне видится, имея в своем распоряжении надежный инструмент, который бы сам в процессе работы над проектом указывал на все черные дыры в использовании памяти, разработчики начали бы его повсеместное внедрение, повысив надежность создаваемого ПО. Ведь и здесь не для кого не секрет, что в большинстве сложных проектов первоочередная задача, стоящая перед разработчиками заключается в замещении стандартного оператора «new» в С++, так как он не совсем адекватно себя ведет при распределении памяти. Вот на создании\написании собственных велосипедов и позволит сэкономить Purify. Рисунок демонстрирует внешний вид программы после проведения инструментирования (тестирования) программного модуля.

Основное назначение продукта — выявление участков кода, пропущенного при тестировании приложения — проверка области охвата кода. Очевидно, что при тестировании разработчику или тестировщику не удастся проверить работоспособность абсолютно всех функций. Также невозможно за один проход тестирования исполнить приложение с учетом всех условных ветвлений. По требованиям на разработку программного кода, программист должен предоставить для функционального тестирования стабильно работающее приложение или модуль, без утечек памяти и полностью протестированный. Понятие «полностью протестированный» определяет руководство компании в числовом, процентном значении. То есть, при оформлении требований указано, что область охвата кода 70%. Соответственно, по достижении данной цифры дальнейшие проверки кода можно считать нецелесообразными. Конечно, вопрос области охвата, очень сложный и неоднозначный. Единственным утешением может служить то, что 100% области охвата в крупных проектах не бывает. Из трех рассматриваемых инструментов тестирования PureCoverage можно считать наиболее простым, так как информация им предоставляемая — это просмотр исходного текста приложения, где указано сколько раз исполнилась та или иная строка в приложении.
Запуск приложений

Рисунок 1 показывает действия после выбора «File->Run», в результате которого можно выбрать имя внешнего модуля и аргументы его вызова.
В качестве параметров настройки можно выбрать метод вставки отладочного кода: Line. Наилучший способ вставки отладочного кода. Замеряется время исполнения каждой строки тестируемого приложения. Function. То же самое, что и для «line», но с замером для времени исполнения вызываемых функций. Time. Осуществляет сбор временной информации и преобразует ее в машинные циклы.
По умолчанию Quantify собирает статистическую информацию в модуле тестируемого продукта и во всех внешних библиотеках.

Начало насыщения тестируемого приложения сопровождается появлением окна инструментирования, в котором построчно отображаются все модули, вызываемые основным. Данные модули, как говорилось выше, насыщаются отладочным кодом и помещаются в специальную директорию «cache» по адресу «\rational\quantify\cache». Отметим, что первоначальный запуск инструментирвания процесс длительный, но каждый последующий вызов сокращает общее время ожидания в силу того, что вся необходимая информация уже есть в Кеше.
С точки зрения дисковой емкости, файл (кэшируемый) с отладочной информацией от Quantify вдвое длиннее своего собрата без отладочной информации.
Абстрактные классы
При тестировании ряда методов возникает необходимость построения объекта абстрактного класса. Следует, однако, уточнить, что непосредственно такой объект необходим только в том случае, когда тестируется его метод. В остальных же случаях можно, как правило, обойтись каким-либо объектом наследующего класса.
В первом случае необходимо провести дополнительную работу по определению чисто виртуальных методов. Реализация функциональности каждого метода является трудоемкой задачей, решения которой при проведении тестирования работоспособности хотелось бы избежать. Поэтому компоновщик тестов автоматически генерирует код, в котором определяется класс-наследник абстрактного класса, имеющий те же методы, что и родитель. Чисто виртуальные методы реализованы как заглушки, возвращающие какое-либо значение необходимого типа данных. Это значение получается по общим правилам генерации тестов, то есть может быть либо взято из предопределенного пользователем множества, либо сконструировано компоновщиком.
Впрочем, в ряде случаев такой подход оказывается неприемлемым. Например, если заглушка используется каким-либо другим методом, вызываемым в процессе тестирования. В подобных ситуациях, если это явилось причиной падения теста, необходимо вручную реализовывать чисто виртуальные методы, основываясь, как правило, на исходных кодах одного из существующих наследников тестируемого класса.
Дополнительно, стоит отметить, что язык C++ допускает реализацию по умолчанию абстрактного метода, которая может быть использована при описании наследника. Однако в библиотеке Qt3 такая возможность не используется.
В тех же случаях, когда объект абстрактного класса выступает в качестве параметра, возможны различные варианты его инициализации. Во-первых, можно воспользоваться описанным выше способом и позволить компоновщику сконструировать объект. Во-вторых, можно доопределить абстрактный класс вручную. Однако более предпочтительным является использование объекта какого-либо класса, наследующего данному. Также могут встретиться методы, возвращающие указатель на нужный абстрактный класс. Разумеется, в действительности они возвращают указатель на объект наследующего класса. Результат работы таких методов также можно использовать в качестве значения параметра.
Аналогично, при тестировании невиртуальных методов можно не доопределять абстрактный класс, а воспользоваться экземпляром одного из наследников тестируемого класса.
In-charge конструкторы и деструкторы абстрактного класса протестировать невозможно, поскольку они предназначены для построения или разрушения объекта именно этого класса.
Алгоритм поиска
В данном разделе описан алгоритм поиска различных порядков вызовов методов. Информацию о тестируемой системе алгоритм получает через управляющего (Controller) . В начале каждого удаленного вызова метода выполнение этого вызова блокируется, и управление передается управляющему, который получает информацию о вызываемом методе в виде возможного перехода (Transition) . Будем говорить, что система находится в глобальном состоянии, если в тестируемой системе не остается активных потоков, т.е. все потоки ожидают команды управляющего. Алгоритму поиска информация предоставляется через интерфейс управляющего (рис. 11). Для обнаружения достижения глобального состояния алгоритм вызывает метод управляющего waitForGlobalState. В глобальном состоянии управляющий выдает информацию о глобальном состоянии (метод getStateInfo), включающую в себя список возможных переходов (метод getTransitionList) и сигнал о завершении взаимодействий с тестируемой системой (метод isEndState). Алгоритм поиска может выполнить один из переходов, вызвав метод applyTransition. public interface Controller { public static interface StateInfo { public List<Transition> getTransitionList(); public boolean isEndState(); } public void applyTransition(Transition t); public StateInfo getStateInfo(); public void waitForGlobalState(); }
Рис. 11.Интерфейс управляющего
Как уже упоминалось ранее, в предлагаемом методе тестирования тестовая последовательность строится на основе обхода графа автомата. Переходы автомата представляют собой тестовые воздействия на тестируемую систему. Состояния - обобщенные состояния. Для построения тестовой последовательности от графа автомата требуется сильная связность, т.е. из любого состояния существует путь в любое другое.
Алгоритм поиска различных порядков выполняется для некоторого перехода в автомате в некотором обобщенном состоянии. Каждый раз при выполнении алгоритма система находится в некотором состоянии, соответствующем данному обобщенному состоянию. Для перехода в автомате и состояния системы определим понятие дерева перебора.
Вершинами дерева перебора являются глобальные состояния, а дуги в дереве - это возможные переходы из соответствующих глобальных состояний. Пусть заданы обобщенное состояние S, которому принадлежат состояния системы s1,…, sn, и переход автомата a. Каждому состоянию si и переходу a соответствует дерево перебора ti. Будем говорить, что дерево t1 является поддеревом дерева t2, если для любого пути p1 из t1 существует путь p2 в t2, такой что p1 является префиксом p2. Задача алгоритма поиска - перебрать все пути дерева t, содержащего все пути p, такие что для каждого дерева ti найдется такой путь pi, что p является префиксом pi, то есть t = { p | для всех ti существует pi в ti: p префикс pi }. Отметим, что t является поддеревом любого дерева ti. Такое поддерево будем называть максимальным поддеревом деревьев t1,..., tn. После каждого отката алгоритм сохраняет дерево перебранных путей выполнения. На выходе у алгоритма максимальное поддерево деревьев t1,..., tn, соответствующих состояниям s1,…, sn обобщенного состояния S. Алгоритм управляющего выполняется в несколько этапов. На первом этапе вход алгоритма пуст, и алгоритм начинает выполняться в некотором состоянии. На каждом последующем этапе алгоритм получает на входе пройденное дерево переходов, включающее информацию о последнем пройденном пути. Выполнение на каждом последующем этапе может начинаться в другом состоянии, но принадлежащем тому же обобщенному состоянию. На каждом этапе алгоритм пытается пройти новый путь, принадлежащий деревьям предыдущих этапов. Если же все пути уже пройдены, алгоритм проходит произвольный путь и сообщает о завершении поиска. В конце каждого этапа алгоритм выдает обновленное дерево путей, а также информацию о завершении поиска. Отметим, что алгоритм определяет окончание пути по информации от управляющего. В конце каждого перехода алгоритму известно, завершился ли путь. В тестовых наборах, разработанных по технологии UniTESK, завершение пути соответствует завершению выполнения сценарного метода.
Аннотация.
В статье описывается разработанный автором метод тестирования компонентов, взаимодействующих посредством удаленного вызова методов. Метод позволяет гарантировать, что будут проверены все различные чередования вызовов методов в системе, приводящие к различным результатам. В работе выделены ограничения, при которых такой перебор различных порядков вызовов методов гарантирует корректность системы. Показано, что этим ограничениям удовлетворяют системы, разработанные по технологии Enterprise JavaBeans. В отличие от методов проверки моделей (model checking), в предложенном методе перебор осуществляется не для всей системы целиком, а для отдельных тестовых воздействий, что позволяет существенно сократить область перебора.
Всю информацию, необходимую для выполнения
Всю информацию, необходимую для выполнения перебора различных порядков, алгоритм поиска получает через интерфейс управляющего (Controller). Архитектура, реализующая методы этого интерфейса, показана на . Основные поставщики информации - это EJBServerInterceptor и JVMHook. EJBServerInterceptor работает на сервере приложений и перехватывает удаленные вызовы методов компонентов. Встраивание данного класса происходит с помощью механизма перехватчиков (interceptor) , определенных в EJB 3.0 []. До выполнения метода компонента выполняются перехватчики, определенные для данного типа компонентов. Механизм перехватчиков используется для реализации таких служб, как управление транзакциями и безопасностью. Нам же от этого механизма требуется только блокировка удаленного вызова метода. EJBServerInterceptor через удаленный интерфейс InfoCollector сообщает информацию о вызываемом методе, создавая по описанию метода переход Transition (processTransition) . Вызов при этом блокируется. JVMHook работает на той же JVM, на которой выполняется тест. Этот класс передает информацию о порождаемых в тесте потоках incActiveThreadCount и decActiveThreadCount, а также информацию о завершении теста notifyEndState. Информация о количестве порождаемых потоков необходима для обнаружения начального глобального состояния. Компоненты, разработанные по технологии EJB, обладают рядом важных свойств: В компонентах не создаются новые потоки. Если с системой работает N клиентов, то для блокировки всех взаимодействий в системе достаточно заблокировать N вызовов методов. В каждый момент для экземпляра компонента может выполняться лишь один метод. В зависимости от настроек сервера приложений другие вызовы либо помещаются в очередь, либо завершаются с исключением. Это гарантирует, что данные экземпляра могут одновременно изменяться лишь одним потоком. Кроме того, мы будем требовать выполнения двух дополнительных ограничений, которые не являются обязательными по спецификации EJB, однако выполняются для большинства систем: Обращения к EntityManager происходят внутри транзакций.
Этим обеспечивается атомарность обновления данных в базе данных. Все обращения к разделяемой памяти сосредоточены в EntityManger, т.е. других обращений нет. Последние два ограничения, по сути, требуют, чтобы все обращения к разделяемой памяти были атомарными и контролировались (перехватывались) управляющим. Для систем, удовлетворяющих этим ограничениям, верно, что для любого конкретного состояния системы и воздействий на систему: Существует единственное дерево перебора; Пути дерева перебора описывают все возможные результаты выполнения. Таким образом, гарантируется, что если для воздействий, осуществляемых в переходе автомата, система может работать некорректно (несоответствует спецификации), то соответствующий некорректный результат будет обнаружен. Корректность для всей системы в целом зависит от выбранного разработчиком тестов обобщенного состояния и тестовых воздействий, осуществляемых в сценарных методах. При выполнении ряда гипотез [] можно гарантировать, что вся система корректна. В гипотезах требуется, чтобы система в обобщенных состояниях вела себя "похоже". Важным результатом данной работы является возможность утверждать корректность не только для последовательных, но и распределенных программ.
Дополнительное обеспечение корректности тестового набора
Описанные в предыдущем разделе техники, дополнительные к базовому подходу технологии Azov, позволяют формировать простейшие тесты работоспособности для методов классов библиотеки Qt. Однако, несмотря на то, что процесс генерации тестов полностью автоматизирован, из-за очень большого объема работ неизбежно возникают несоответствия в уточняющей информации, ошибочно внесенные разработчиками, которые могут привести к ошибкам в тестовом наборе. Например, нужный специализированный тип может отсутствовать или вместо нужного может быть указан другой.
Разработчик, разумеется, просматривает и запускает тесты, над которыми он работает в данный момент, на предмет ошибок, но обнаружить их таким способом удается далеко не во всех случаях. В частности, одна из особенностей системы генерации состоит в том, что полный целевой тестовый набор генерируется каждый раз заново, и в зависимости от того, какие уточнения типов были внесены в базу данных, содержимое уже проверенных тестов может меняться.
Возникает необходимость в инструментах, позволяющих выполнять верификацию корректности сгенерированных тестов в указанном в предыдущем разделе смысле, причем в автоматическом режиме.
Достоинства и недостатки подхода
Описанная в предыдущих разделах реализация системы разработки тестов, основанная на технологии Azov, была применена при создании тестового набора для интерфейса библиотеки Qt3. Тестированию подлежало около 10000 операций, поведение которых описывается стандартом LSB. При этом практически во всех случаях удалось построить работоспособные простейшие тесты. На основе полученного опыта можно сделать выводы о преимуществах и недостатках технологии в целом и данной ее реализации.
Технология построения простейших тестов работоспособности действительно позволяет создавать тестовые наборы, решающие поставленную задачу для интерфейсов большого размера. Эффективность ее применения возрастает в тех случаях, когда интерфейс содержит небольшое количество существенно различных типов данных по сравнению с общим числом операций в нем. Это можно увидеть на примере подсистемы работы с базами данных QSql, которая содержит 447 операций из LSB (501 всего), 20 собственных классов и 7 общеупотребительных типов данных. При этом работающие тесты можно построить даже при отсутствии документации на часть операций, что для библиотеки Qt более чем актуально.
В результате расширения базовой методики технологии Azov простейшие тесты удалось создать для приблизительно 99,5% объема входящей в LSB части интерфейса Qt. Лишь около 35 операций не получилось протестировать по причине простоты тестов или критической нехватки документации. При этом в процессе описания ошибок проявилась неожиданная сложность. Дело в том, что при отсутствии сколько-нибудь подробной документации чрезвычайно трудно отличить случаи неверного использования операции от случаев обнаружения настоящих ошибок в ее реализации. Фактически для принятия решения в этих случаях приходится изучать исходный код операций.
В существующем виде технология не предполагает реализацию зависимости между параметрами операции и возвращаемым ею значением. Поэтому в общем случае допустимы только проверки общего вида (например, метод должен вернуть неотрицательное число), которые далеко не всегда можно указать.
Однако в целях повышения аккуратности тестового набора в тех случаях, когда указаны конкретные значения параметров, влияющие на результат, при помощи специализированного типа проверяется равенство результата операции конкретному правильному значению.
Построение автоматических сценариев путем варьирования значений параметров операций может усложнить проверку возвращаемых значений. Вероятно, основные возможности для улучшения тестов заключаются в задании некоторого множества значений для каждого специализированного типа и построении отображений между исходными данными одних и проверками других.
Что касается среды разработки тестов, то она получилась достаточно удобной и простой в использовании. Ее изучение сводится к прочтению нескольких страниц руководства и небольшой самостоятельной практике.
К наиболее существенным недостаткам интерфейса относится отсутствие возможности выполнить какие-либо действия между вызовом целевой операции и проверкой возвращенного ею значения. Такие случаи возникают, когда перед получением результата надо произвести дополнительные действия над объектом целевого воздействия. Приходится добавлять такие вызовы непосредственно в условие проверки правильности результата.
Из-за особенностей механизма неявного наследования в некоторых случаях приходится создавать специализированные типы, в которых тип фактически инициализируемых данных не соответствует уточняемому типу. Подобная ситуация возникает, например, когда требуется использовать в качестве параметра объект класса-наследника вместо базового класса, указанного в сигнатуре операции. При этом корректное приведение типов моделируется компоновщиком неявно на основе эвристики, что запутывает разработчика и усложняет процесс генерации теста.
В том случае, когда для нормальной работы операции необходима явная зависимость между ее параметрами, технология Azov предлагает использование комплексных специализированных типов, которые совместно уточняют сразу несколько параметров. Было реализовано сразу два способа задания таких конструкций.Во-первых, можно явным образом создать особый тип, уточняющий типы сразу нескольких параметров операции. Однако получающаяся конструкция выглядит слишком искусственно, поскольку зависимости между параметрами записываются чаще всего при помощи глобальной функции или переменной. Второй вариант – объединить два обычных специализированных типа путем указания в них ссылок друг на друга Недостатком в данном случае неочевидная зависимость между типами, поскольку используются ссылки на номер параметра операции.
Возникает потребность обобщить модель специализированных типов с учетом особенностей разных языков программирования, по меньшей мере, реализовать более полное явное и неявное наследование, а также формализовать и улучшить использование ссылочных отношений, указывающих как на номер параметра, так и на другой тип данных.
Генерация тестовой последовательности
Для генерации тестовой последовательности в UniTESK используется обход конечных автоматов [,]. Такой способ построения тестовой последовательности хорошо зарекомендовал себя на практике, многие исследователи отмечают высокое качество получаемых тестовых последовательностей [,].
В качестве состояний автомата выбирается модельное состояние или его обобщение. Обобщение необходимо для сокращения количества состояний и представляет собой разбиение состояний на классы эквивалентности, рассматриваемые как равные состояния автомата. Переходами автомата являются вызовы одного или более тестируемых методов.
Как показано в [], одним из удачных обобщенных состояний для деревьев является мультимножество чисел детей. Чтобы получить дерево, в нашем примере мы добавим корневой узел, чтобы все компании без родителей были его детьми. Кроме того, мы разделим детей на активных и неактивных, т.е. обобщенным состоянием будет мультимножество пар (число активных детей, число неактивных детей). На Рис. 8 показаны два различных состояния с добавленным корневым узлом. Обоим состояниям соответствует одинаковое обобщенное состояние {(0,0), (0,0), (1,0), (1,1)}. Такое обобщение позволяет значительно сократить количество состояний автомата и, тем самым, длину тестовой последовательности.

Рис. 8.Обобщение состояний

Рис. 9. Архитектура UniTESK
В процессе тестирования, используя заданное пользователем обобщенное состояние, специальный компонент тестовой системы - обходчик строит тестовую последовательность на основе обхода всех переходов автомата. Информация для построения переходов автомата задается в тестовом сценарии в виде сценарных методов (Рис. 9). В сценарном методе задаются тестовые воздействия на систему. Это могут быть как простые тестовые воздействия, такие как вызовы методов с различными аргументами, так и сложные, такие как порождение нескольких потоков и вызов последовательности методов. Примером сценарного метода является тестовый вариант на рис. 5 с заданной итерацией параметров id и parent по всем компаниям. Будем ссылаться на этот пример как на сценарный метод scenExample.
Этап работы алгоритма
В начале выполнения этапа у алгоритма имеется пройденное дерево переходов Tree. Текущий узел дерева - его корень. Алгоритм ожидает начального глобального состояния. После прихода в глобальное состояние алгоритм выполняет цикл, пока не достигнет конечного состояния. В цикле алгоритм получает список возможных переходов и выполняет действия в зависимости от режима работы.
В режиме поиска алгоритм пытается пройти по новому пути. Алгоритм находит пересечение списка переходов в текущем узле дерева и списка переходов для текущего глобального состояния. Таким образом, находится общее поддерево, т.е. остаются только те переходы, которые имеются для уже пройденного дерева и дерева перебора для конкретного состояния системы. Если в результате пересечения уже пройденный переход не был удален, и поддерево в следующем состоянии дерева по этому переходу имеет не пройденные переходы, то алгоритм проходит по ранее пройденному переходу. Текущая вершина - следующая вершина дерева по пройденному переходу. Иначе, если в текущей вершине имеются непройденные переходы, алгоритм проходит по новому переходу и текущая вершина - новая вершина в дереве. Иначе данное поддерево не имеет непройденных переходов, и тогда алгоритм завершает проход по произвольным переходам в режиме симуляции.
В режиме симуляции алгоритм проходит по произвольному пути. В текущем глобальном состоянии выбирается первый из возможных переходов.
В конце цикла алгоритм ожидает глобального состояния. По приходу в него он обновляет информацию о состоянии и переходит в начало цикла.
По завершению цикла, алгоритм возвращает true, если в дереве остались непройденные переходы, и false иначе.
Конструкторы и деструкторы
В языке C++ каждому конструктору на программном уровне соответствуют два различных конструктора на бинарном уровне: in-charge и not-in-charge, а каждому деструктору – два или три бинарных: in-charge, not-in-charge и, дополнительно для виртуальных классов, – in-charge deleting. Поскольку стандарт LSB описывает поведение системы на бинарном уровне, то тестированию подлежат все вышеперечисленные конструкторы и деструкторы.
In-charge конструкторы и деструкторы вызываются при непосредственной работе с объектом класса. In-charge deleting деструктор используется при удалении объекта виртуального класса из общей памяти. Таким образом, для конструктора и деструктора невиртуального класса компоновщик составляет тест, создающий объект либо в стековой, либо в общей памяти, а затем удаляющий его. В случае виртуального класса область памяти, в которой будет создаваться объект, зависит от тестируемого деструктора.
Not-in-charge конструкторы и деструкторы используются неявно при работе с объектом какого-либо класса, наследующего данному. Поэтому в тесте описывается наследник, и путем создания и уничтожения объекта полученного типа опосредованно выполняется вызов этих конструкторов и деструкторов.
Контроль корректности наложенных ограничений
Дополнительные проверки, описанные в разделе 3.1, позволяют выявлять ошибки только в тех последовательностях инициализации данных, которые формируются самим компоновщиком. Однако уточнения, вносимые разработчиком, также могут быть некорректными. Обычно, код, генерируемый на основе специализированных типов, синтаксически верен и выполняет возложенные на него функции, поэтому основным источником ошибок является указание неверного специализированного типа для параметра операции.
Проверка наложенных ограничений выполняется статически при помощи дополнительного инструмента, реализованного в инструменте разработчика, который просматривает базу данных с уточненной информацией о тестируемых операциях на предмет потенциально опасных случаев. Дополнительные возможности обеспечиваются особыми правилами для наименований специализированных типов, которые позволяют классифицировать их по назначению, например, тип, проверяющий возвращаемое значение и имеющий префикс R_, не должен уточнять неизменяемый параметр метода.
В частности специализированный тип, указанный для возвращаемого операцией значения, должен содержать некоторую проверку этого значения, а также иметь соответствующее название. Обратно, уточнение для параметров, которые не могут быть изменены в результате вызова целевой операции, не должно содержать проверки возвращаемого значения.
Не характерно наличие специализированных типов, уточняющих объекты, для статических методов, конструкторов и деструкторов классов, хотя иногда они необходимы для того, чтобы правильно проинициализировать среду исполнения теста. Также проверяется наличие общих специализированных типов, то есть таких, которые используются по умолчанию, для простейших типов данных, таких как int, bool, char и т.д., поскольку это приводит к массовым нарушениям ранее заданных ограничений на возвращаемые значения методов. Специализированные типы для типов более сложной организации чаще описывают правильную последовательность инициализации объекта, а не конкретное его значение, поэтому для них такая проверка не требуется.
Дополнительно имеется возможность поиска дублирующихся или очень похожих специализированных типов, у которых совпадают все поля кроме названия и быть может исходного типа, а также типов, для которых не описано никаких ограничений. Наличие таких типов иногда допустимо, поскольку они позволяют изменять тип конструируемого объекта. Это позволяет подавать в качестве параметра объект типа наследника вместо родителя, при этом, не определяя вручную инициализирующую последовательность.
Для защиты системы от случайных ошибок вводится понятие одноразовых специализированных типов. Такой тип, как правило, содержит уникальную проверку или инициализацию, применимую только к одной определенной операции и более нигде не используемую. Как следует из его названия, он может использоваться лишь однажды, и система не позволяет другим разработчиком применить его по ошибке, попутно облегчая им поиск более подходящих специализированных типов. Аналогично, одноразовыми специализированными типами не может пользоваться и компоновщик при инициализации параметров других операции.
Литература
Р. Зыбин, В. Кулямин, А. Пономаренко, В. Рубанов, Е. Чернов. Технология Azov автоматизации массового создания тестов работоспособности. Опубликовано в этом же сборнике. . . . А. Пономаренко, Е. Чернов. Алгоритм генерации тестов работоспособности на основе расширенной базы данных LSB. Опубликовано в этом же сборнике.
| 1.обратно | Szyperski C. Component Software Beyond Object-Oriented Programming. Boston, MA: Addison-Wesley and ACM Press, 1998. |
| 2.обратно | Документация по Java RMI. |
| 3.обратно | Таненбаум Э., М. ван Стеен. Распределенные системы. Принципы и парадигмы. СПб.: Питер, 2003. |
| 4.обратно | Bertrand Meyer. Applying 'Design by Contract'. IEEE Computer, vol. 25, No. 10, October 1992, pp. 40-51. |
| 5.обратно | O. Tkachuk, M. B. Dwyer and C. S. Pasareanu. Automated Environment Generation for Software Model Checking. Proceedings of the Eighteenth IEEE International Conference on Automated Software Engineering, 2003. |
| 6.обратно | P. Godefroid. Partial-Order Methods for the Verification of Concurrent Systems: An Approach to the State-Explosion Problem. Secaucus, NJ, USA: Springer-Verlag, 1996. |
| 7.обратно | P. Godefroid. Model Checking for Programming Languages using VeriSoft. Proceedings of the 24th ACM Symposium on Principles of Programming Languages. ACM Press, pp. 174-186, January 1997. |
| 8.обратно | G. Brat, K. Havelund, S.-J. Park, and W. Visser. Model Checking Programs. In IEEE International Conference on Automated Software Engineering (ASE), pp. 3-12, September 2000. |
| 9.обратно | И.Б. Бурдонов, А.С. Косачев, В.В. Кулямин. Применение конечных автоматов для тестирования программ. Программирование, 26(2):61-73, 2000. |
| 10.обратно | D. Lee and M. Yannakakis. Principles and methods of testing finite state machines - a survey. Proceedings of the IEEE, vol. 84, pp. 1090-1123, Berlin, August 1996. |
| 11.обратно | R. Monson-Haefel, B. Burke. Enterprise JavaBeans 3.0, Fifth Edition. Sebastopol, CA: O'Reilly, 2006 |
| 12.обратно | В.В. Кулямин, А.К. Петренко, А.С. Косачев, И.Б. Бурдонов. Подход UniTESK к разработке тестов. Программирование, 29(6): 25-43, 2003. |
| 13.обратно | I. Bourdonov, A. Kossatchev, V. Kuliamin, and A. Petrenko. UniTesK Test Suite Architecture. Proceedings of FME 2002. LNCS 2391, pp. 77-88, Springer-Verlag, 2002. |
| 14.обратно | Gary T. Leavens, Albert L. Baker, and Clyde Ruby. Preliminary Design of JML: A Behavioral Interface Specification Language for Java. ACM SIGSOFT Software Engineering Notes, 31(3):1-38, March 2006. |
| 15.обратно | Хорошилов А.В. Спецификация и тестирование компонентов с асинхронным интерфейсом. Диссертация на соискание ученой степени кандидата физико-математических наук. Москва: ИСП РАН, 2006. |
| 16.обратно | И. Б. Бурдонов, А. С. Косачев, В. В. Кулямин. Неизбыточные алгоритмы обхода ориентированных графов. Детерминированный случай. Программирование, 29(5):59-69, 2003. |
| 17.обратно | И. Б. Бурдонов, А. С. Косачев, В. В. Кулямин. Неизбыточные алгоритмы обхода ориентированных графов. Недетерминированный случай. Программирование, 30(1):2-17, 2004. |
| 18.обратно | H. Robinson. Intelligent Test Automation. Software Testing and Quality Engineering, September/October 2000, pp. 24-32. |
| 19.обратно | W. Grieskamp, Y. Gurevich, W. Schulte, and M. Veanes. Generating Finite State Machines from Abstract State Machines. ISSTA 2002, International Symposium on Software Testing and Analysis, July 2002. |
| 20.обратно | В.С. Мутилин. Паттерны проектирования тестовых сценариев. Труды ИСП РАН, 9: 97-128, 2006. |
| 21.обратно | EJB 3.0 Specification, JSR 220 FR. |
| 1(к тексту) | Работа частично поддержана грантом РФФИ 05-01-00999. |
Методика построения корректных тестов
Основной задачей рассматриваемой технологии является построение корректного теста работоспособности для каждой операции, входящей в тестируемый интерфейс.
Под корректным понимается такой тест, который обеспечивает правильную последовательность инициализации параметров целевой операции, инициализацию параметров среды исполнения, содержит непосредственный вызов целевой операции, а также освобождает по завершении задействованные ресурсы и возвращает систему в исходное состояние. Следует также отметить, что в тесте должно проверятся, выполнился ли вызов тестируемой операции успешно или наблюдается отклонение от ожидаемого поведения.
Вопросы, касающиеся инициализации и финализации (освобождение захваченных тестом ресурсов) тестовых данных относятся скорее к технологии в целом, и освещены в статье [1]. Здесь же речь пойдет об особенностях реализации общего подхода технологии Azov при использовании языка C++ и для тестирования библиотеки Qt3.
Описанные ниже особенности обеспечиваются функциональностью инструмента-компоновщика тестов, генерирующего тесты по базе данных с уточненной информацией об интерфейсных операциях [1,5], и разработчику, как правило, не приходится о них беспокоиться.
Методы, не входящие в программный интерфейс приложения
Определяя набор интерфейсных операций на бинарном уровне, стандарт LSB в некоторых случаях включает в себя операции, не являющиеся частью программного интерфейса (Application Programming Interface, API) описываемых им библиотек. Однако, при тестировании работоспособности необходимо, по возможности, протестировать даже подобные скрытые операции.
В рамках Qt3 существует ряд классов, предназначенных исключительно для использования внутри самой этой библиотеки. Описания таких классов находятся либо в заголовочных файлах, предназначенных только для сборки библиотеки, либо и вовсе в исходных кодах.
Одним из возможных подходов к тестированию методов таких классов является построение теста для метода, входящего в API, в процессе работы которого вызывается скрытый метод. Однако данный способ имеет большое количество недостатков. Во-первых, требуется весьма трудоемкое исследование того, какие методы могут быть использованы и какие значения их параметров приводят к вызову тестируемого метода. Во-вторых, отсутствует непосредственный контроль над параметрами тестового воздействия, а опосредованный контроль может быть слишком труден или даже вовсе невозможен. И, наконец, в-третьих, достаточно сложно определить, отработал ли тестируемый метод должным образом.
Учитывая все сказанное, на практике используется существенно более простое решение. Найденное описание класса выносится в отдельный заголовочный файл, который поставляется вместе с тестом. Вообще говоря, вынесение описания в отдельный файл необходимо только для классов, использующих предоставляемые Qt расширения языка C++, поскольку прекомпилятор Meta Object Compiler, который генерирует на их основе определения на чистом C++, обрабатывает только файлы заголовочного типа. Однако в целях стандартизации процесса подготовки необходимых для создания теста данных различий между классами, определенными на чистом языке, и классами, использующими расширения, не делается. Теперь, при подключении этого заголовочного файла к тесту, компилятор будет считать исследуемые методы частью API, и к ним можно обращаться напрямую, как и в общем случае. Данный подход также требует некоторого количества ручной работы по поиску объявления класса, но ее объем не идет ни в какое сравнение с предыдущим вариантом.
Также в состав LSB входит множество так называемых thunk методов, которые конструируются компилятором и служат для обращения к виртуальным методам, декларированным в классах-предках. В силу их сугубо вспомогательной природы и отсутствия документации по ним такие операции считаются не подлежащими тестированию и исключаются из дальнейшего рассмотрения.
Описание системы
Рассмотрим пример системы, построенной из компонентов, которые взаимодействуют посредством удаленного вызова методов. Система написана на основе Enterprise Java Beans 3.0 []. Система содержит один сеансовый компонент с состоянием (stateful session bean) CompanyManagerBean, реализующий удаленный интерфейс CompanyManager, и один класс сущность (entity) Company (Рис. 1).

Рис. 1.Система управления компаниями
Компонент CompanyManagerBean предоставляет интерфейс работы с иерархиями компаний. У каждой компании имеются уникальный идентификатор, имя, могут иметься активный/неактивный статус и родительская компания. Через компонент CompanyManagerBean можно редактировать компании. Клиент запрашивает экземпляр компонента, затем устанавливает компанию, которую собирается редактировать (editCompany), блокируя доступ к данной компании другим экземплярам, редактирует компанию, изменяя статус компании (setActive, setInactive) и родительскую компанию (setParent, removeParent), затем освобождает компанию (freeCompany), делая ее доступной для редактирования другим экземплярам.
На иерархию компаний накладываются следующие ограничения: Компания с активным статусом не может иметь родительскую компанию с неактивным статусом; Иерархия компаний более четырех уровней (глубины) недопустима.
Таким образом, данные ограничения запрещают иерархии, показанные на Рис. 2: (а) - активная компания C2 имеет неактивного родителя C1, (б) - иерархия компаний имеет более четырех уровней.

Рис. 2. Примеры запрещенных иерархий
Реализация методов компонента CompanyManagerBean состоит в предварительной проверке ограничений и, в случае успеха, изменении состояния компании и сохранении результатов изменения в базе данных. Для примера рассмотрим реализации методов setInactive и setParent. Метод setInactive устанавливает статус компании неактивным (Рис. 3). Предварительно метод проверяет, что все дочерние компании имеют неактивный статус. Проверка производится во вспомогательном методе isChildrenInactive, в котором происходит поисковый запрос к базе данных с выбором всех дочерних компаний, т.е.
компаний, у которых родительская компания совпадает с данной. Далее, если все дочерние компании неактивны, то возвращается true, статус компании меняется на неактивный, и изменения сохраняются в базе данных (enityManager.merge), иначе возвращается false, и статус компании не изменяется. Обращения к базе данных производятся через специальный компонент EntityManager, который предоставляет методы добавления (persist), изменения (merge), поиска (find) записей в базе данных. Отметим, что для корректности результатов данной работы требуется, чтобы обращения компонентов к общим данным, хранящимся в базе данных, являлись атомарными, т.е. одновременно может выполняться запрос не более чем от одного компонента. В данном примере это требование обеспечивается механизмом транзакций EJB таким образом, что обращения к EntityManager включаются в контекст транзакций.
public boolean setInactive() { if (isChildrenInactive()) { company.setActive(false); entityManager.merge(company); return true; } else { return false;
Рис. 3. Реализация метода setInactive
public boolean setParent(int id) { Company newParent = entityManager.find(Company.class, id); if (newParent == null) throw new NoResultException();
if (newParent.getActive() !company.getActive()) { company.setParent(newParent); entityManager.merge(company); return true; } else { return false; } }
Рис. 4. Реализация метода setParent
Метод setParent устанавливает родительскую компанию (Рис. 4). Требуется, чтобы существовала компания с идентификатором, указанным в качестве аргумента вызова этого метода. Метод проверяет, что для активной компании нельзя установить неактивного родителя. Т.е. если родитель активный или компания неактивная, то устанавливается новый родитель, и изменения сохраняются в базе данных; иначе изменения не происходят. Рассмотрим один из возможных тестов для компонента CompanyManagerBean. В тесте предполагается, что в начальном состоянии имеются две активные компании без родителей.
Имена компаний C1, C2, а идентификаторы 1, 2 соответственно. Тест состоит из двух потоков, выполняющихся одновременно. Оба потока выполняют метод testCase, показанный на Рис. 5, с разными аргументамии. Первый выполняет метод с аргументами 0, 1, 2 а второй - с аргументами 1, 2. Таким образом, первый поток захватывает компанию C1 на редактирование и, в случае успеха, вызывает метод setParent с аргументов - идентификатором компании C2 (будем писать C1.setParent(C2)), затем освобождает компанию. Второй захватывает компанию C2 и, в случае успеха, вызывает метод setInactive (будем писать C2.setInactive()), затем освобождает компанию. Для создания экземпляра компонента CompanyManagerBean используется вспомогательный метод getCompanyManager.
public static void testCase(int num, int id, int parent) throws Exception { CompanyManager manager = getCompanyManager(); manager.editCompany(id); try { if (num==0) { manager.setParent(parent); } else { manager.setInactive(); } } finally { manager.freeCompany(); } }
Рис. 5. Тестовый вариант
Результаты выполнения данного теста зависят от того, в какой последовательности выполнялись удаленные вызовы методов (рис. 6). Если сначала полностью выполнится первый поток, а затем второй, то в результате для компании C1 будет установлен родитель C2, а статус компании C2 по-прежнему останется активным, так как метод isChildrenInactive обнаружит у C1 активного ребенка C2. Если сначала выполнится второй поток, а затем первый, то в результате статус компании C2 станет неактивным, но родитель для C1 установлен не будет, так как в момент проверки статус родительской компании C2 будет неактивным. Однако возможен еще и третий вариант, когда проверки в методах setParent и setInactive выполняются до того, как происходят изменения в базе данных, т.е. выполняются методы entityManager.merge. Например, пусть вызовы выполняются в следующей последовательности:
t1.editCompany; t1.setParent; s1.find; t2.editCompany; t2.setInactive; s2.find; s1.merge; s2.merge; t1.freeCompany; t2.freeCompany
где префиксы t1, t2 означают, что вызовы происходили из первого и второго потоков соответственно, а s1, s2 - соответствующие экземпляры CompanyManagerBean.Результатом такого выполнения будет установка для C1 родительской компании C2, а для C2 - установка неактивного статуса, что нарушает первое ограничение.

Оптимизация разработки тестов
Ключевым достоинством технологии Azov является возможность достичь чрезвычайно высокой производительности при разработке тестового набора. Затраты на создание одного теста уменьшаются при разработке тестов для интерфейсов большого размера (свыше 1000 операций). Основные трудозатраты приходятся на задачи, выполняемые разработчиком вручную, а именно изучение стандарта, формирование необходимых специализированных типов и отладка полученных тестов.
Учитывая огромное количество подлежащих тестированию операций, даже небольшое уменьшение времени разработки теста в среднем приводит к значительному выигрышу для всего тестового набора в целом. Поэтому среда разработки должна иметь гибкий и удобный интерфейс, а также обеспечивать широкие возможности переиспользования уже созданных специализированных типов данных.
В данной статье рассматривается задача
Аннотация. В данной статье рассматривается задача адаптации технологии Azov для построения тестового набора, проверяющего работоспособность интерфейса библиотеки Qt3 для разработки приложений с графическим пользовательским интерфейсом. Приводится уточнение базовой методики, которое позволяет формировать корректные тесты с учетом специфики языка C++ и дополнительных возможностей тестируемой библиотеки. Вводятся расширения технологии, позволяющие ускорить работу над созданием тестового набора. Полученная методика показывает высокую эффективность при разработке простейших тестов работоспособности для сложных интерфейсов, содержащих большое количество методов и функций. Отдельно обсуждаются достоинства и недостатки технологии, выявленные в процессе ее реализации, а также указываются возможные направления ее дальнейшего развития.
Поиск различных порядков
Итерация параметров в сценарном методе происходит с помощью итерационных переменных. Итерационые переменные отличаются от обычных переменных тем, что значения этих переменных вместе с именем сценарного метода определяют стимул автомата. Количество переходов по заданному стимулу в заданном обобщенном состоянии автомата зависит от результатов вызова сценарного метода с заданными значениями итерационных переменных. Если вызов сценарного метода приводит всегда к одному и тому же результату, то автомат имеет единственный переход по заданному стимулу; иначе переходов столько, сколько возможно различных результатов. Для того чтобы получить различные результаты вызова сценарного метода, требуется перебрать различные порядки событий в системе.
В рассмотренном примере сценарного метода scenExample с использованием теста testCase возможны три различных результата, соответствующих вызову этого метода с итерационными переменными id=1, parent=2 в начальном состоянии {(0,0), (0,0), (0,2)}: {(0,0), (0,0), (1,1)}, {(0,0), (1,0), (1,0)}, {(0,0), (0,1), (1,0)}.
Рассмотрим следующий пример. Предположим, что для рассмотренного примера иерархии компаний написан сценарий, в котором в качестве обобщенного состояния выбрано описанное выше мультимножество. В сценарии, во-первых, заданы сценарные методы для методов интерфейса CompanyManager. Данные сценарные методы позволяют получить разнообразные состояния иерархии: широкие, длинные, с разными конфигурациями активных и неактивных компаний. Эти методы также обеспечивают сильную связность графа автомата. Во-вторых, предположим, что имеется сценарный метод scenExample, описанный на основе метода testCase. Предположим, что обходчик в ходе построения тестовой последовательности попадает в состояние, соответствующее обобщенному состоянию {(0,0), (0,0), (1,1)}, в котором компания C1 - неактивная, а C2 - активная. В этом состоянии обходчик выполняет переход, соответствующий сценарному методу scenExample с итерационными переменными id=1, parent=2.
На Рис. 10 показаны возможные пути выполнения без учета вызовов editCompany и freeCompany. Кроме того, на рисунке пунктиром показаны вызовы, перебора которых можно избежать за счет использования методов редукции частичных порядков. В соответствии с постановкой задачи метод поиска не имеет возможности отката в предыдущее состояние, поэтому каждый раз метод поиска проходит один из путей целиком и запоминает пройденное дерево. После этого обходчик продолжает обход автомата, и если метод сообщил, что в состоянии {(0,0), (0,0), (1,1)} есть неперебранные порядки, обходчик возвращается в это состояние. При этом от обходчика требуется лишь то, чтобы каждый переход был пройден столько раз, сколько это нужно методу поиска порядков. Никаких других изменений для обходчика не требуется.

Приведение типов и наследование
Специализированный тип фактически является композицией исходного типа данных и некоторого набора ограничений, то есть, по сути, состоит из достаточно независимых компонент. Эту особенность можно использовать для гибкого формирования новых специализированных типов из уже имеющихся в системе.
В текущей реализации специализированный тип имеет шесть атрибутов: исходный тип, к которому применяются ограничения, значение типа, блоки дополнительной инициализации и финализации параметра, блок проверки требований и блок вспомогательного кода. Доступ к объекту осуществляется через шаблон, разворачиваемый впоследствии компоновщиком, поэтому все атрибуты практически независимы, за исключением того, что при работе с параметром предполагается, что его тип соответствует исходному типу данных.
В системе реализовано однократное наследование специализированных типов. Каждому типу может быть сопоставлен один родитель. Если тип-наследник не содержит описания какого-либо из блоков, то используется описание этого блока у его непосредственного предка. Однако если последний в свою очередь заимствует соответствующее описание у своего предка, то в результате блок наследника окажется пустым. При таком подходе создавать цепочки наследования не имеет практического смысла, и в процессе разработки это, как правило, и не требуется. С другой стороны весьма полезно иметь некий базовый специализированный тип, обеспечивающий основную инициализацию, а уже на его основе строить типы, проверяющие требования. Тогда, при необходимости изменить инициализирующий код, это нужно будет сделать только в одном месте.
Существующий механизм полезно в дальнейшем дополнить наследованием от двух родителей с одинаковым исходным типом одновременно. От одного родителя можно будет взять инициализирующий код, от второго – проверку возвращаемого значения, а в самом наследнике определить специфичную для тестируемой операции инициализацию и финализацию. Это позволит несколько сократить время разработки теста, а также изменять меньшее количество специализированных типов при необходимости внесения поправок.
Специализированные типы для производных типов, таких как указатели, ссылки, синонимы (typedef), константы (const), а также конструкции более сложной структуры, можно создавать автоматически с помощью механизма неявного наследования. Производные одного типа образуют класс эквивалентности в том смысле, что ограничения специализированного типа для одного из них могут быть применены к любому другому типу из этого множества. Дополнительные поправки в цепочку инициализации параметра автоматически вносятся компоновщиком при сборке теста. С точки зрения пользователя системы это выглядит так, как будто для всех параметров, имеющих типы из одного класса эквивалентности, существуют специализированные типы одинакового назначения.
В качестве направления дальнейшего развития этого механизма можно предложить заимствование иерархии наследования самого языка C++. То есть, например, специализированный тип, уточняющий объект класса-наследника, может использоваться при инициализации параметра, имеющего тип класса-родителя.
Также полезно ввести неявное наследование для произвольных определяемых пользователем групп классов. В частности, целесообразно переиспользовать специализированные типы данных для классов, имеющих похожие методы, например, классов-наследников одного и того же родителя, немного по-разному реализующих сходную функциональность.
Проверки, добавляемые автоматически
Компоновщик тестов может гарантировать только синтаксическую корректность составляемого им кода, основываясь при этом на знании сигнатур операций. Для построения параметров, которые должны приводить к сценарию нормального использования целевой операции, этой информации недостаточно, и разработчик должен пополнять ее, внося соответствующие уточнения в виде специализированных типов. Если же при автоматической инициализации параметра был использован неподходящий специализированный тип или нужный специализированный тип не был описан на момент сборки, то полученный тест может не достигать поставленных целей.
Полностью исключить ошибочные ситуации автоматически невозможно, однако проверка промежуточных условий корректности везде, где это возможно, повышает уверенность в корректности теста в целом.
Требование, проверка которого вставляется в тесты компоновщиком по умолчанию, заключается в неравенстве нулю указателей на объекты, расположенные в общей памяти. Фактически, все возвращаемые методами при инициализации параметров указатели на объекты проходят такую проверку.
Более конкретные, и потому возможно более полезные, требования задаются разработчиками для каждого типа данных в отдельности и оформляются в виде так называемых общих специализированных типов. В качестве примера таких требований можно привести проверку свойств isNull() и isValid(), которые имеются у большого числа классов и характеризуют полноценность объекта.
Недостатком этого подхода является необходимость применения дополнительного специализированного типа там, где автоматически внесенное ограничение может быть нарушено из разумных соображений.
Разбиение на группы и порядок выполнения работ
В процессе разработки пользователь может столкнуться с необходимостью проинициализировать параметр типа, для которого еще никто не составил подходящих специализированных типов. В этих случаях разработчику требуется отвлечься на время от текущей задачи, изучить соответствующий раздел стандарта и описать нужные уточнения для типа данных или подождать, пока другой разработчик сделает это, что зачастую занимает весьма значительное время. При разработке тестов для большого числа операции постоянное отвлечение на другие задачи сильно замедляет создание тестов, поскольку разработчику придется позже восстанавливать свои знания об отложенной на время операции.
Для того чтобы минимизировать время на переключение контекста в процессе разработки, используется инструмент построения расписания работ. Множество операций, для которых создается тестовый набор, разбивается на группы в соответствии с их назначением, что позволяет разработчикам изучать один и тот же раздел стандарта сразу для целой группы функций или классов. Затем для каждой группы и для каждой операции внутри группы определяется приоритет, согласно которому следует вести разработку. Применительно к C++ удобнее оперировать не в терминах отдельных операций, а в терминах целых классов.
Внутри группы каждому классу ставится в соответствие вес, равный разности между количеством классов этой же группы, имеющих методы, в которых этот класс выступает в качестве параметра, и количеством классов группы, которые используются в его методах. Чем больше вес класс, тем раньше следует создать уточняющего его специализированные типы. На практике это означает, что более высокий приоритет имеют низкоуровневые и вспомогательные классы, которые затем используются более сложными.
На уровне групп веса рассчитываются таким же образом, с учетом всех входящих в группу классов. Однако здесь приоритеты имеют более общий смысл и отражают то, насколько часто в тестируемом интерфейсе используется та или иная подсистема.
Сигналы и слоты
В библиотеке Qt передача сообщений между объектами приложения осуществляется посредством механизма сигналов и слотов. Вызов метода-сигнала объекта отправляет в основной цикл обработки сообщение, содержащее параметры этого сигнала, которое перехватывается и обрабатывается методом-слотом другого или того же самого объекта. Канал связи между методами определяется макросом connect.
Функциональность сигнала заключается в передаче слоту параметров через сообщение, неявно включая указатель на передающий объект, который может быть получен при помощи вызова QObject::sender() в теле слота. Именно ее и нужно проверять в процессе тестирования. В тесте формируется дополнительный объект, имеющий метод-слот с такими же, как и у сигнала, параметрами. Реализация этого метода проверяет значения пришедших параметров на эквивалентность посланным, а также неравенство нулю указателя на передающий сообщение объект, и выполняет выход из приложения. Таким образом, если сообщение не дошло до слота, то приложение не выйдет из основного цикла и будет завершено аварийно.
Слот представляет собой обычный метод, работающий с переданными ему параметрами, но может дополнительно обращаться к объекту, пославшему сообщение, посредством глобальной переменной. Поэтому не все реализации методов-слотов будут работать вне контекста передачи сообщения. Для тестируемого слота подбирается существующий в системе подходящий сигнал с таким же, как и у слота, набором параметров. В тесте конструируется объект, имеющий этот метод-сигнал, который при помощи макроса связывается со слотом. Тестовое воздействие производится путем вызова сигнала с проинициализированными параметрами.
Спецификация
Для решения задачи спецификации, генерации тестовых данных и оценки покрытия в качестве основы мы будем использовать технологию UniTESK [,]. В UniTESK проверка корректности производится на основе задания пред- и постусловий функций, а также инвариантов [,]. Дополнительно для обеспечения возможности спецификации параллельных и распределенных систем введено понятие отложенной реакции [], с помощью которых удается моделировать внутренний недетерминизм в системе. Для рассмотренного примера приведенные ограничения на систему могут быть сформулированы в виде инвариантов на состояние (Рис. 7). В модельном состоянии theCompanies хранятся описания компаний: статус компании и информация о родителях. Инвариант Rule1_InactiveParent проверяет первое ограничение, а Rule2_Level4Hierachy - второе. invariant Rule1_InactiveParent() { for (Company company: theCompanies) { if (company.isActive()) { if (company.parent!=null && !company.parent.isActive()) return false; } } return true; } invariant Rule2_Level4Hierarchy() { for (Company company: theCompanies) { if (company.computeLevel()>4) return false; } return true; }
Рис. 7. Спецификация ограничений
Среда исполнения тестируемого метода
Одним из ключевых компонентов приложения, написанного с использованием библиотеки Qt, является объект класса QApplication. Он содержит основной цикл обработки сообщений и служит для глобальной инициализации и финализации программы, в частности, если требуется, обеспечивает приложению доступ к графической подсистеме, задавая активный дисплей, визуальный и цветовой контексты. Также класс QApplication позволяет обращаться к таким параметрам системы как шрифты, палитра, интервал двойного нажатия, и параметрам, переданным приложению. Каждое приложение с графическим интерфейсом, использующее Qt, должно иметь лишь один объект этого класса.
Система Qt не позволяет создавать объекты классов, осуществляющих вывод какого-либо изображения, до тех пор, пока не проинициализирован объект QApplication. Существует также ряд методов, функциональность которых проявляется только после того, как программа начнет обрабатывать события, происходящие в ней самой и в операционной системе.
Поэтому компоновщик добавляет в начало каждого теста конструктор класса QApplication, а в конце теста вызывает метод exec полученного объекта, который запускает цикл обработки сообщений данного приложения.
Из этого правила существует несколько исключений. Поскольку в приложении может существовать лишь один объект класса QApplication, то при тестировании его конструкторов и деструкторов попытка создать дополнительный объект приведет к падению теста. Класс QEventLoop описывает основной цикл обработки сообщений, поэтому его объект должен быть сконструирован до объекта QApplication. Также, статический метод самого класса QApplication setColorSpec() влияет на инициализацию графической подсистемы и должен вызываться до начала ее работы, а значит до того, как будет вызван конструктор класса QApplication.
Разумеется, многие классы, не затрагивающие непосредственно графический интерфейс, могут работать и без привлечения объекта QApplication, поэтому дополнительная инициализация и вход в цикл обработки сообщений для их тестирования излишни. Однако библиотека Qt преимущественно используется для создания приложений, имеющих графический интерфейс, поэтому подобная избыточность, напротив, приближает среду, в которой вызывается тестируемая операция, к реальной.
Структуры данных алгоритма
Структуры данных, используемые алгоритмом, показаны на Рис. 12. Каждый переход Transition обязательно включает идентификатор. Дерево путей Tree ссылается на корневой узел Node, который включает упорядоченный список переходов transitions, индекс последнего выполненного перехода в этом списке lastIndex и список дочерних вершин children. В начале списка transitions идут выполненные переходы до lastIndex, далее идут невыполненные переходы. Список children содержит дочерние вершины, соответствующие переходам transitions, в том же порядке, размер списка - lastIndex+1. public class Tree { public Node rootNode = new Node(); } public class Node { List<Transition> transitions; int lastIndex = -1; List<Node> children;//size=lastIndex+1 boolean isEndState = false; } public class Transition { public int id; }
Рис. 12. Структуры данных алгоритма поиска
Тестирование
В.В.Кулямин, ИСП РАН
Дэвид Лордж Парнас
Перевод: Виктор Кулямин
, , Труды Института системного программирования РАН
, , , Труды Института системного программирования РАН
, , , Труды Института системного программирования РАН
, , Труды Института системного программирования РАН
, Труды Института системного программирования РАН
, , Труды Института системного программирования РАН
, Труды Института системного программирования РАН
, Труды Института системного программирования РАН
, Труды Института системного программирования РАН
, , , Труды Института системного программирования РАН
, , , , , Труды Института системного программирования РАН
Зацепин Д.В., Шнитман В.З., Труды Института системного программирования РАН
С.В. Зеленов, Н.В. Пакулин, Труды Института системного программирования РАН
, Труды Института системного программирования РАН
Гингина В.В., Зеленов С.В., Зеленова С.А., Труды Института системного программирования РАН
, Труды Института системного программирования РАН
Д.Ю. Кичигин, Труды Института системного программирования РАН
К.А. Власов, А.С. Смачёв, Труды Института системного программирования РАН
, Труды Института системного программирования РАН
А. С. Камкин, Труды Института системного программирования РАН
, Российско-Армянский (Славянский) государственный университет, Ереван, Армения
Труды Института системного программирования РАН
Задачи верификации ОС Linux в контексте ее использования в государственном секторе
, , Труды Института системного программирования РАН
, Труды Института системного программирования РАН
, Труды Института системного программирования РАН
А.В. Демаков, С.В. Зеленов, С.А. Зеленова, Труды Института системного программирования РАН
, Труды Института системного программирования РАН
С.В. Зеленов, Д.В. Силаков, Труды Института системного программирования РАН
Препринт Института Системного Программирования РАН
, , ,
, ,
, ,
Сергей Мартыненко
Сергей Белов, менеджер проекта компании StarSoft Development Labs
, #21/2005
,
С.В. Зеленов, С.А. Зеленова
Труды Института Системного Программирования РАН
Калинов А.Я., Косачёв А.С., Посыпкин М.А., Соколов А.А.,
Труды Института Системного Программирования РАН.
Вячеслав Панкратов, Software-testing.ru
А.А. Сортов, А.В. Хорошилов.
Труды Института Системного Программирования РАН
В. В. Кулямин, Труды
Новичков Александр, Ематин Виктор, Закис Алексей, Шкляева Наталья, Подоляк Ольга,
, автор проекта "Тестер",
, автор проекта "".
Статья была опубликована в Журнале для профессиональных программистов "argc & argv", Выпуск № 6 (51/2003)
А.В. Баранцев, И.Б. Бурдонов, А.В. Демаков, С.В. Зеленов, А.С. Косачев, В.В. Кулямин, В.А. Омельченко, Н.В. Пакулин, А.К. Петренко, А.В. Хорошилов
Труды
Александр Петренко, Елена Бритвина, Сергей Грошев, Александр Монахов, Ольга Петренко,
, , , ,
В статье предлагается концепция автоматизированного построения тестовых наборов и тестовых оракулов для тестирования оптимизаторов. Используется подход, основанный на генерации тестов из моделей. Основные идеи модельного подхода заключаются в следующем: 1) модельный язык неявно разбивает множество программ целевого языка на классы эквивалентности; 2) критерий тестового покрытия формулируется в терминах модельного языка; 3) в соответствии с выбранным критерием генерируется набор тестов. В работе описывается схема построения тестового оракула, который проверяет сохранение семантики программы после ее оптимизации.
, , , ,
В статье представлен опыт разработки тестового набора для реализации протокола IPv6. Для разработки тестового набора использовался метод разработки тестовых наборов на основе формальных спецификаций UniTesK, развиваемый в Институте системного программирования РАН. В качестве объекта тестирования была выбрана реализация IPv6 от Microsoft Research. В статье подробно описывается устройство полученного тестового набора и обсуждаются результаты проекта.
Виктор Ематин, Борис Позин (),
В статье рассказывается о средстве управления изменениями Rational ClearQuest, которое позволяет совместно с инструментами тестирования тщательно документировать встречающиеся при испытаниях дефекты.
В статье рассказывается о программном продукте ClearQuest от компании Rational, который помогает разработчикам и тестировщикам находить и документировать ошибки в разрабатываемом ПО.
Удобство и функциональность интерфейса
Инструмент разработчика тестов в первую очередь предназначен для доступа к базе данных с дополнительной информацией о тестируемых операциях, а именно позволяет создавать и редактировать специализированные типы, просматривать состояние работ в целом и для каждой операции в частности, а также собирать статистические данные. Скорость разработки тестового набора существенно зависит от удобства этого инструмента и его функций, позволяющих сократить время на выполнение рутинных задач.
Написание теста можно существенно упростить, если предоставить разработчику легкий доступ к справочной и отладочной информации. Поэтому каждая операция сопровождается ссылкой на ее описание в стандарте. Инструмент также позволяет просматривать сгенерированный компоновщиком код, запускать тесты на целевой машине и получать подробную информацию об ошибках, возникших на этапах генерации, компиляции и исполнения.
Возможны ситуации, когда несколько операций реализуют сходную функциональность и при этом имеют одинаковую сигнатуру, так что набор специализированных типов, которыми необходимо уточнить параметры, для них один и тот же. Разумно определить уточнения только для одной из таких операции, а затем автоматически их дублировать. Для этой цели существует инструмент импортирования, который позволяет производить поиск таких случаев сразу для всех методов класса и выбирать источник копирования из списка возможных кандидатов. Дополнительно, с помощью него можно автоматически создавать копии существующих специализированных типов с изменением типов уточняемых ими параметров.
Быстрому поиску подходящих для подстановки специализированных типов служит система их названий. Название должно нести в себе краткую информацию об ограничениях, содержащихся в типе, например, содержать начальное значение параметра, если таковое имеется, или префикс R_, если выполняется проверка возвращаемого значения. Общеупотребительные типы принято называть с помощью имен, начинающихся с Create, в этом случае инструмент импортирования в одном из режимов работы дублирует их автоматически.
Ряд специализированных типов несет в себе уточнения, имеющие смысл только для одной определенной операции. Для того чтобы облегчить поиск подходящих типов, а также предотвратить их ошибочное переиспользование, такие специализированные типы отмечаются как одноразовые и скрываются из списка доступных. Возможна и обратная ситуация, когда требуется указать один и тот же специализированный тип для всех вхождений какого-либо типа данных, за исключением единичных случаев. Такой тип объявляется общим и используется при генерации тестов по умолчанию, если явно не указан другой.
При создании инициализирующей последовательности вызовов для специализированного типа ее параметры не обязательно конкретизировать. В этом случае там, где это нужно, указывается символическая конструкция, на место которой компоновщик подставляет правильно построенный объект, возможно используя при этом какой-нибудь специализированный тип. В некоторых случаях процесс описания специализированного типа можно упростить, используя шаблоны кода для часто встречающихся случаев. Например, применяется вставка вызовов всех методов, проставляющих атрибуты объекта, названия которых в Qt начинаются на set.
в различных ситуациях остается одним
Тестирование работы программы в различных ситуациях остается одним из самых широко используемых способов демонстрации ее корректности, особенно для достаточно сложного приложения. Но все существующие методики создания тестов, обеспечивающие их полноту в соответствии с некоторыми естественными критериями, требуют весьма значительных трудозатрат.
Однако в ряде случаев, например, при тестировании же объемных интерфейсов, содержащих тысячи операций, полное и тщательное тестирование обходится слишком дорого, а иногда и вовсе не требуется для всех элементов интерфейса системы. Вместо этого проводится тестирование работоспособности, то есть проверяется, что все функции системы устойчиво работают хотя бы на простейших сценариях использования. Уже затем, для наиболее критической части интерфейса разрабатываются детальные тесты.
Именно для решения таких типов задач предназначена технология Azov [1], созданная в 2007 году в Институте системного программирования. Технология нацелена на разработку тестов работоспособности, вызывающих тестируемые операции в правильном окружении с какими-нибудь допустимыми значениями параметров, характеризующими простейшие сценарии использования этих операций. При этом она позволяет существенно автоматизировать создание теста.
Область применимости технологии включает те случаи, когда информация об интерфейсе доступна в хорошо структурированном, годном для автоматической обработки виде. При этом трудозатраты на создание одного теста существенно меньше, если тестируемый интерфейс содержит большое количество операций.
В частности технология Azov была использована при создании тестового набора для бинарных операций библиотеки Qt3, предназначенной для разработки приложений с графическим интерфейсом [4] и входящей в стандарт Linux Standard Base [2,3] (LSB). Стандарт включает в себя около 10000 методов и функций библиотеки и хранит информацию об их синтаксисе в своей базе данных.
Тестирование библиотек, написанных на языке C++, в частности Qt3 [4], является достаточно трудоемкой задачей. Поведение метода может зависеть не только от передаваемых ему параметров и глобального состояния системы, но и от состояния объекта, которому он принадлежит. Сама же библиотека графического интерфейса содержит дополнительные механизмы, которые также оказывают существенное влияние на работу методов.
Поэтому базовая методика, предлагаемая технологией Azov, должна быть дополнена набором средств, позволяющих формировать работоспособные тесты на языке C++ во всевозможных ситуациях, возникающих при тестировании элементов интерфейса, и учитывающих особенности библиотеки Qt [3], в частности механизм передачи сообщений.
Воздействия на систему требуется производить не только последовательно, но и асинхронно, т.е. подавать их из различных потоков, процессов или с разных машин. Результаты, выдаваемые системой после подачи воздействия, зависят от чередований событий внутри нее. В системах, взаимодействующих посредством удаленного вызова методов, такими событиями являются удаленные вызовы методов. Результат может зависеть от порядка вызова этих методов. Соответственно, метод оценки корректности должен обеспечивать проверку результатов для любых возможных чередований событий. Кроме того, для исчерпывающего тестирования необходимо проверить результаты для различных чередований, т.е. уже недостаточно проверить одно из возможных чередований. Эта особенность должна быть учтена при оценке полноты тестирования. Особо важную роль в распределенных системах играет задача перебора различных чередований событий. В силу того, что появление того или иного порядка событий зависит от многих факторов, таких как планирование процессов в операционной системе, управлять которыми разработчик системы не имеет возможности, нет гарантии того, что данный порядок появится в процессе воздействия на систему. Перебор только части возможных чередований оставляет возможность проявления ошибки на непроверенных чередованиях. Ошибки такого рода крайне тяжело выявлять и исправлять; даже если такая ошибка обнаружена, ее трудно повторить, так как вероятность появления порядка, на котором проявляется ошибка, может быть крайне мала. Целью данной работы является построение метода тестирования, позволяющего гарантировать, что будут проверены все различные чередования событий, приводящие к разным результатам. Задача перебора различных чередований событий традиционно решается в методах проверки моделей (model checking), которые позволяют найти последовательность событий, нарушающих данную темпоральную формулу или доказать, что такой последовательности не существует. Методы проверки моделей работают с замкнутой системой, т.е.
системой, которая не принимает входных воздействий и не выдает реакций. Для верификации других систем, например, предоставляющих программный интерфейс, требуется предоставить окружение, взаимодействующее с системой. От размеров окружения напрямую зависит количество состояний, получающихся в процессе поиска. С другой стороны, от окружения зависит качество верификации, и далеко не всегда можно ограничиться простым окружением. Методы проверки моделей обладают рядом ограничений: Взрыв количества состояний; Требование функции сравнения состояний; Требование отката. Взрыв состояний возникает из-за большого количества состояний в программных системах. Кроме того, если система не является замкнутой, то к взрыву часто приводит попытка проанализировать систему с наиболее общим окружением, которое воздействует на систему произвольным образом. Известны методы целенаправленной генерации окружений, например, [], однако данные методы не применимы для генерации окружений для распределенных систем. Для сокращения пространства перебора широко используются методы редукции частичных порядков []. Эти методы основаны на понятии зависимости событий. Зависимости можно выявить до выполнения системы или при выполнении одного из зависимых событий. Эксперименты, проведенные в [], показывают, что такие методы позволяют значительно сократить пространство перебора. Классические методы проверки моделей для осуществления поиска требуют наличия функции сравнения состояний. Для того чтобы сравнивать состояния, требуется хранить информацию об этих состояниях. Поиск без сохранения состояний (stateless search) [] позволяет осуществлять поиск для систем со сложными состояниями, которые сложно сохранять, а также для систем с большим количеством состояний. Однако поиск накладывает ограничения на систему - требуется, чтобы в ее пространстве состояний не было циклов. Широко используемой возможностью в методах поиска является возможность отката (возврата) в предшествующее состояние. Такая возможность может обеспечиваться за счет механизмов отката в реализации (например, с использованием специальной виртуальной машины []) или с помощью перевыполнения, т.е.
сброса системы в начальное состояние и повторного выполнения. Мы сформулируем задачу для случая, когда в реализации нет механизма отката и нет возможности сброса в начальное состояние. Мы будем предполагать, что вместо отката алгоритму поиска предоставляется возможность возврата в одно из состояний, которое принадлежит некоторому множеству, называемому обобщенным состоянием. Мы предполагаем, что последовательность воздействий на систему строится на основе обхода графа состояний конечного автомата [,]. Состояния автомата являются множествами исходных состояний системы и называются обобщенными состояниями. Множества выбираются, как разбиения состояний системы на классы эквивалентности. Возможность обобщенного отката реализуется за счет требования сильной связности графа состояний, необходимого для построения обхода графа. Таким образом, обобщенный откат - это путь в графе состояний, ведущий в требуемое обобщенное состояние. В следующем разделе описан пример, на котором будет продемонстрирован метод тестирования. В разделе "Алгоритм поиска" описан алгоритм, позволяющий перебирать различные порядки вызовов методов. Далее следует описание архитектуры, необходимой для его работы.
В статье описываются техники, позволяющие
В статье описываются техники, позволяющие адаптировать общий подход технологии Azov для создания тестов работоспособности для классов языка C++ и библиотеки Qt3. Большинство из таких техник могут быть использованы и в других системах.
На их основе была реализована система генерации тестов, позволившая с приемлемыми усилиями построить тестовый набор для 10000 методов и функций из библиотеки Qt3, описанных в стандарте LSB. При этом, несмотря на неполноту документации, производительность разработки тестов составила в среднем 70 операций в день на человека.
При помощи простейших тестов работоспособности удалось обнаружить порядка 10 ошибок в реализации методов. В процессе разработки тестового набора удалось обнаружить и исправить достаточно большое количество ошибок в базе данных LSB, а также пополнить ее недостающей информацией.
Таким образом, показана применимость на практике и высокая эффективность технологии Azov, пополненной набором описанных в данной работе техник.
В работе разработан метод тестирования систем, которые построены на основе компонентов, взаимодействующих с помощью удаленного вызова методов. Метод позволяет использовать удачные решения технологии UniTESK, такие как формулировка требований в виде формальных спецификаций и построение тестовой последовательности на основе обхода автоматов. Вместе с тем, метод гарантирует, что для всех тестовых воздействий, выполняемых в каждом переходе автомата, будут проверены все различные порядки вызовов методов. В работе показано, что для систем, построенных по технологии EJB 3.0, этого достаточно для получения всех возможных результатов выполнения. Тем самым, удается гарантировать корректную работу системы в соответствии со спецификацией вне зависимости от "погодных" условий, в которых работает система, таких как планирование процессов и потоков в операционной системе, а также задержки при сетевых взаимодействиях. Метод тестирования был применен к нескольким системам. Были обнаружены проблемы, которые не проявляются или проявляются редко при запусках без перебора различных порядков. Благодаря тому, что одни и те же тесты можно использовать как с перебором, так и без него, отладку тестов можно проводить без перебора, а затем проводить более тщательное тестирование, используя возможность перебора. Такой подход в проведенных экспериментах позволил значительно сократить время разработки тестов. Использование возможности перебора не для всей системы вместе с окружением целиком, а для отдельных тестовых воздействий позволило значительно сократить пространство перебора. Использование поиска без сохранения состояний позволяет сократить использование памяти. В проведенных экспериментах время работы тестов не превышало нескольких минут.
Защищенные методы
Использование защищенных методов также требует некоторых дополнительных построений. Область видимости таких методов ограничена методами класса, которому принадлежит защищенный метод, или его наследников.
При построении теста компоновщик генерирует описание класса, наследующего классу, содержащему защищенный метод. В нем определяется дополнительный общедоступный метод, являющийся оберткой защищенного. Параметры обоих методов совпадают, так что везде в тесте можно обращаться к построенному методу сгенерированного класса, подразумевая вызов требуемого защищенного метода.
Из этого правила имеется исключение, а именно случай, когда метод имеет в качестве одного из своих параметров объект защищенного типа данных. В рамках Qt, например, встречаются защищенные перечисления (protected enum). В такой ситуации цепочка инициализации объекта нужного типа генерируется компоновщиком в теле метода-обертки, а сам этот общедоступный метод имеет на один параметр меньше.
Следует также добавить, что при таком подходе защищенные in-charge конструкторы и деструкторы не могут быть протестированы, поскольку они предназначены для работы с объектом исходного класса, а вызвать их можно только из объекта наследующего класса.
Завершение теста и отложенное выполнение целевого воздействия
В подавляющем большинстве случаев приложение, осуществляющее обработку сообщений, завершает свою работу по получении некоторого внешнего сигнала. Например, приложение, имеющее графический интерфейс, в отсутствие исключительных ситуаций работает до тех пор, пока пользователь явно не даст команду на его закрытие.
Симуляция такого воздействия выходит за рамки тестирования работоспособности, поэтому завершение работы осуществляется тестом самостоятельно. При помощи сигнала singleShot класса QTimer через определенное время после запуска приложения вызывается слот quit класса QApplication, что и приводит к выходу из цикла обработки сообщений. Тесты запускаются параллельно, поэтому значительных задержек из-за относительно большого времени жизни каждого из них в самом процессе тестирования не возникает.
Таким образом, если он завершился самостоятельно в отведенные временные рамки, и при этом не возникло ошибок, то тест считается прошедшим. Если же он не завершился в нужное время, то тест уничтожается загрузчиком, и считается, что тест не прошел.
Объекты классов-наследников QDialog имеют свой собственный локальный цикл обработки сообщений. Если локальный цикл получает управление до того, как будет осуществлен вход в основной цикл, то сигнал о завершении работы, испускаемый самим приложением, не будет обработан. Возникает необходимость воздействия на диалоговое окно со стороны внешнего источника. В дополнение, некоторые методы не могут работать в основном режиме до тех пор, пока не запущен механизм обработки сообщений приложения. Поэтому возникает необходимость тестировать ряд операций уже после того, как управление передано основному циклу.
Все содержимое теста, необходимое для вызова такой целевой операции, переносится в метод-слот дополнительно сгенерированного класса. С помощью сигнала singleShot этот слот вызывается через некоторое время после запуска приложения, но до его завершения.
